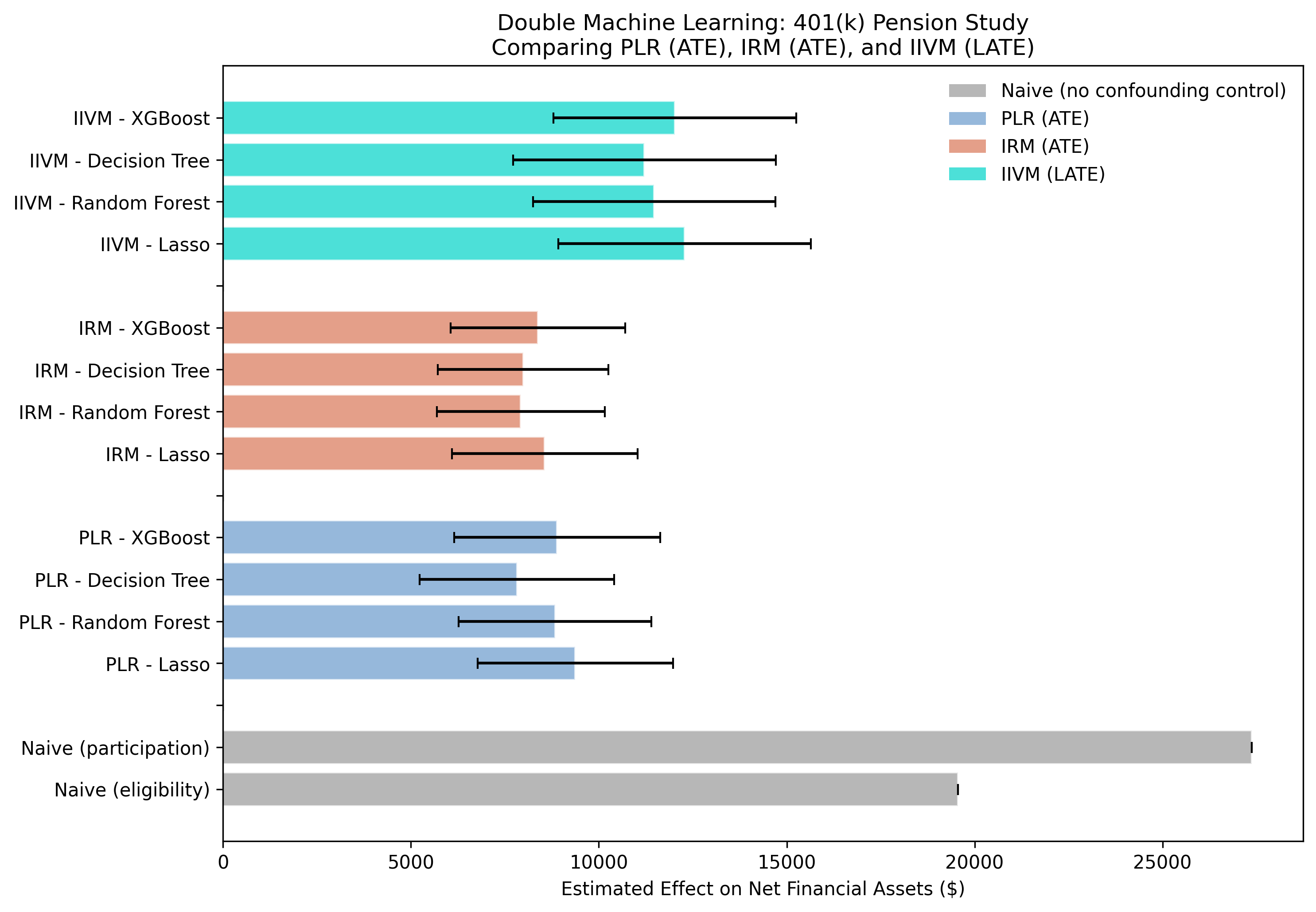
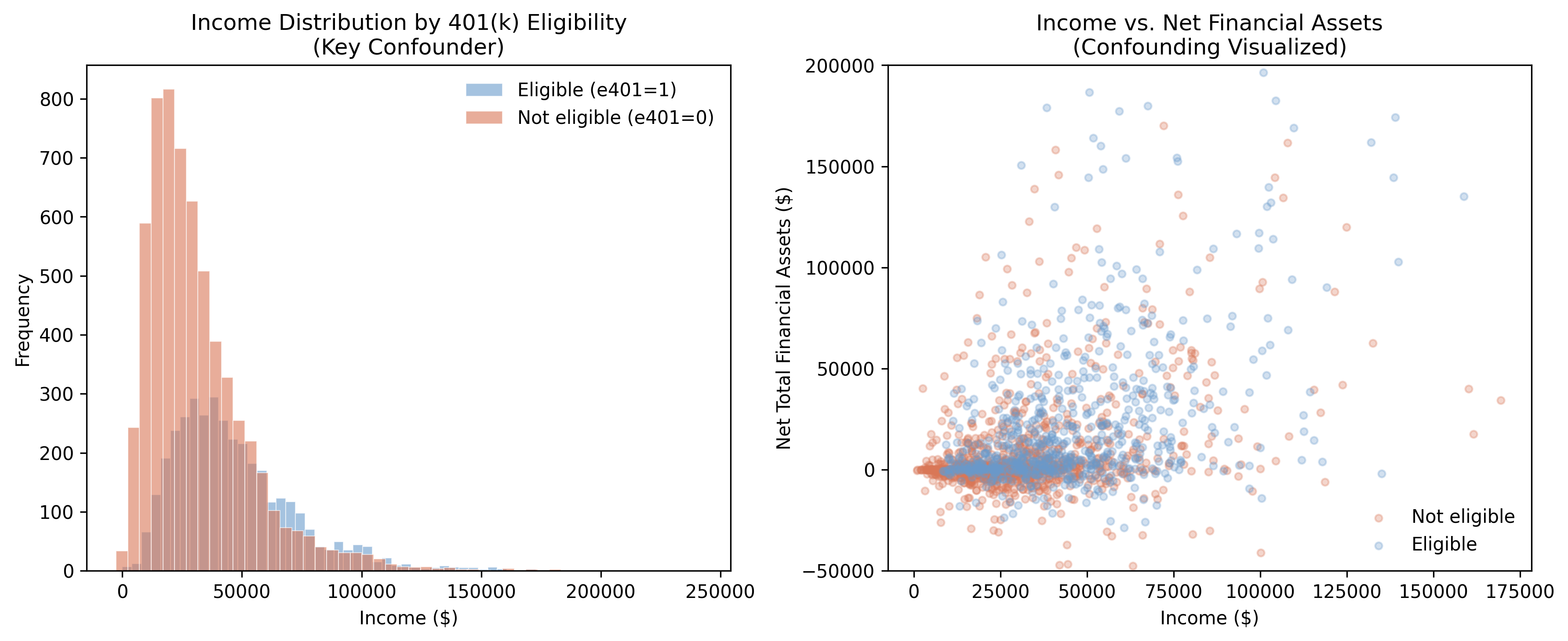
The naive $19,559 is not wrong arithmetic — it is the right gap answering the wrong question. DML’s whole job is to subtract the second term.
DML strips the confounding with two nuisance functions
\[Y = \theta_0 D + g_0(X) + \varepsilon, \qquad D = m_0(X) + V\]
\(g_0(X) = E[Y\mid X]\)
Predict savings from covariates. Residual \(\tilde Y = Y - \hat g_0(X)\) is the unexplained savings.
\(m_0(X) = E[D\mid X]\)
Predict eligibility from covariates. Residual \(\tilde D = D - \hat m_0(X)\) is the surprise eligibility.
Regress \(\tilde Y\) on \(\tilde D\): the slope is \(\hat\theta_0\). Both residuals are cleaned of confounding, so only the causal channel remains.
Two safeguards make ML-based nuisance estimation harmless
Neyman-orthogonal score
The estimating equation’s derivative w.r.t. small nuisance errors is zero at the truth. Sloppy \(\hat g_0, \hat m_0\) barely move \(\hat\theta_0\).
Cross-fitting (K-fold)
Fit \(\hat g_0, \hat m_0\) on \(K-1\) folds, predict on the held-out fold, rotate. No row is ever scored by a model that saw it.
Orthogonality kills regularization bias; cross-fitting kills overfitting bias. Together they let Lasso, forests, or XGBoost serve as nuisance learners with no harm to inference.
The doubly-robust (AIPW) score: an outcome model corrected by inverse-propensity weighting. Consistent if either\(g_0\) or \(m_0\) is right — a safety net.
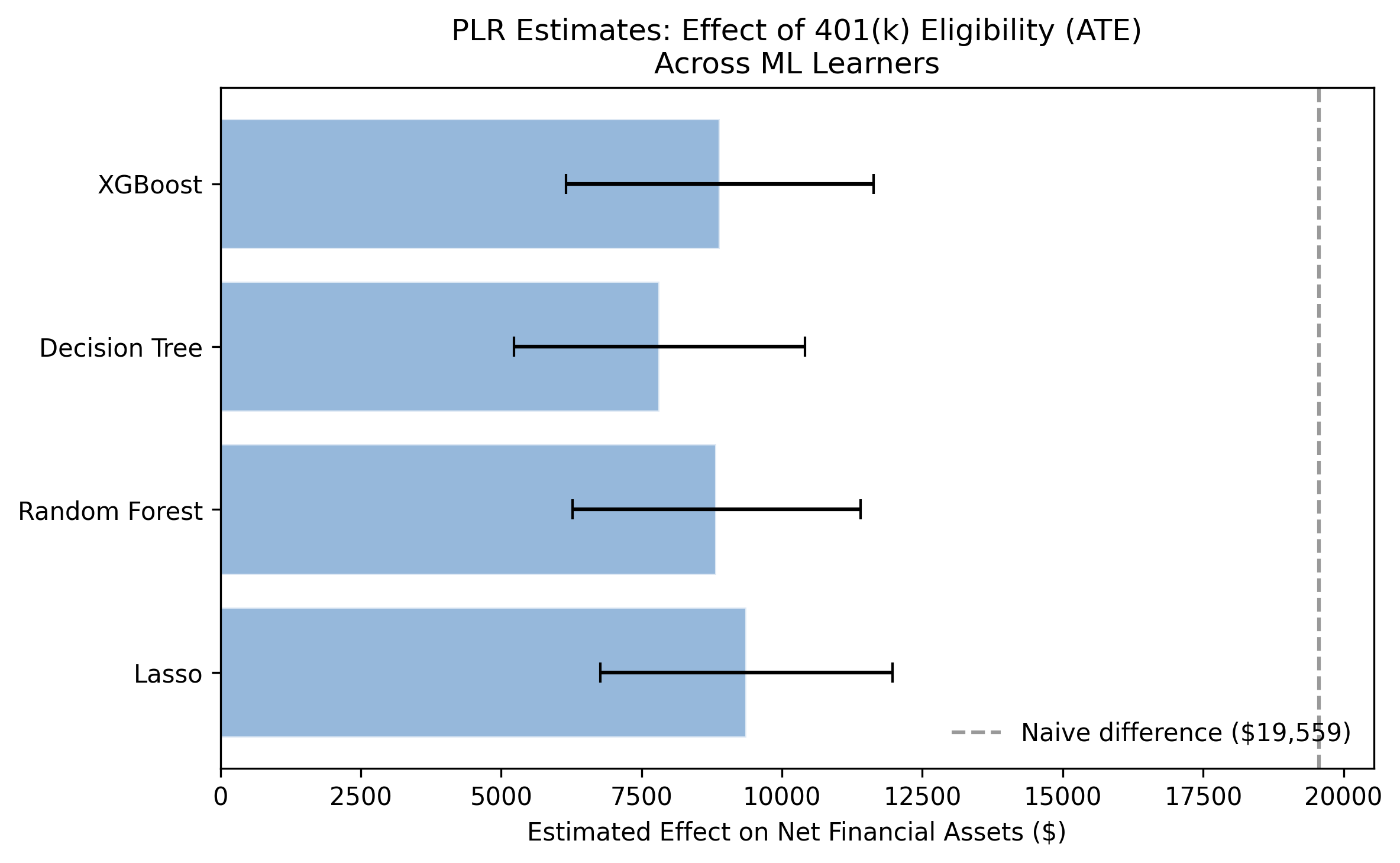
Two different recipes, same answer: PLR and IRM agree within $517
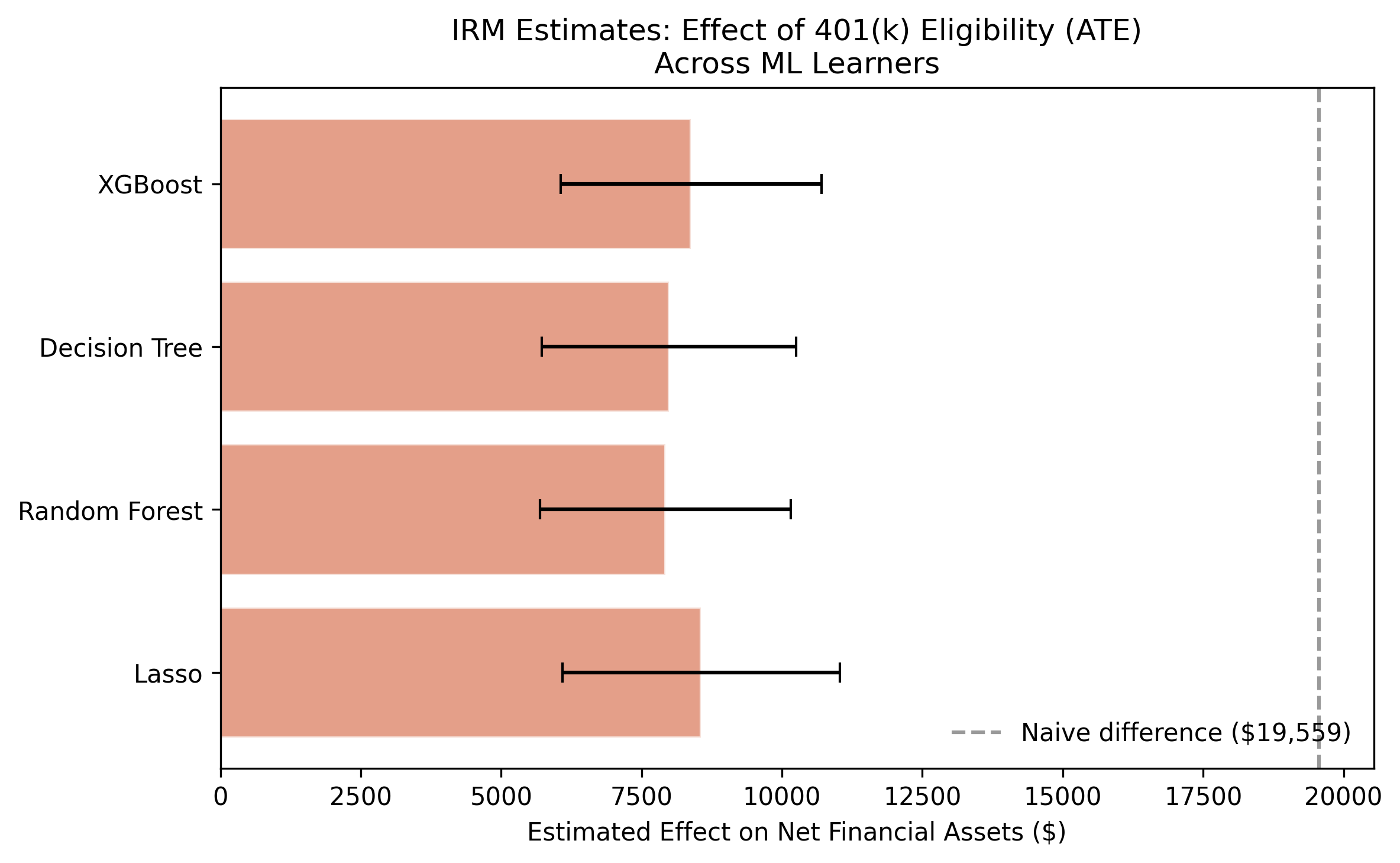
IRM estimates across four learners ($7,924–$8,559) are even tighter than PLR, with smaller standard errors.
Participation is a choice — so we instrument it with eligibility
Participation \(D\) is endogenous (financial discipline is unobserved). Eligibility \(Z\) is a nudge: it opens the door without forcing anyone through.
A Wald-type ratio: the instrument’s effect on savings, divided by its effect on participation.
The instrument only moves the compliers — so the LATE is their effect
Type
Behavior
In the LATE?
Always-takers
Participate regardless of eligibility
no
Never-takers
Never participate, even if eligible
no
Compliers
Participate because eligible
yes
Defiers
Assumed not to exist (monotonicity)
—
The LATE is the effect of participation on the marginal households a policy actually moves.
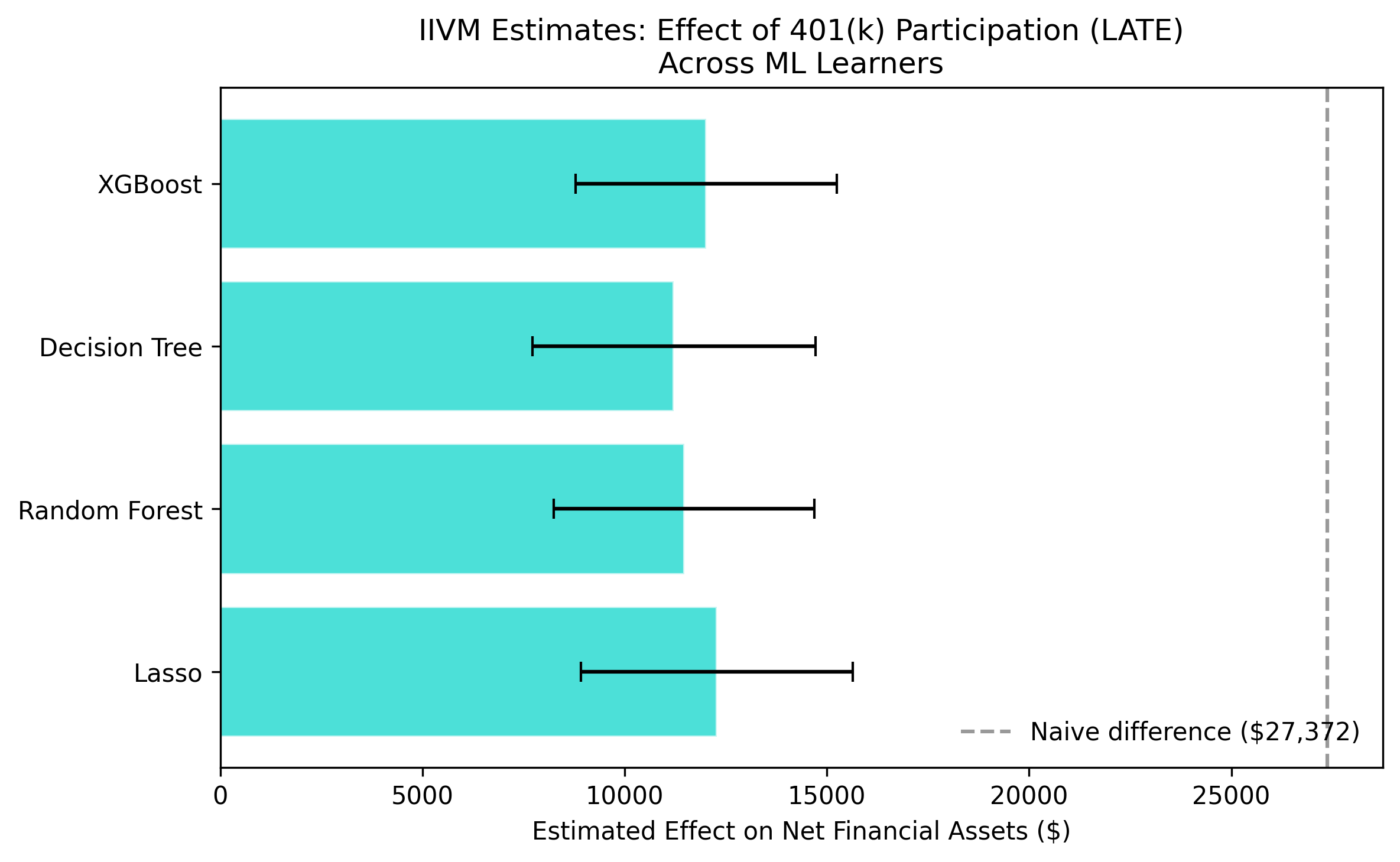
The IIVM LATE is $11,746 — larger than the ATE, by design
IIVM LATE estimates across four learners ($11,215–$12,281) sit well above the ATE band, as expected for compliers.
Estimates barely move across four learners — orthogonality at work
Whole-picture comparison: naive (gray), PLR (steel), IRM (orange), IIVM (teal). Within each model the four learners cluster tightly.
The Resolution
Act III
55% of the naive eligibility gap was pure confounding bias
55%
of the $19,559 naive gap (≈ $10,829) was income-driven bias, not causal effect — the ATE is $8,730
Eligibility genuinely raises savings — about $8,500 per household
$8,730
PLR mean ATE (IRM: $8,213); every 95% CI across two models and four learners excludes zero
For the households a policy actually moves, the effect is $12,000
$11,746
IIVM LATE on compliers — the marginal participants an eligibility expansion targets
Does DML make this causal? No — two assumptions still carry the weight
Objection. Letting an ML model pick the controls can’t manufacture identification.
Response. Correct. DML disciplines estimation, not identification.
The ATE needs conditional exogeneity; the LATE adds instrument validity and monotonicity.
Separate “is the effect real?” from “for whom?” — and let cross-fitting do the rest.