Causal Machine Learning and the Resource Curse
Heterogeneous treatment effects with EconML’s CausalForestDML
Nagoya University (GSID)
July 8, 2026
The treatment is brutally imbalanced — 85% of district-years never mine
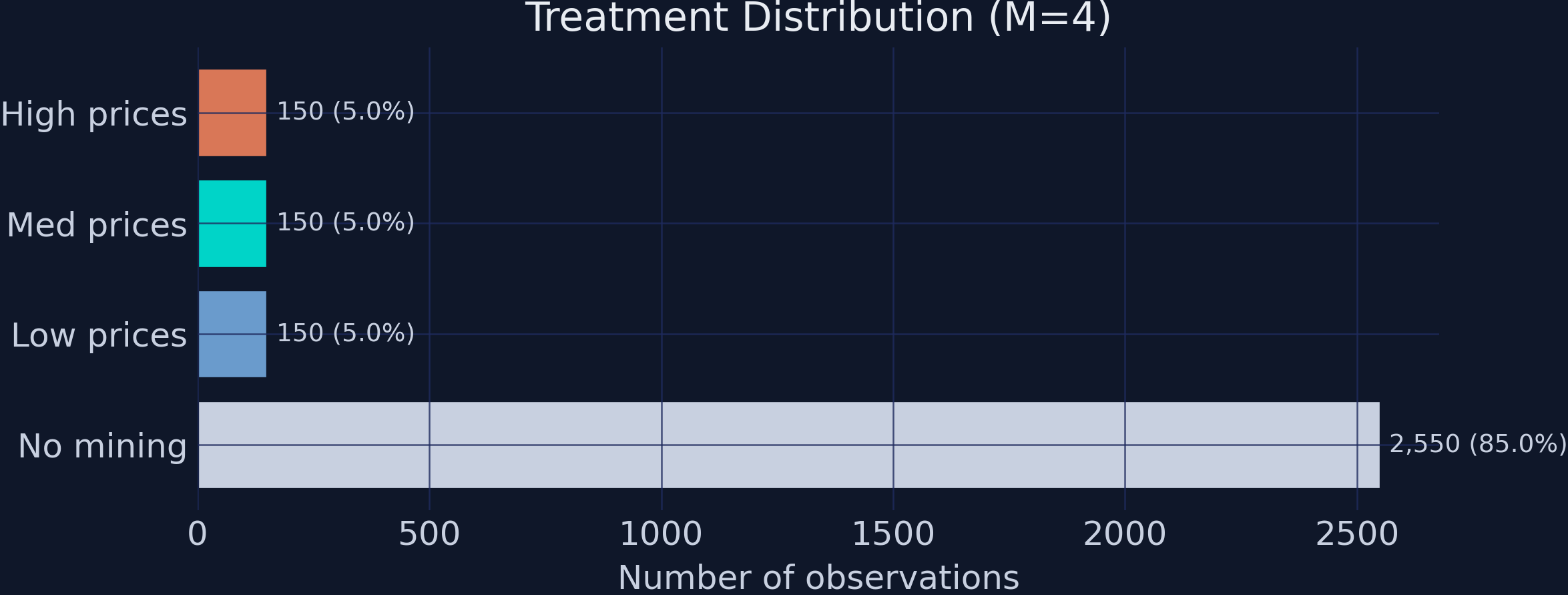
Treatment distribution. 2,550 control observations but only 150 per mining level — within-mining contrasts lean on just 300 rows.
Institutions amplify the mining effect — stronger constraints, larger payoff
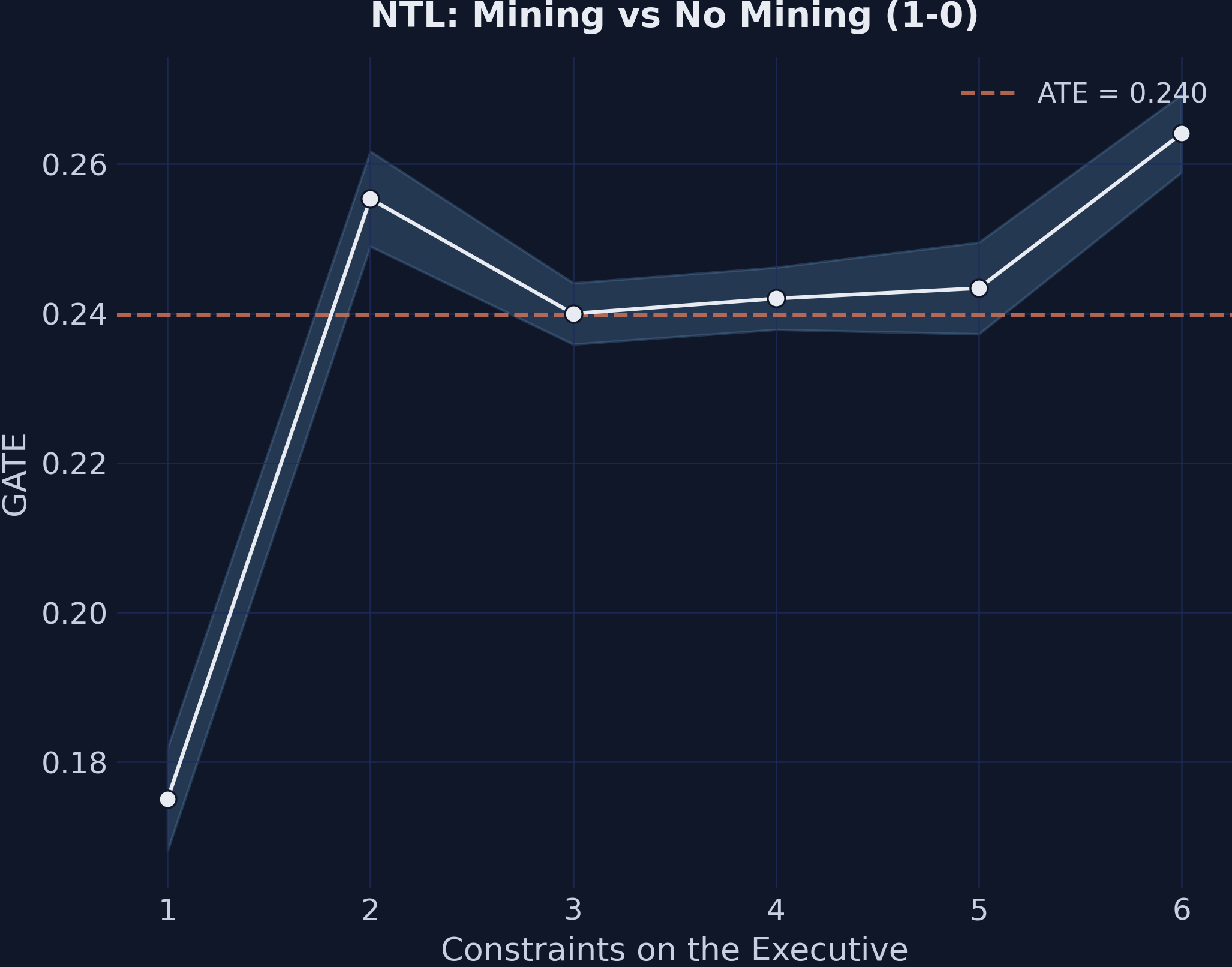
GATEs for the mining effect (1-0) by executive constraints. The upward slope: stronger institutions amplify the economic benefit of mining.
The price effect is flat across institutions — a non-finding that is the finding
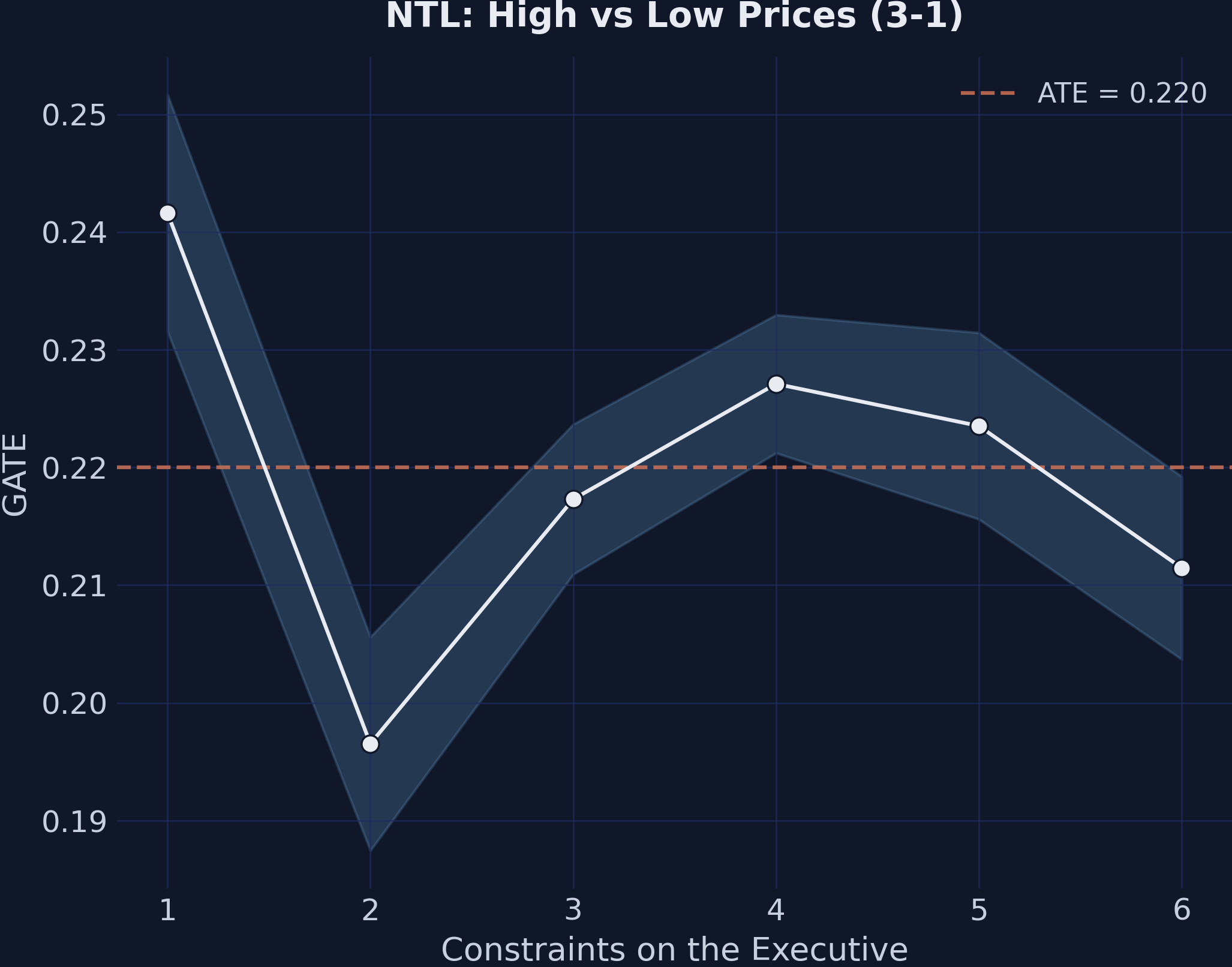
GATEs for the price effect (3-1) by executive constraints. The flat line: institutions do not moderate price effects (range 0.045).
Beware: the most “important” features are not the moderators
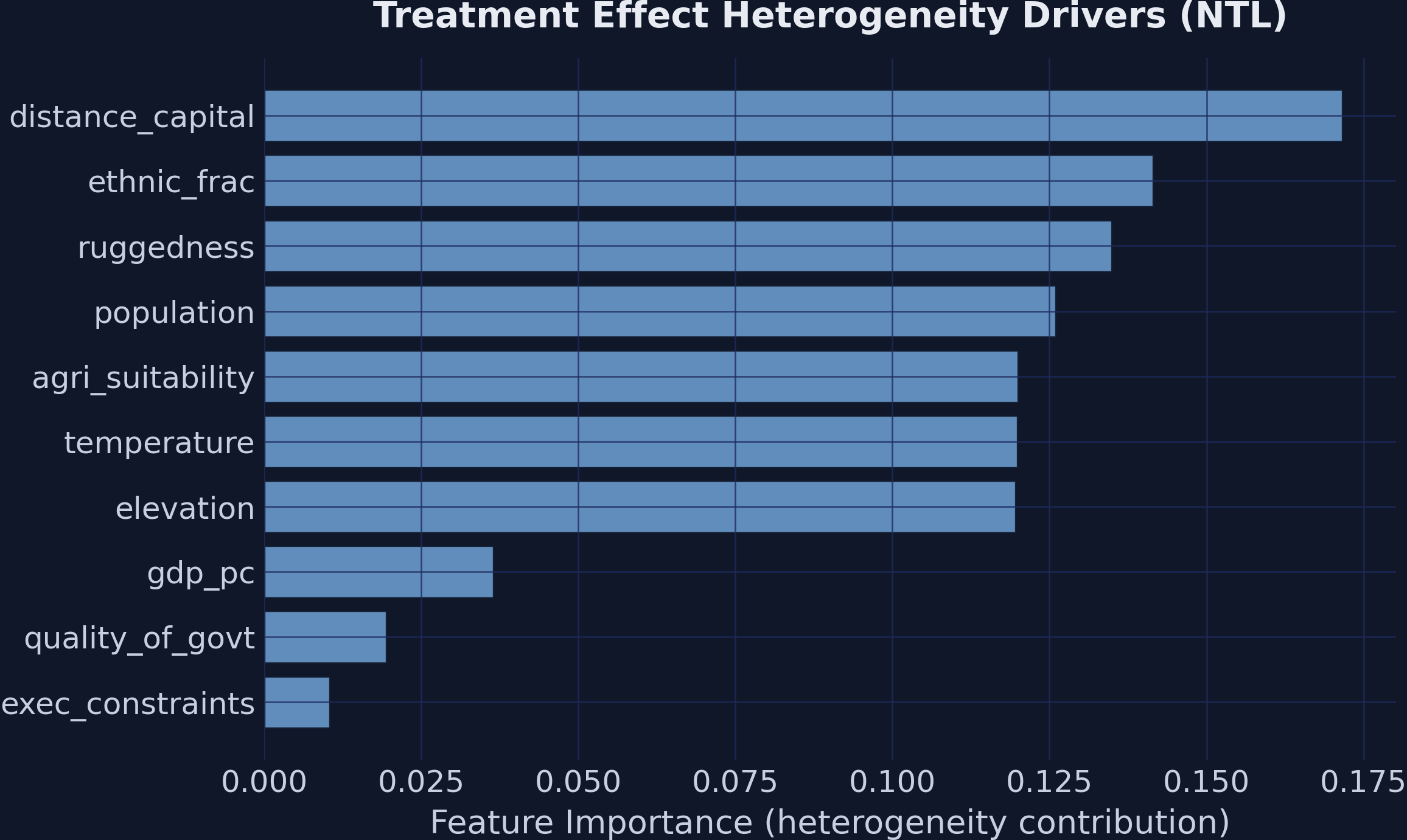
Feature importance for heterogeneity. Geographic variables dominate split frequency, yet institutions are the true moderators.
A depth-2 tree turns the forest’s heterogeneity into a story you can tell aloud
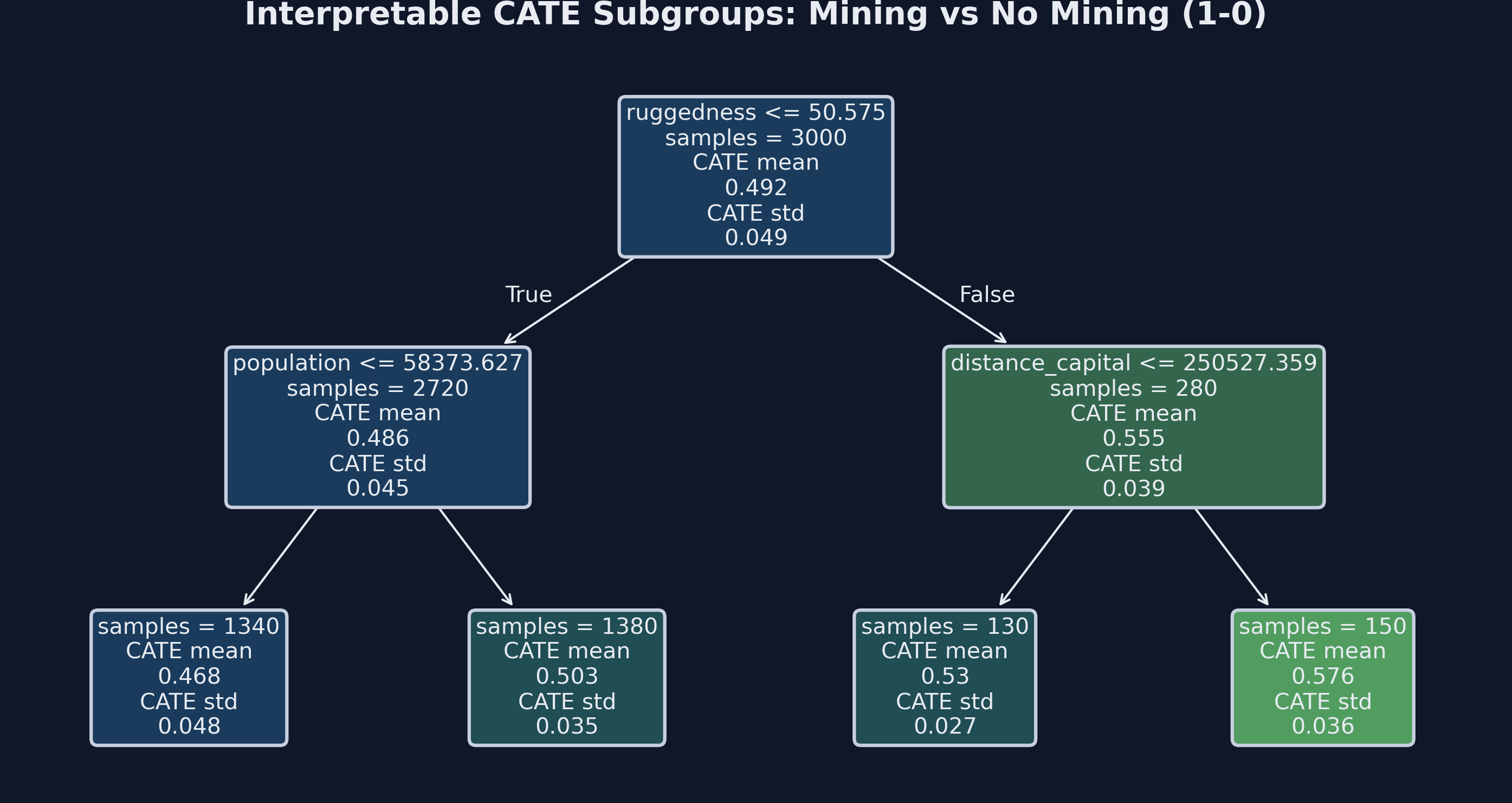
Depth-2 CATE interpreter for the mining effect. Each leaf reports the mean estimated CATE for the subgroup defined by the splits above it.