Predicción del PIB subnacional en Vietnam con datos de teledetección: un enfoque de aprendizaje automático
Resumen
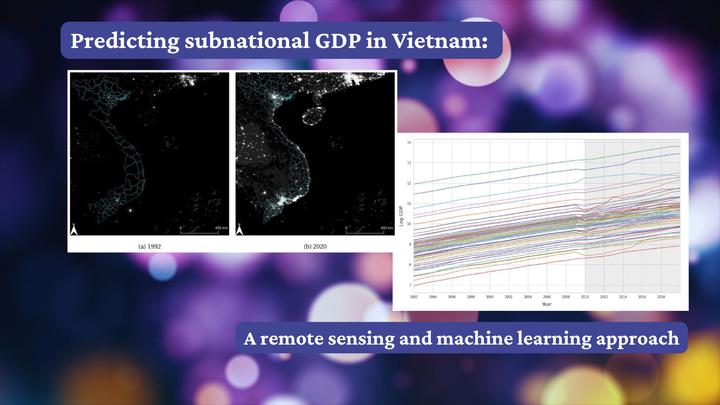
En Vietnam, los datos oficiales del Producto Interno Bruto (PIB) subnacional solo están disponibles desde 2010, lo que dificulta el análisis de la dinámica de largo plazo del desarrollo local. A partir de datos de teledetección y métodos de aprendizaje automático, construimos un indicador del PIB subnacional para las 63 provincias vietnamitas desde 1992 hasta 2009. En concreto, nos basamos en datos de luces nocturnas (NTL), tierras agrícolas y conjuntos de datos climáticos, y empleamos seis algoritmos de aprendizaje automático para construir el conjunto de datos del PIB. Comparamos la precisión de varios algoritmos de aprendizaje automático y contrastamos el PIB subnacional predicho por el algoritmo de mejor desempeño utilizando dos conjuntos de datos de luces nocturnas. Mostramos predicciones consistentes con ambos conjuntos de datos y construimos el conjunto de datos del PIB subnacional empleando los datos de NTL con la cobertura temporal más extensa. Este nuevo conjunto de datos permite a investigadores y responsables de las políticas analizar las tendencias económicas de largo plazo a nivel subnacional en Vietnam, cubriendo una carencia crítica de datos económicos históricos.
🤖 Resumen en pódcast con IA
🛰️ Introducción y contexto
- Desafío: datos limitados del PIB subnacional en Vietnam antes de 2010
- Necesidad: datos de largo plazo para el análisis del desarrollo económico
- Solución: predecir el PIB mediante teledetección y aprendizaje automático
🌌 Fuentes de datos utilizadas
- Datos oficiales del PIB (2010-2020)
- Luces nocturnas (NTL): conjuntos de datos armonizados DMSP y tipo VIIRS
- Datos de tierras agrícolas (ESA)
- Datos climáticos: temperatura y precipitación (CRU)
🧠 Enfoque de aprendizaje automático
- Seis algoritmos comparados:
- Redes neuronales artificiales (ANN)
- Random Forest (RF)
- Máquinas de vectores de soporte (SVM)
- K vecinos más cercanos (KNN)
- Regresión ridge
- eXtreme Gradient Boosting (XGBoost)
🔦 Hallazgos clave
- Predicciones consistentes entre los distintos conjuntos de datos nocturnos
- Se eligió la regresión ridge para el modelo final
- Variables importantes: la temperatura y las tierras agrícolas resultaron más influyentes que las NTL
🌍 Aplicación e importancia
- Se generaron datos del PIB para 1992-2009
- Permite un análisis detallado de largo plazo de las tendencias económicas regionales
- Ayuda a responsables de las políticas e investigadores a abordar la desigualdad y el crecimiento regionales
⚠️ Limitaciones
- Discrepancias de medición y calibración en la teledetección
- Dependencia de los valores de referencia del PIB oficial
- Desafíos de interpretabilidad de los métodos de aprendizaje automático
🚀 Líneas de investigación futuras
- Explorar conjuntos de datos de teledetección adicionales
- Estimar indicadores socioeconómicos más amplios
- Mejorar los modelos con conjuntos de datos más grandes
🎯 Conclusión
- El aprendizaje automático y la teledetección abordan eficazmente las carencias de datos subnacionales
- El nuevo conjunto de datos respalda decisiones de política económica informadas
- Método potencialmente replicable para otros países en desarrollo
Carlos Mendez
Profesor Asociado de Economía del Desarrollo
Mi investigación se centra en integrar la economía del desarrollo, la ciencia de datos espaciales y la econometría para comprender e informar mejor el proceso de desarrollo sostenible entre regiones.