Three Methods for Robust Variable Selection
BMA, LASSO, and WALS — graded against a known answer key
Nagoya University (GSID)
July 8, 2026
We built an answer key: 7 true predictors, 5 pure-noise impostors
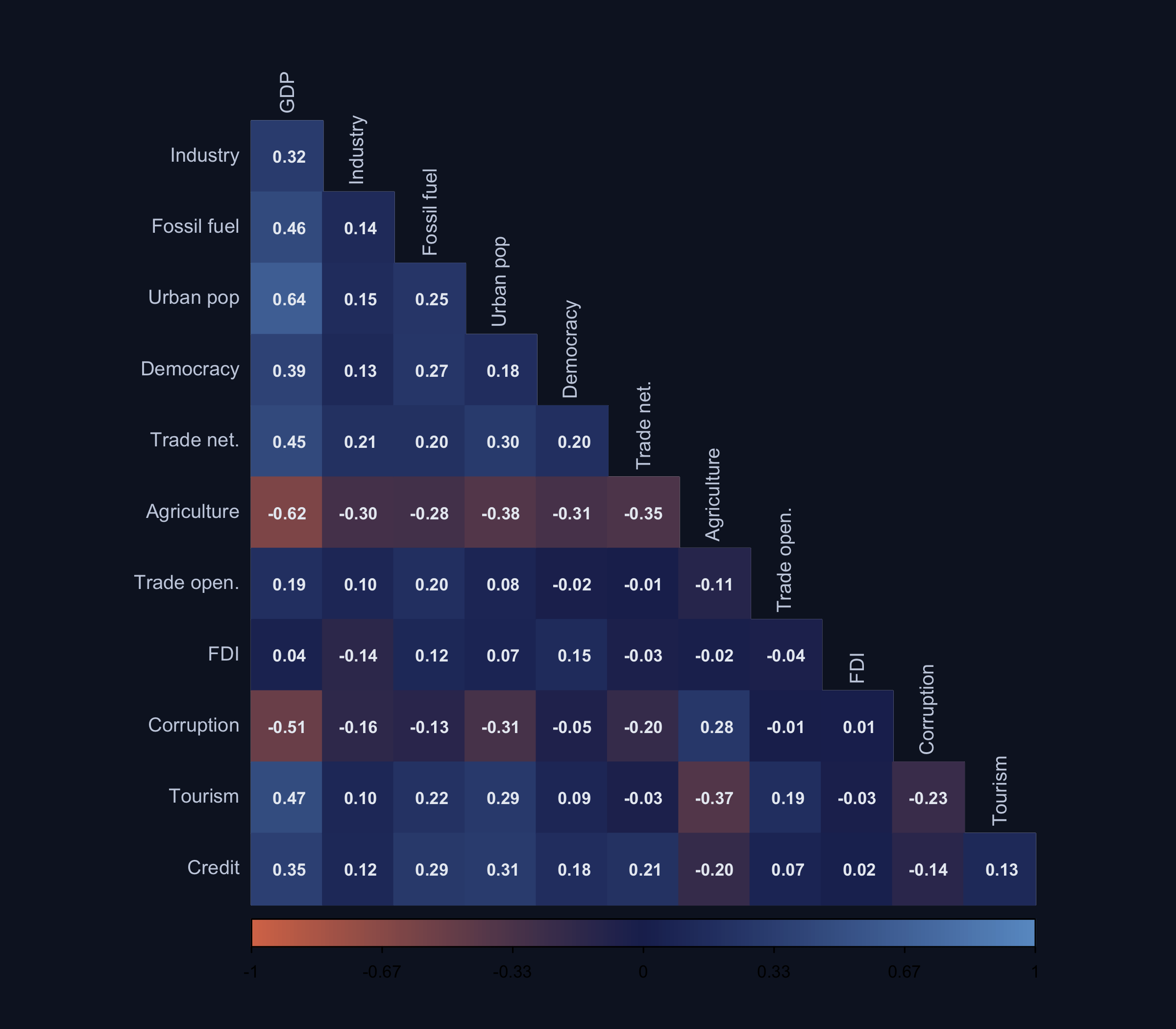
Noise variables (trade openness, tourism, credit) are deliberately correlated with GDP and other true predictors — the multicollinearity that makes naive OLS unreliable.
BMA flags four robust drivers and zero false positives
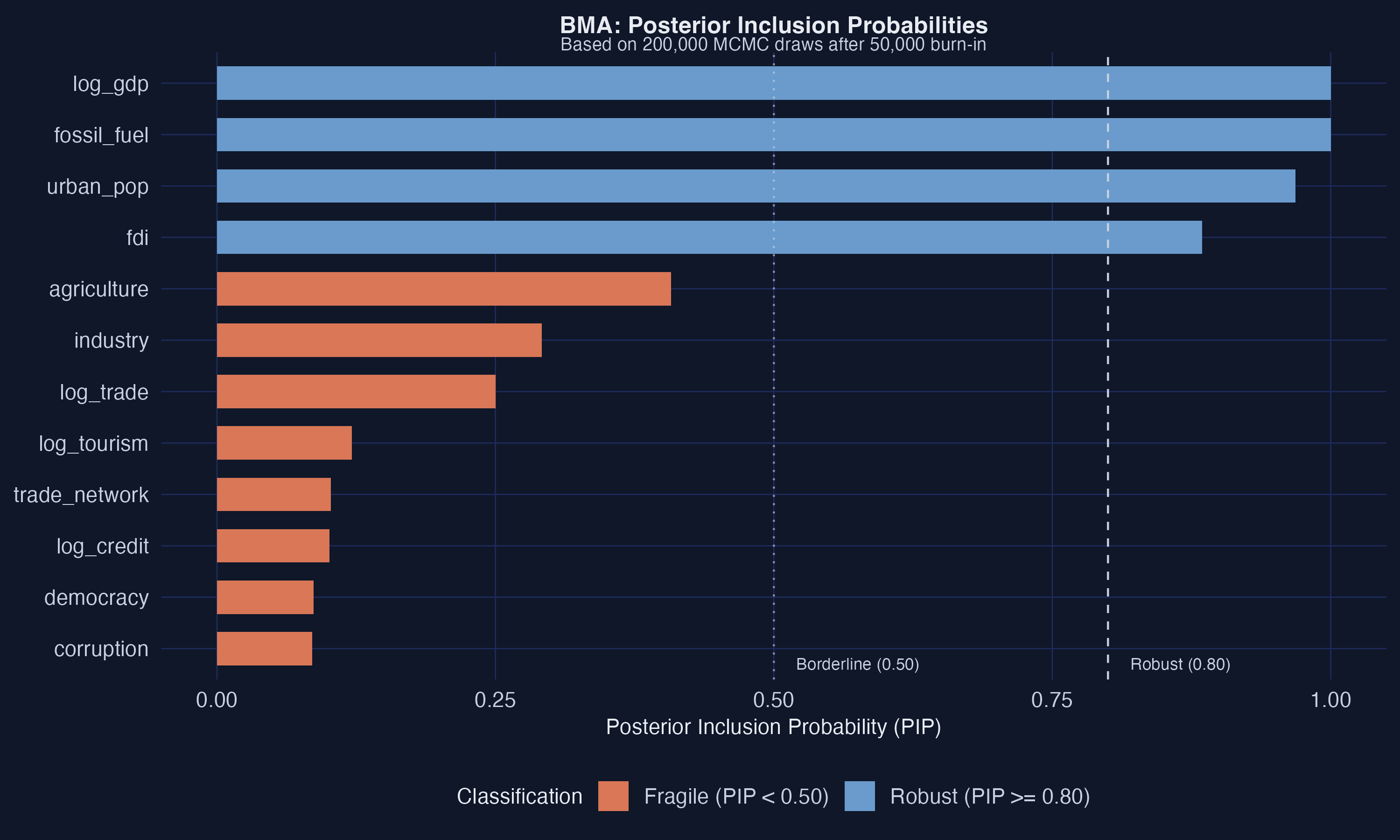
GDP (PIP = 1.00), trade network (0.986), fossil fuel (0.948), industry (0.841) clear the 0.80 line; all five noise variables sit below 0.15.
The top models agree: the same four variables, every time
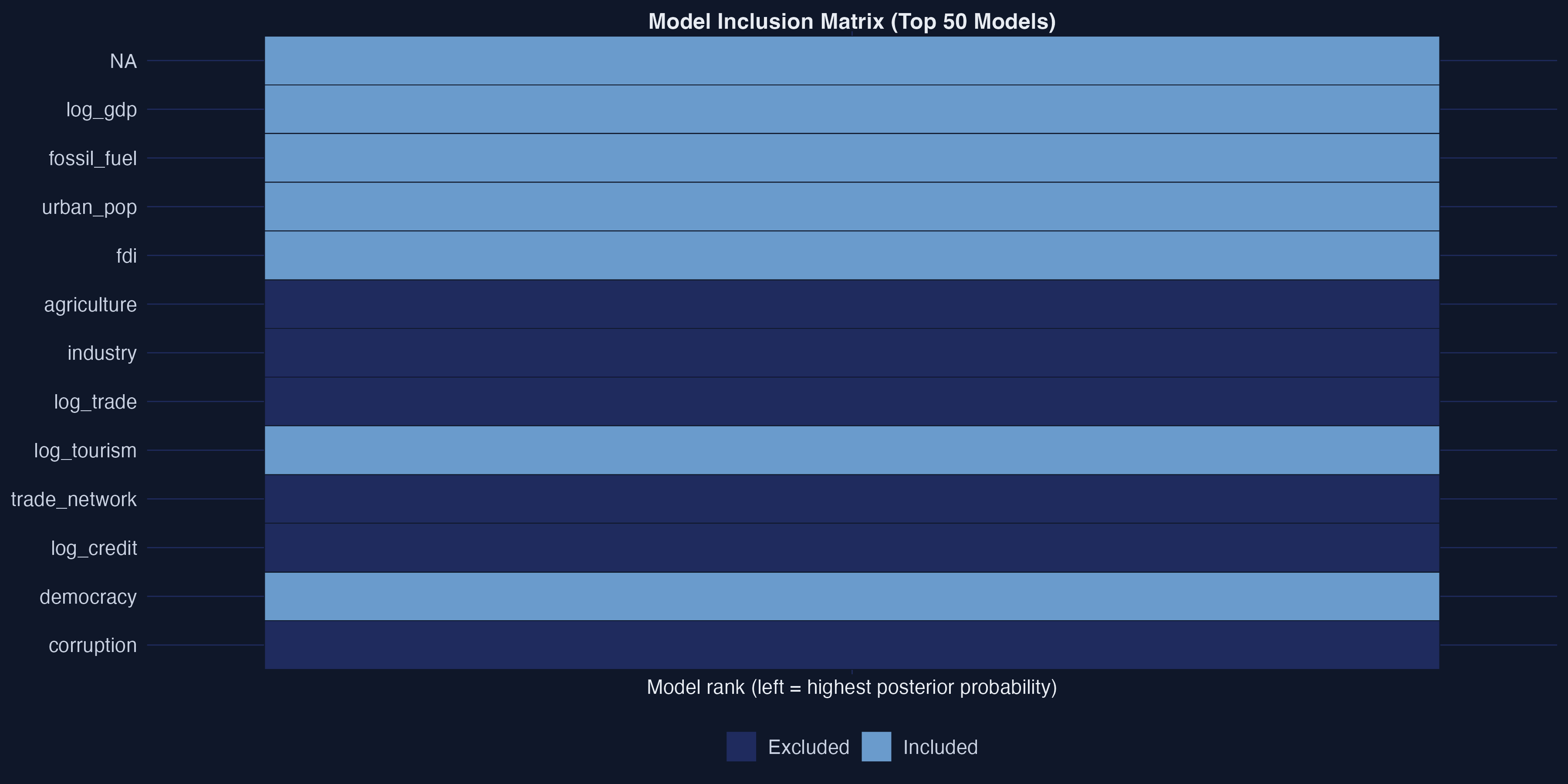
Variable-inclusion map of the top 100 models. Column width = posterior probability; blue = positive coefficient, gray = excluded. The core four form solid bands across the whole axis.
LASSO trades a little bias for a large cut in variance
\[\text{MSE}=\text{Bias}^2+\text{Variance}+\text{Irreducible noise}\]
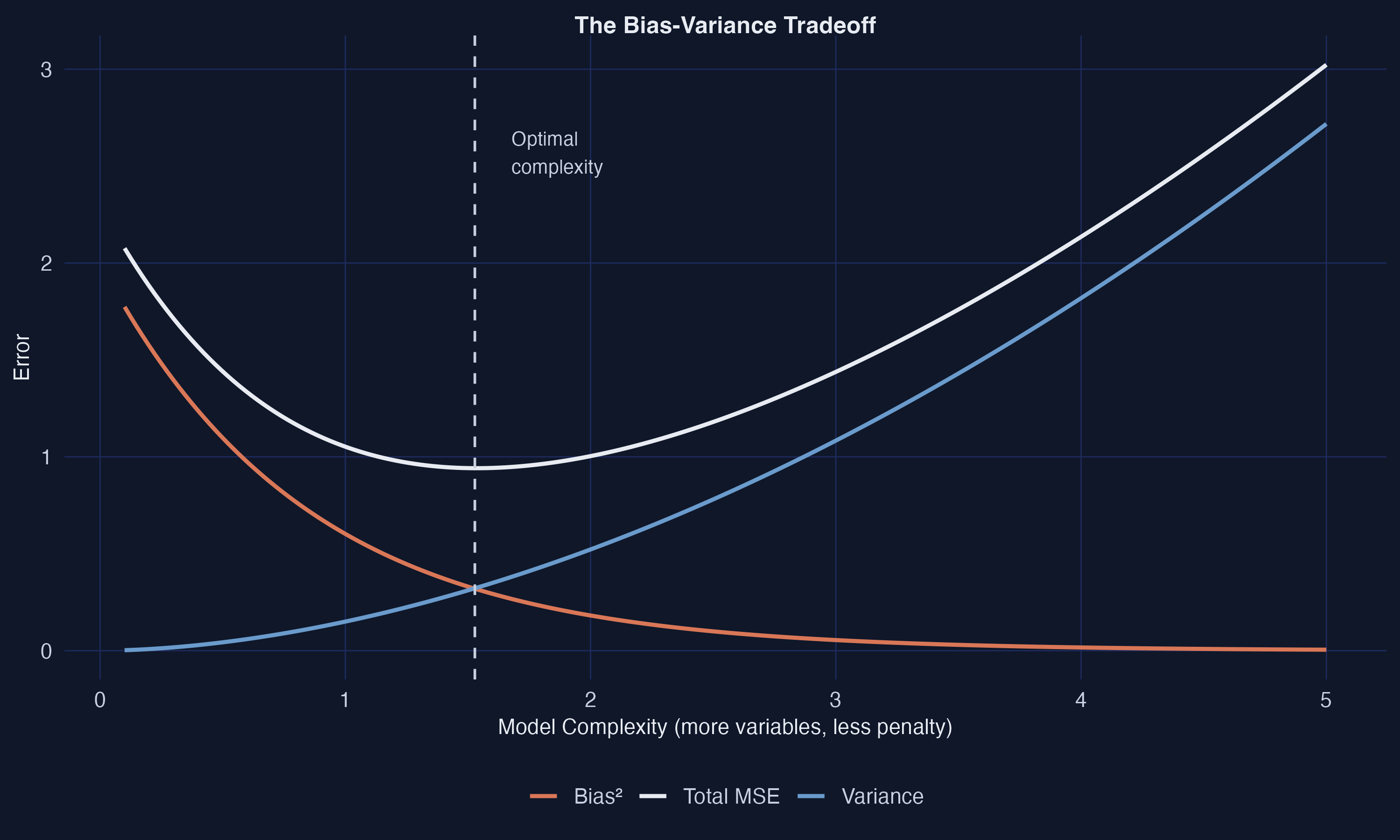
As complexity rises, bias falls but variance explodes. The optimal model lives in between — exactly where regularized methods operate.
The L1 diamond has corners — that is why LASSO selects
\[\hat\beta_{\text{LASSO}}=\arg\min_\beta\ \frac{1}{2n}\|y-X\beta\|^2+\lambda\sum_{j=1}^{p}|\beta_j|\]
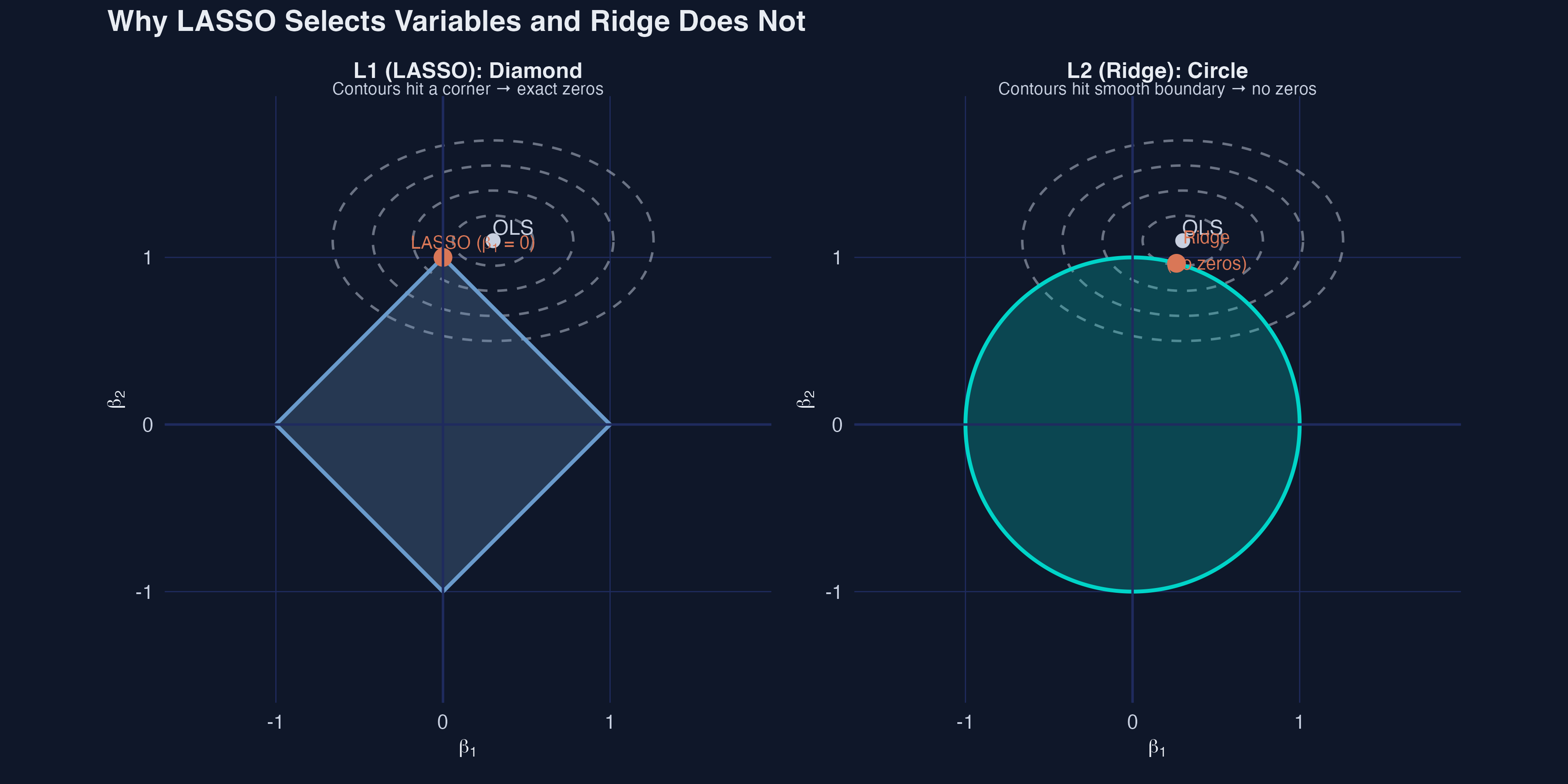
L1 contours hit a corner (a coefficient is set to exactly zero); L2 (Ridge) hits a smooth circle and never reaches zero.
Noise dies first; GDP is the last variable standing
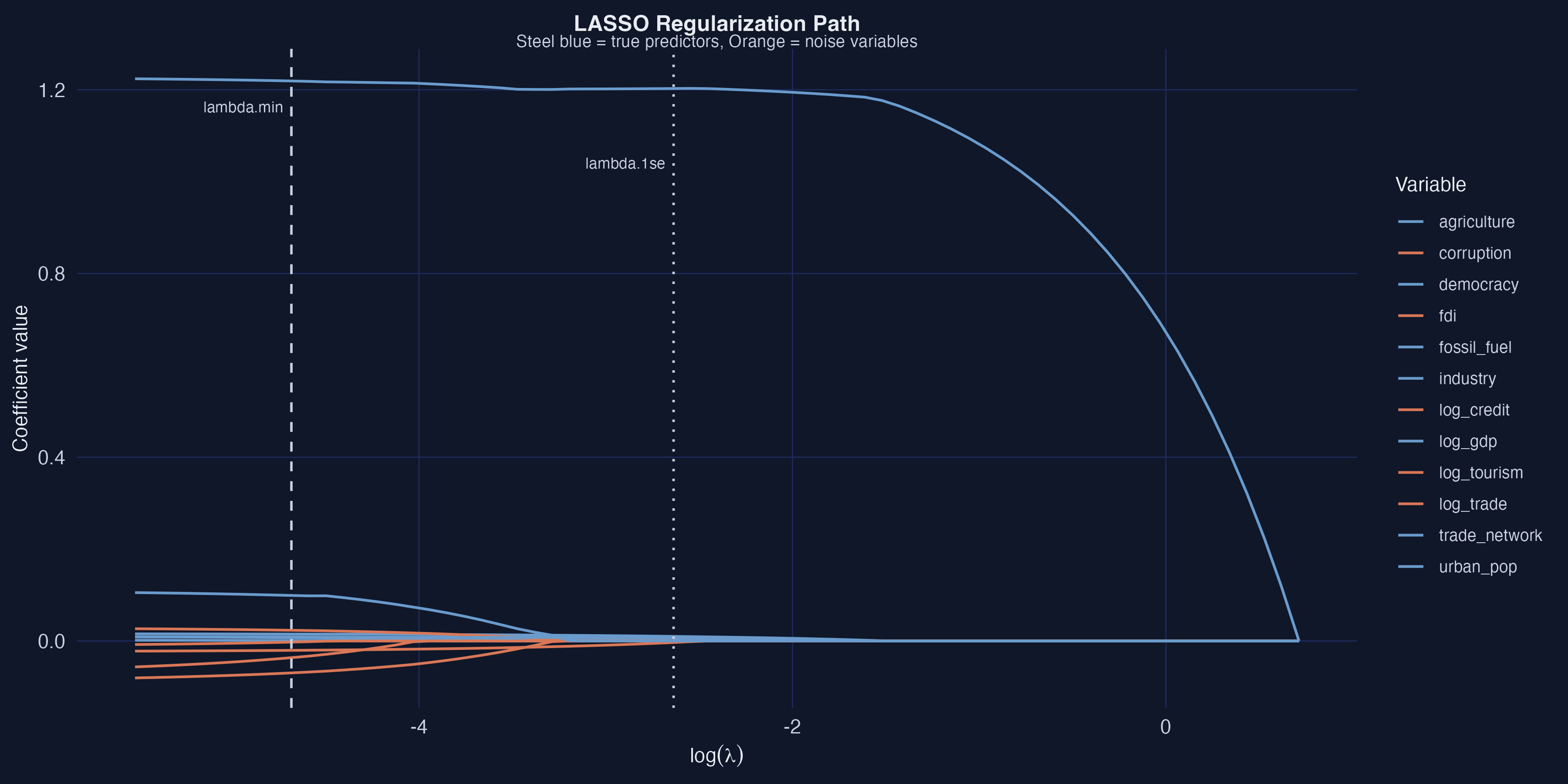
Regularization path — as \(\lambda\) grows (left→right), orange noise variables hit zero first; GDP (\(\beta=1.200\)) persists longest. Dashed/dotted lines mark \(\lambda_{\min}\) and \(\lambda_{1\text{se}}\).
At the parsimonious penalty, LASSO keeps six variables — all real
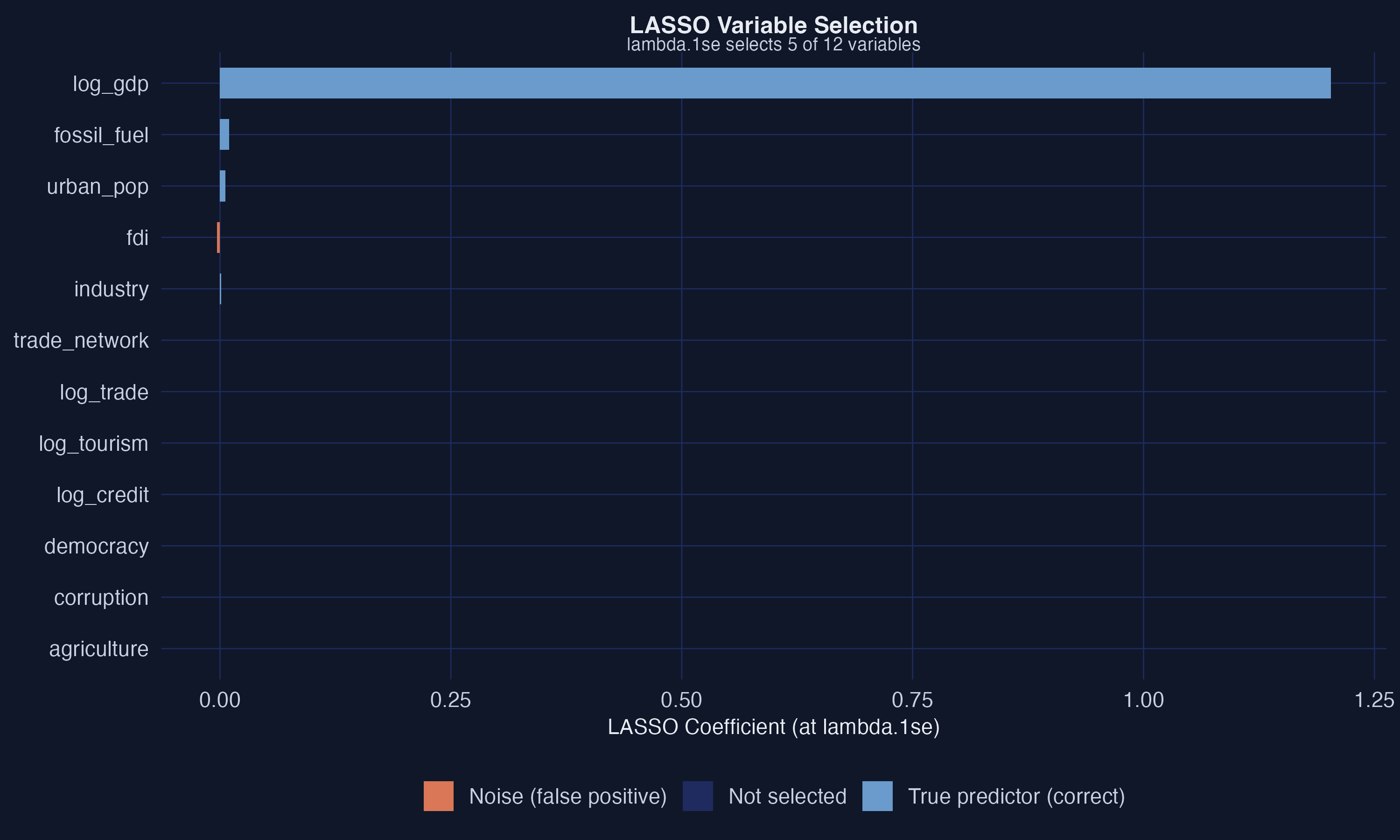
Six bars survive (steel blue = true predictor correctly kept); gray bars are dropped. No orange — zero noise variables falsely selected.
WALS averages with the same prior LASSO uses for selection
\[p(\gamma_j)\propto\exp(-|\gamma_j|/\tau)\]
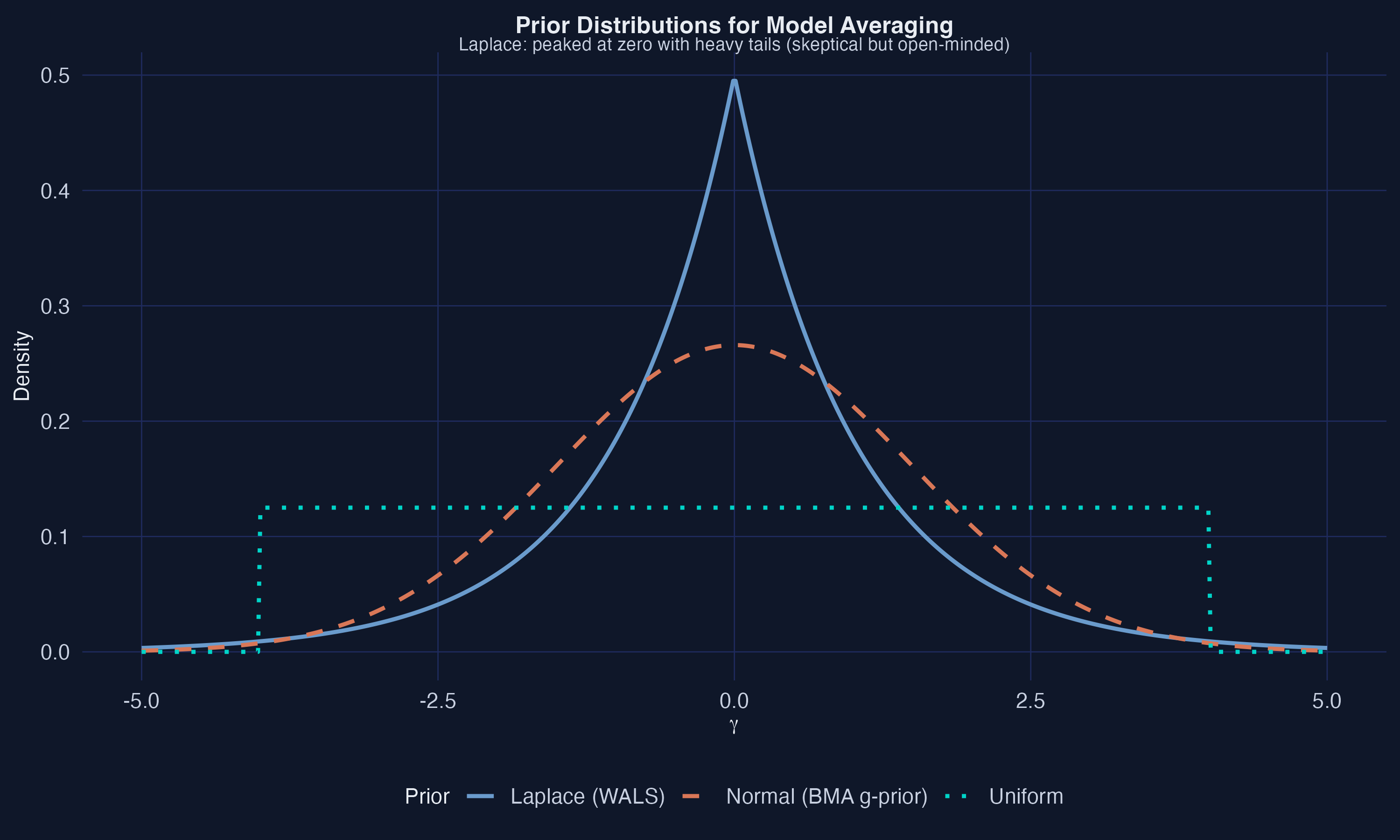
The Laplace prior (WALS) is peaked at zero with heavy tails — skeptical but open-minded. Its negative log is LASSO’s L1 penalty.
WALS makes GDP tower: \(|t|=34.62\), far above every other variable
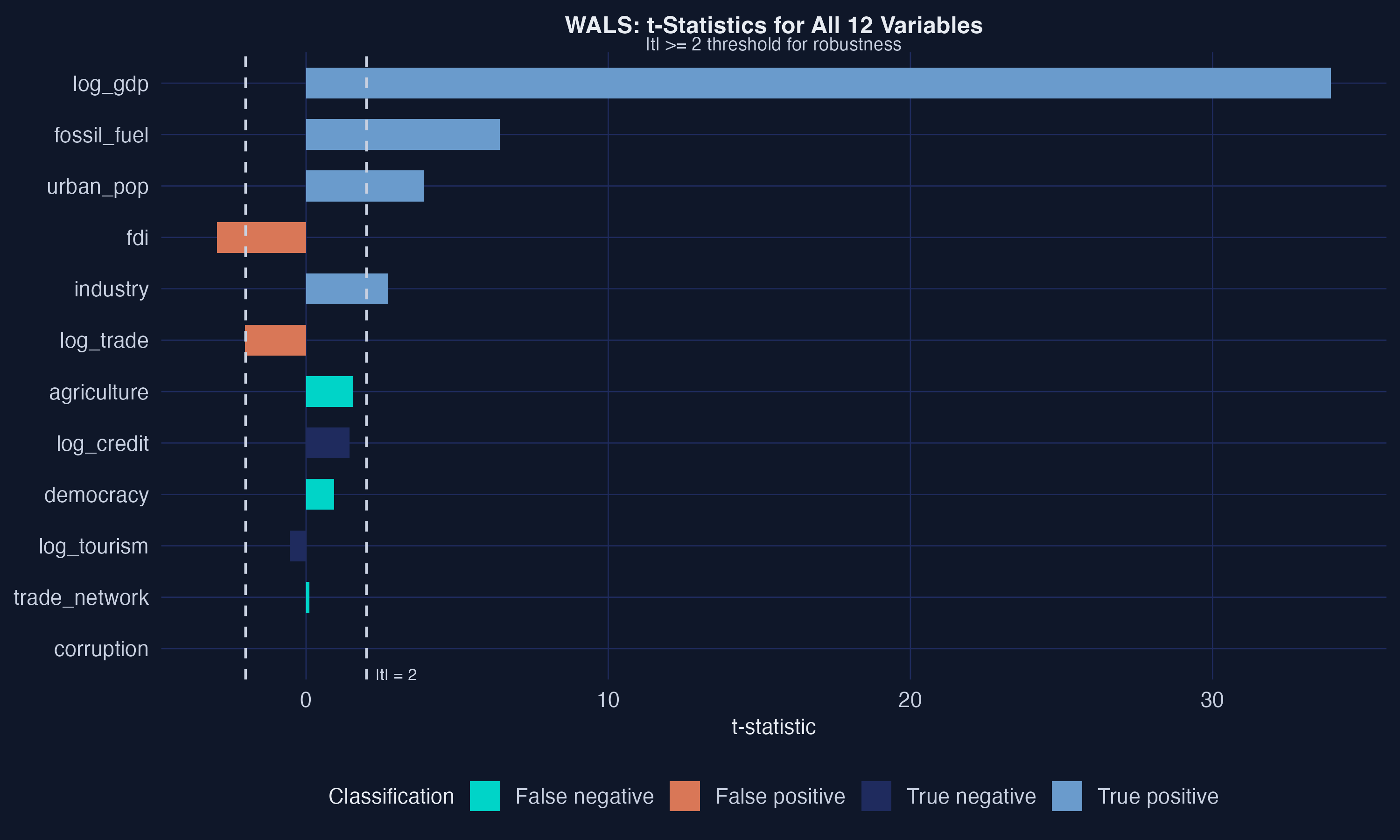
Six variables clear the \(|t|\geq 2\) line; GDP’s bar runs off the chart at 34.62, trade network next at 4.39. Noise variables all sit below 1.5.
Three columns of agreement — and two honest splits
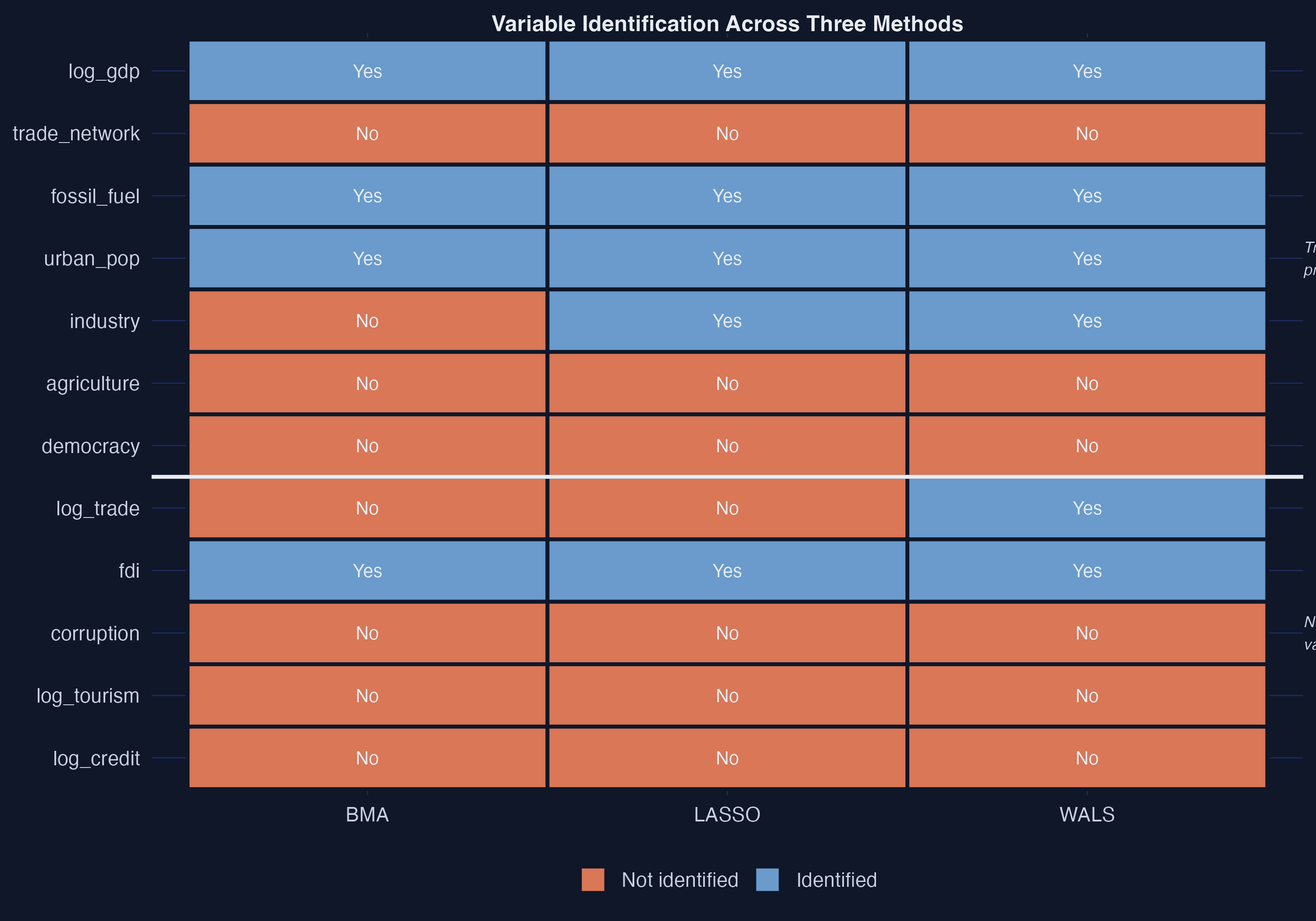
Method-agreement heatmap. Top four rows solid steel blue across all three methods; bottom five (noise) solid orange. Urban_pop and democracy split blue (LASSO/WALS) vs orange (BMA).
BMA and WALS line up — but BMA’s bar is set higher
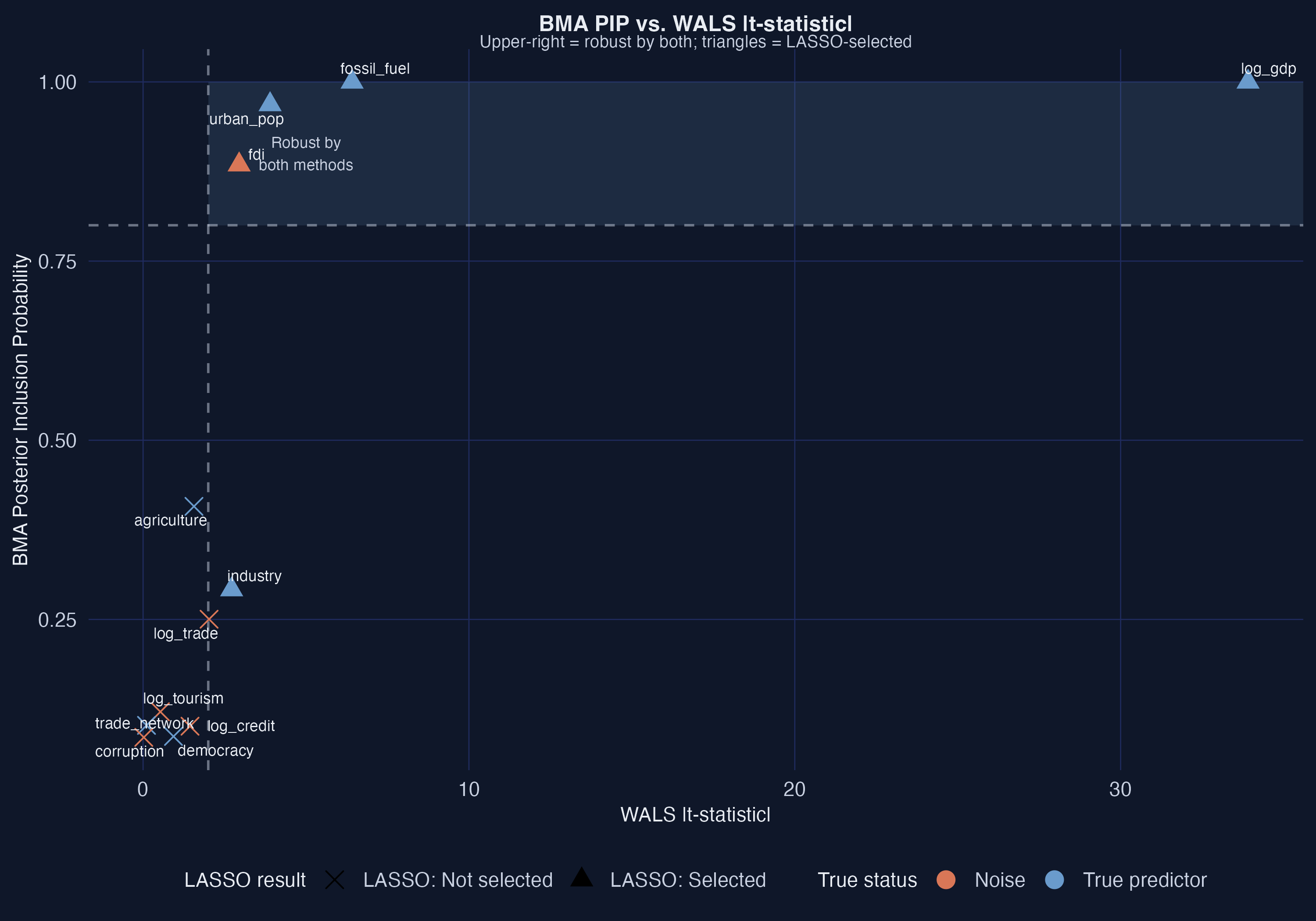
BMA PIP vs WALS \(|t|\). Upper-right quadrant = robust by both (the core four). Urban_pop and democracy: high \(|t|\) but PIP < 0.80 — BMA’s conservatism made visible.
All three recover GDP almost exactly; small effects are harder
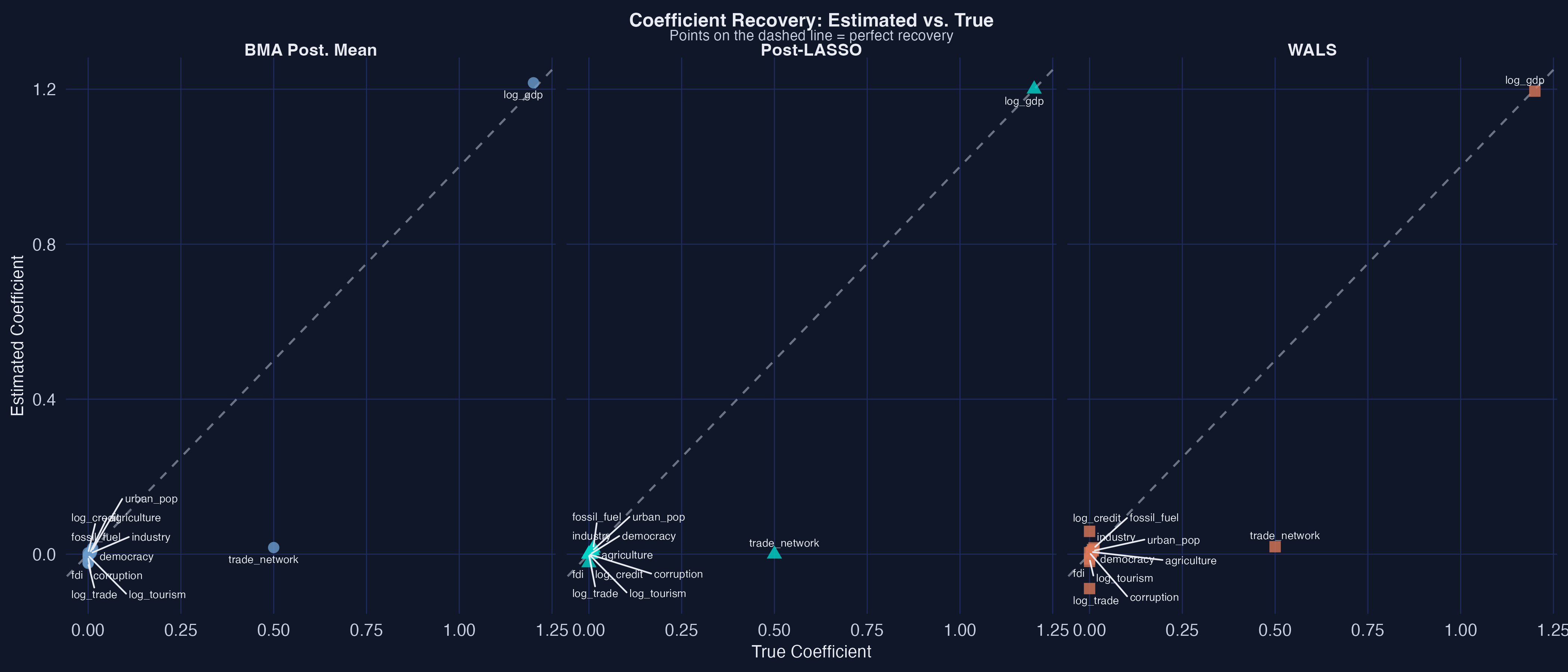
Estimates vs true coefficients, faceted by method. Points on the 45° line = perfect recovery. GDP lands on the line for all three; trade network is overshot by all (low-variance regressor).