There is only one Kansas, and it took the treatment
In May 2012 Kansas enacted one of the largest state tax cuts in U.S. history — Gov. Brownback called it “a real-live experiment” in supply-side growth.
To judge it we need the Kansas that didn’t cut taxes. That Kansas does not exist. Where do we get the counterfactual?
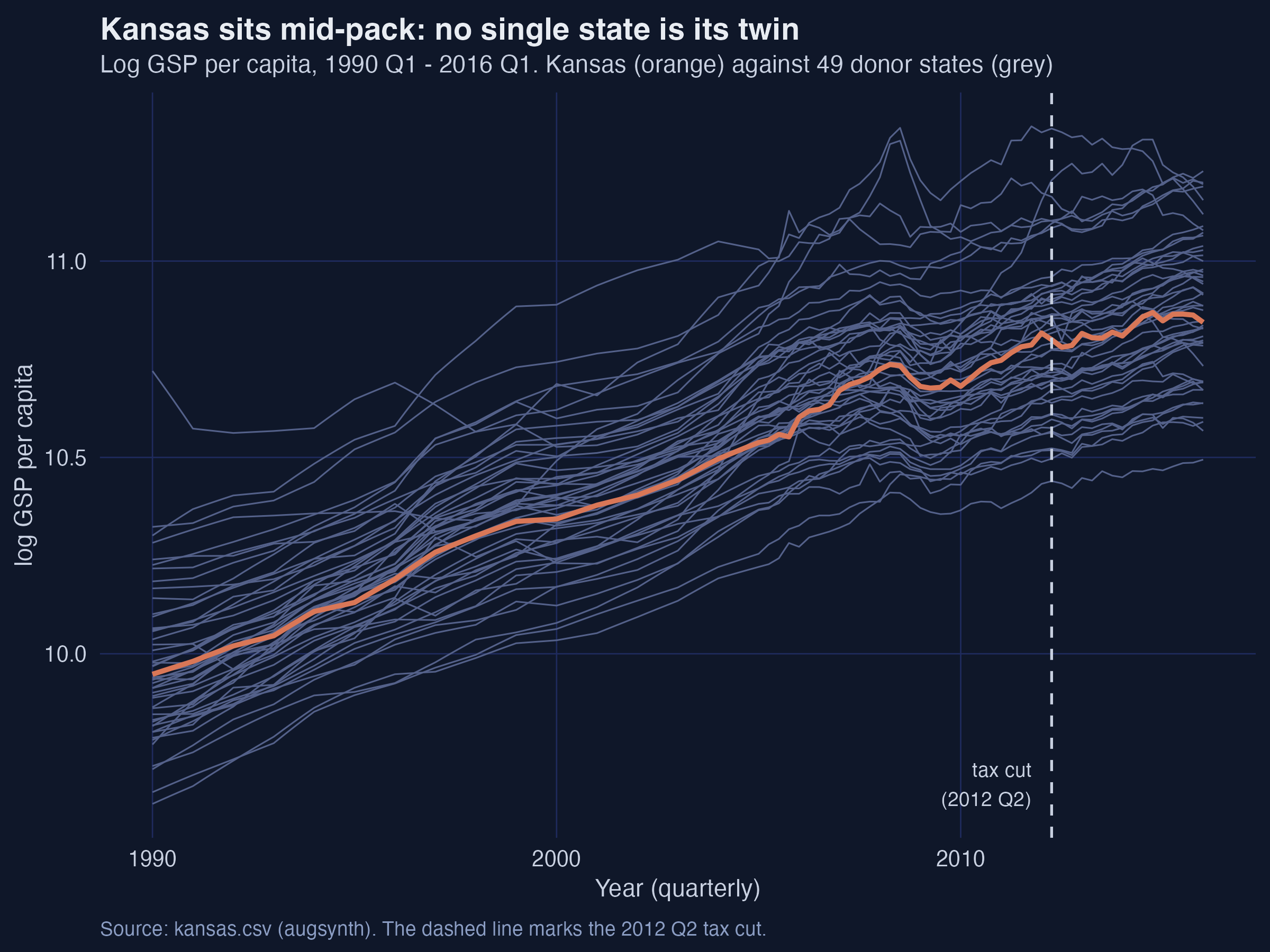
No single state is a Kansas twin — so we must build one
Log GDP per capita, Kansas (orange) vs the 49 donor states (grey), 1990–2016. The dashed line marks the 2012 Q2 tax cut.
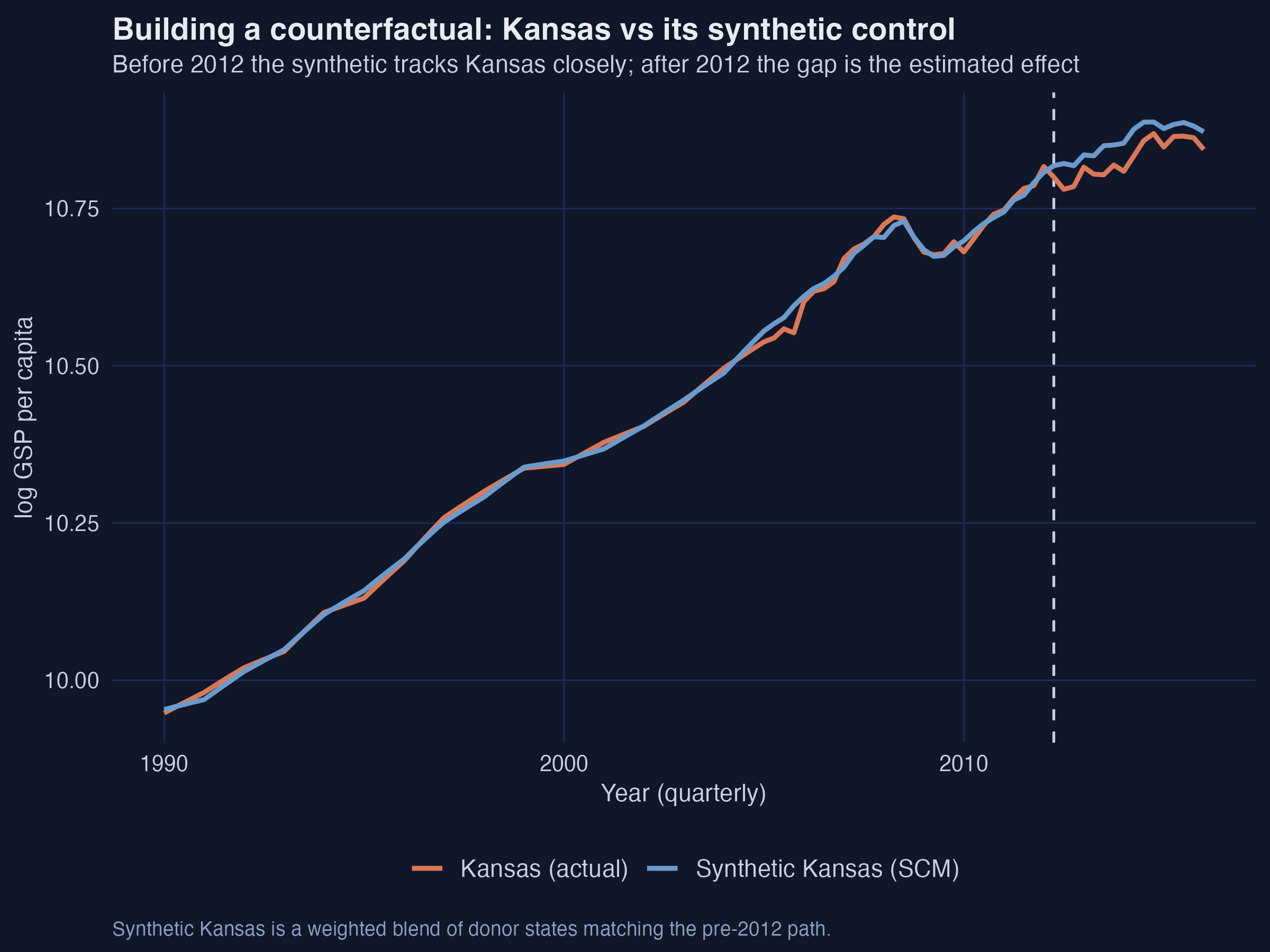
After 2012 Kansas slips below the synthetic control we build for it
Actual Kansas (orange) vs synthetic Kansas (blue): nearly identical before 2012, a widening wedge afterward.
Where we’re going
The lab: a balanced 50-state, 105-quarter panel of log GDP per capita
Classic SCM — an interpretable convex recipe with one fatal flaw
Ridge ASCM — estimate the leftover bias, then subtract it
Inference four ways: is the gap bigger than chance?
The Investigation
Act II
The lab: 50 states × 105 quarters, with 89 quarters before the cut
Outcome — lngdpcapita, log gross state product per capita
Treated unit — Kansas (FIPS 20), treated from 2012 Q2 onward
Donor pool — the 49 other states; none cut taxes like Kansas
The 89-quarter pre-period is the engine of inference — long enough to make the conformal and jackknife procedures informative, and to give every donor a credible placebo path.
SCM builds the counterfactual from a convex blend of donors
The estimand is the ATT — Kansas’s actual outcome minus its synthetic, after treatment. SCM picks weights on the simplex (non-negative, summing to one):
The two rules — non-negative, sum to one — keep the synthetic interpretable and forbid wild extrapolation. The per-quarter effect is then \(\hat{\tau}_t = Y_{1t} - \sum_i \hat{\gamma}_i^{scm} Y_{it}\).
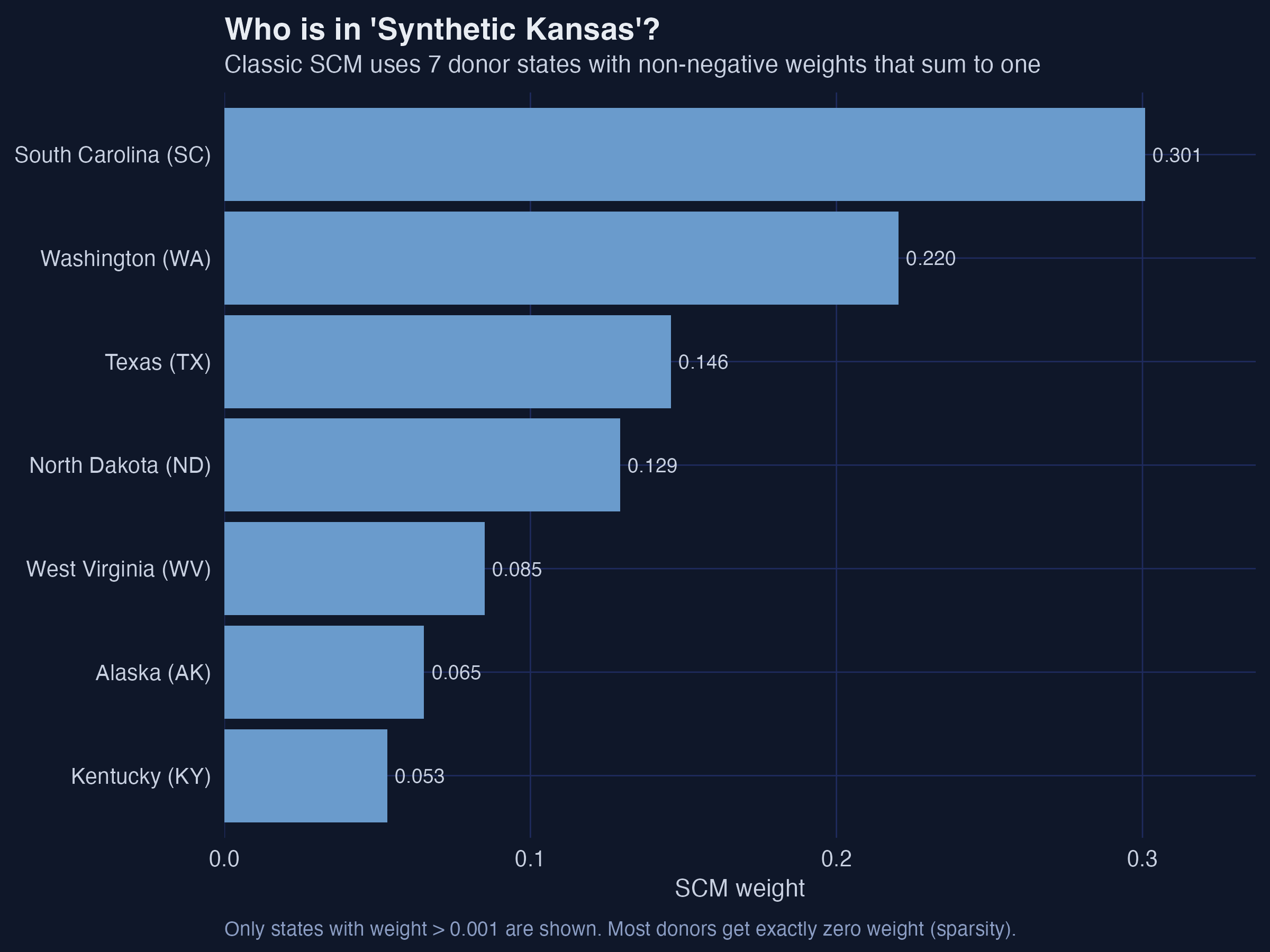
SCM’s virtue is sparsity: 7 donors, 42 zeros, a recipe you can name
Donor weights for synthetic Kansas: South Carolina 0.30, Washington 0.22, Texas 0.15, North Dakota 0.13, West Virginia 0.09, Alaska 0.07, Kentucky 0.05.
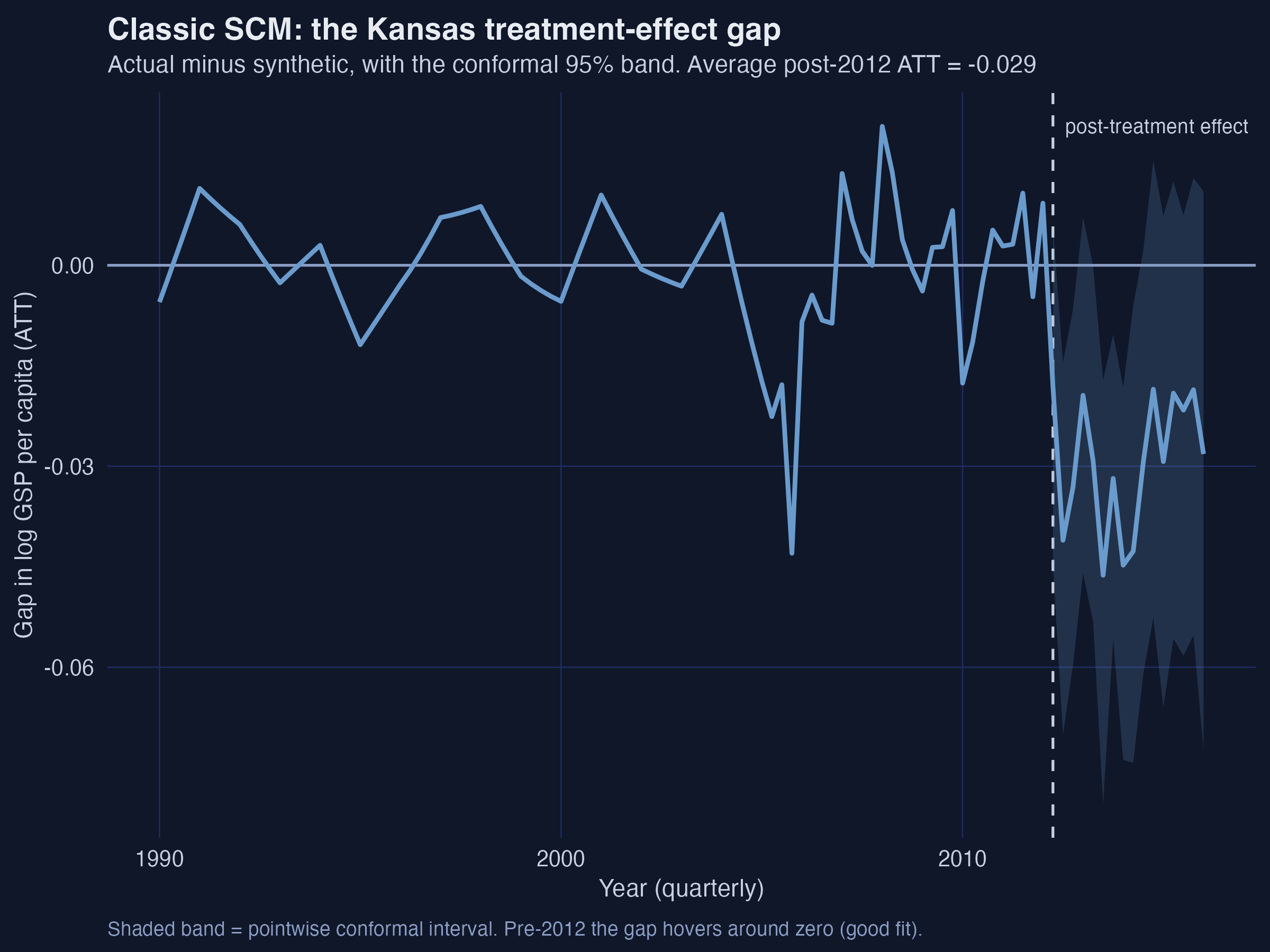
Classic SCM lands at −0.029, but the mid-2000s pre-fit leaks bias
The classic-SCM gap (actual − synthetic) with its conformal 95% band: near zero before 2012, persistently negative afterward.
A −0.043 pre-treatment gap is bias hiding in plain sight
−0.043
worst pre-2012 quarter (2005 Q4) — as large as the effect itself, where the true effect is zero
ASCM estimates the leftover bias with an outcome model, then subtracts it
Start from the plain SCM counterfactual (first term); add the imbalance the ridge outcome model \(\hat{m}\) predicts (the parenthesis). If the SCM fit were perfect, the correction vanishes — augmentation only acts where there is imbalance to fix.
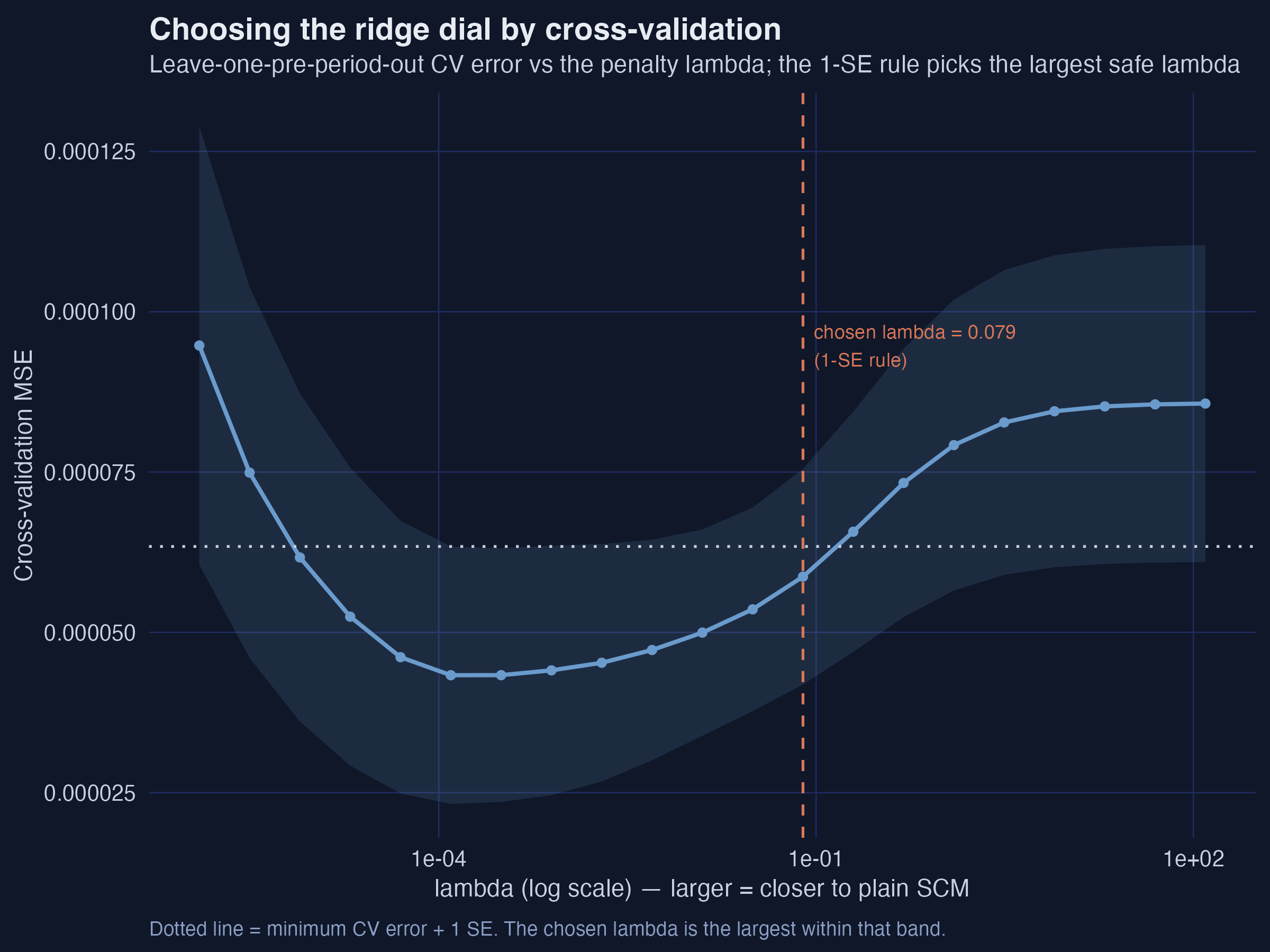
Cross-validation picks the penalty — the 1-SE rule keeps it conservative
Cross-validation MSE against the ridge penalty \(\lambda\) (log scale). The chosen \(\lambda = 0.079\) is the largest within one SE of the minimum.
Augmentation deepens the effect to −0.040 and the bias is a third of it
−0.040
Ridge ASCM ATT (≈ −3.9%) · L2 falls 0.083 → 0.062 · estimated bias 0.011 ≈ ⅓ of the effect
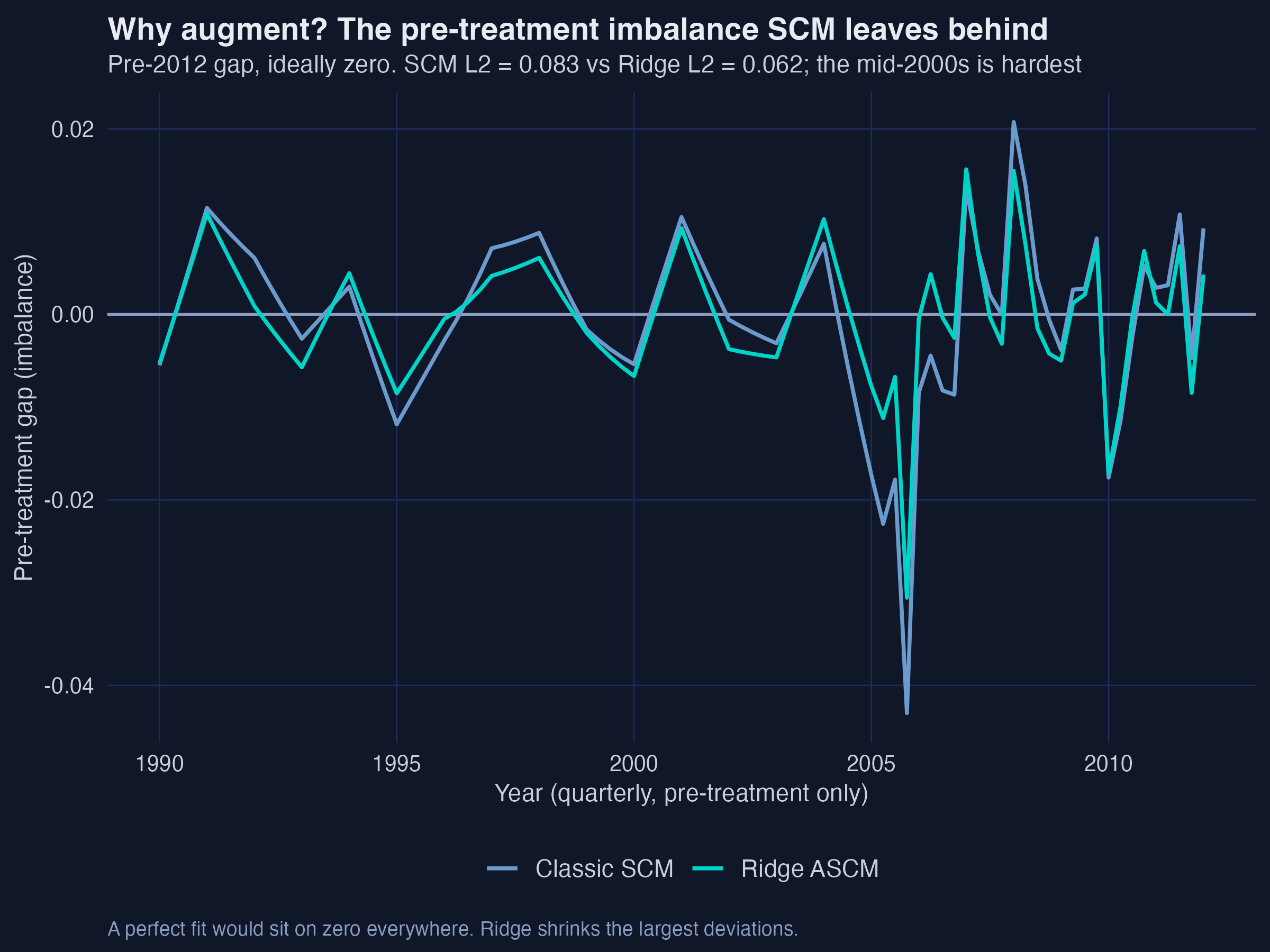
Ridge spent its budget exactly where SCM was failing — the mid-2000s
Pre-treatment imbalance, SCM vs Ridge ASCM. Ridge shrinks the largest deviations, pulling the 2005 Q4 gap from −0.043 to −0.031.
A better fit, but the same recipe: the weights barely move
Classic SCM
convex weights only
7 donors, 42 exact zeros
L2 imbalance 0.083
ATT \(-0.029\)
Ridge ASCM
penalized weights leave the simplex
21 small negative weights
L2 imbalance 0.062
ATT \(-0.040\) · RMS weight change just 0.015
Six lines fit Ridge ASCM in R — the formula mini-language does the work
syn <-augsynth(lngdpcapita ~ treated, fips, year_qtr, kansas,progfunc ="None", scm =TRUE) # classic SCMasyn <-augsynth(lngdpcapita ~ treated, fips, year_qtr, kansas,progfunc ="Ridge", scm =TRUE) # CV picks lambdasummary(asyn) # avg ATT, L2 imbalance, est. biasplot(asyn) # gap with a conformal 95% band
Add six covariates and balance gets near-perfect; the effect deepens to −0.061
Specification
ATT (log pts)
≈ % effect
Pre-fit L2
Est. bias
Classic SCM
−0.029
−2.9%
0.083
—
Ridge ASCM
−0.040
−3.9%
0.062
0.011
Covariate ASCM
−0.061
−5.9%
0.054
0.027
The more we de-bias and balance, the larger the measured damage — the un-augmented SCM number is the conservative one.
The Resolution
Act III
The headline: a persistent ~3.9% GDP shortfall, de-biased
−0.040
Ridge ASCM ATT · strongest in 2013–2014 · robust in sign across all five specifications
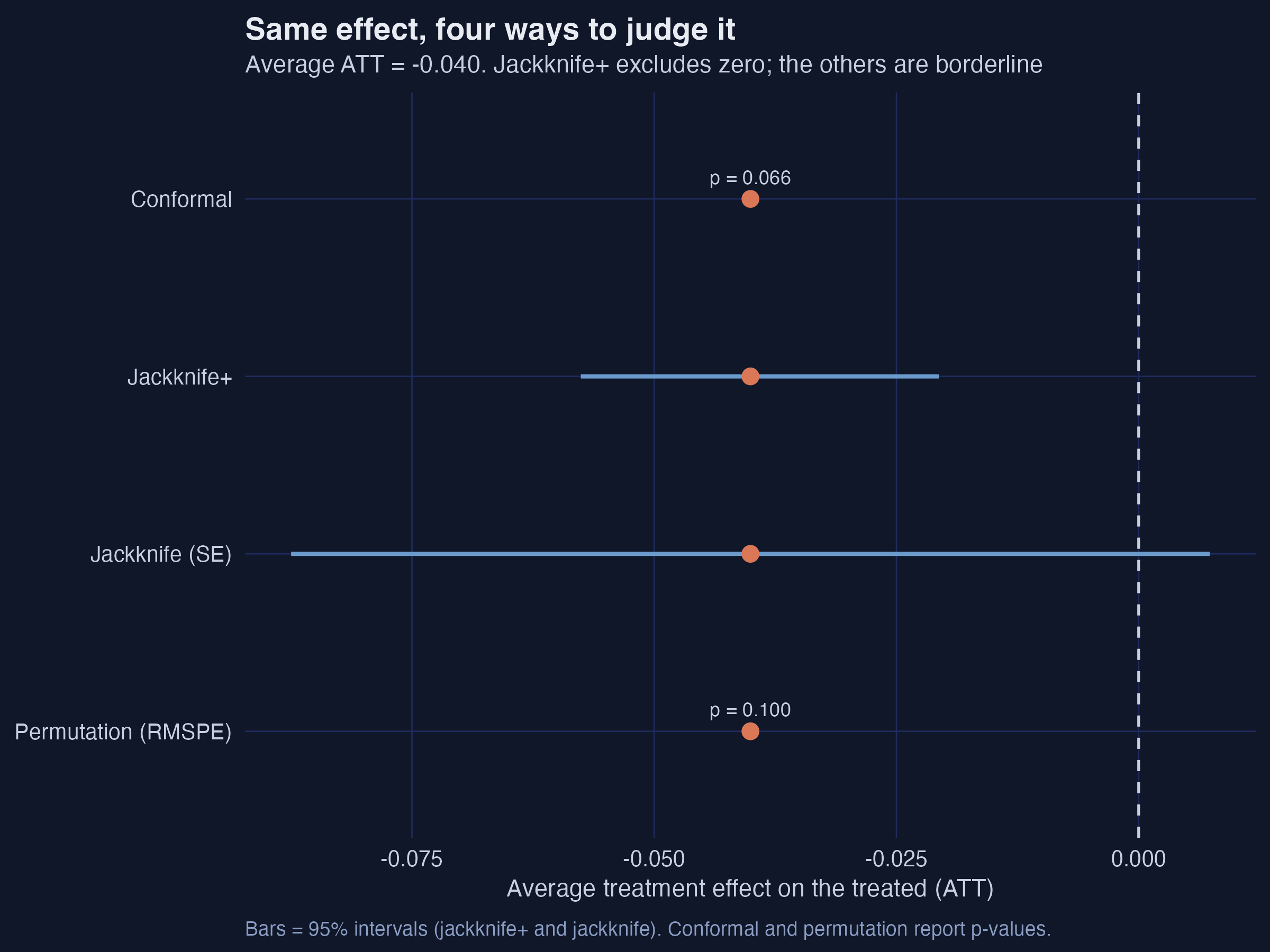
Same point estimate, four verdicts: significance depends on the question
Four inference methods side by side. All share the −0.040 estimate; jackknife+ excludes zero, while conformal (p = 0.066), permutation (p = 0.10), and the leave-one-donor jackknife are borderline.
Does LASSO-style selection make this causal? No — the assumptions still carry it
Objection. Augmentation just de-biases the fit; it can’t manufacture identification.
Response. Correct. ASCM disciplines selection; it cannot manufacture identification. The ATT still needs a credible donor blend, no anticipation, no interference — and the gap mixes the tax cut with the drought and aerospace shocks. Suggestive-to-moderate evidence, not a knock-down result.
The better we make the comparison, the worse the tax cut looks — and never good.