Six Ways to Evaluate a Policy
Comparative case studies of California’s Proposition 99, in R
Nagoya University (GSID)
July 8, 2026
One dataset, six estimators — and they disagree from −28 to +4.5 packs
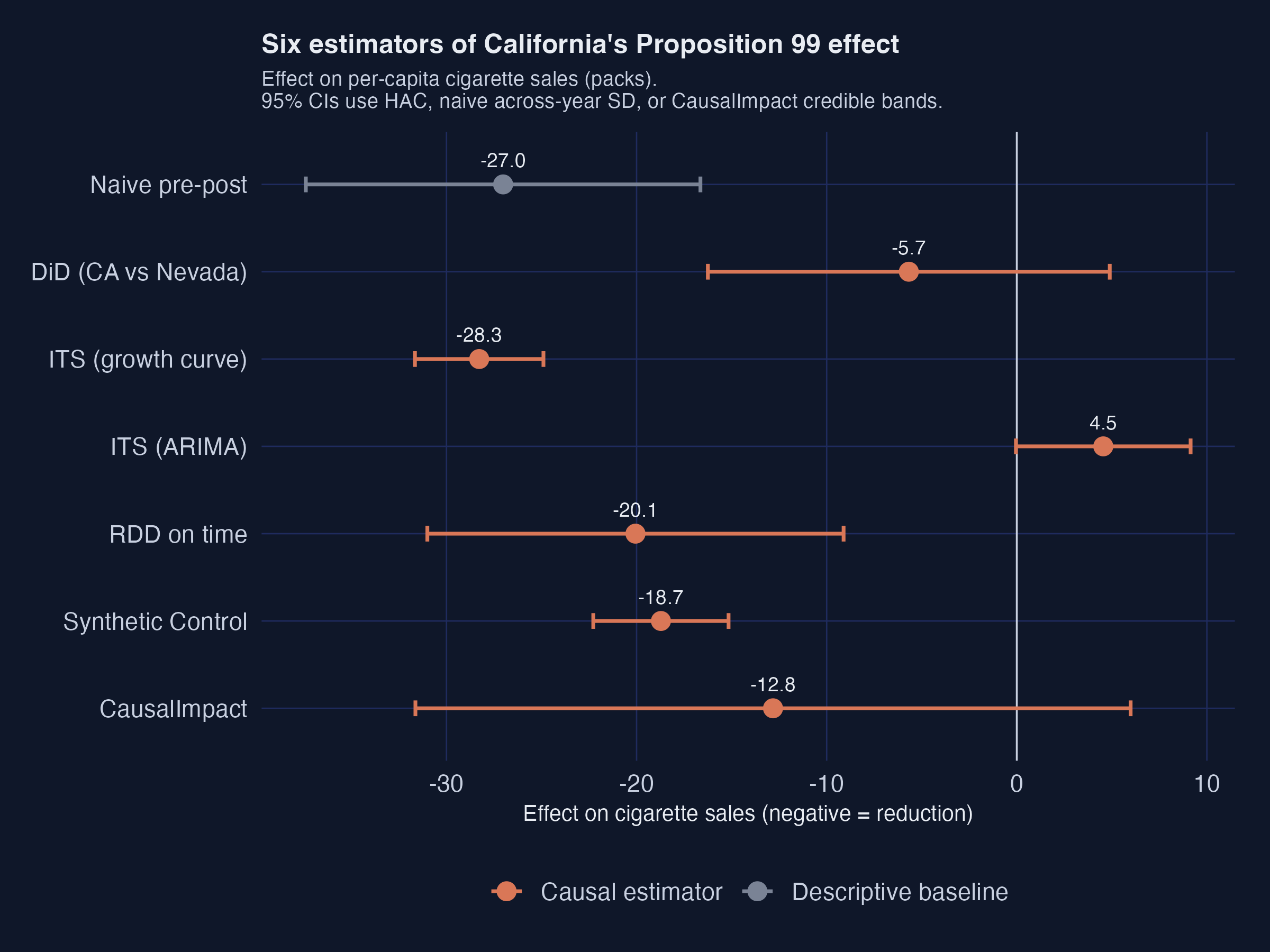
Effect on per-capita cigarette sales, 95% intervals · naive, DiD, two ITS, RDD-on-time, synthetic control, CausalImpact. Dashed line = zero.
DiD against Nevada collapses to −5.7 packs — a single bad control destroys the contrast
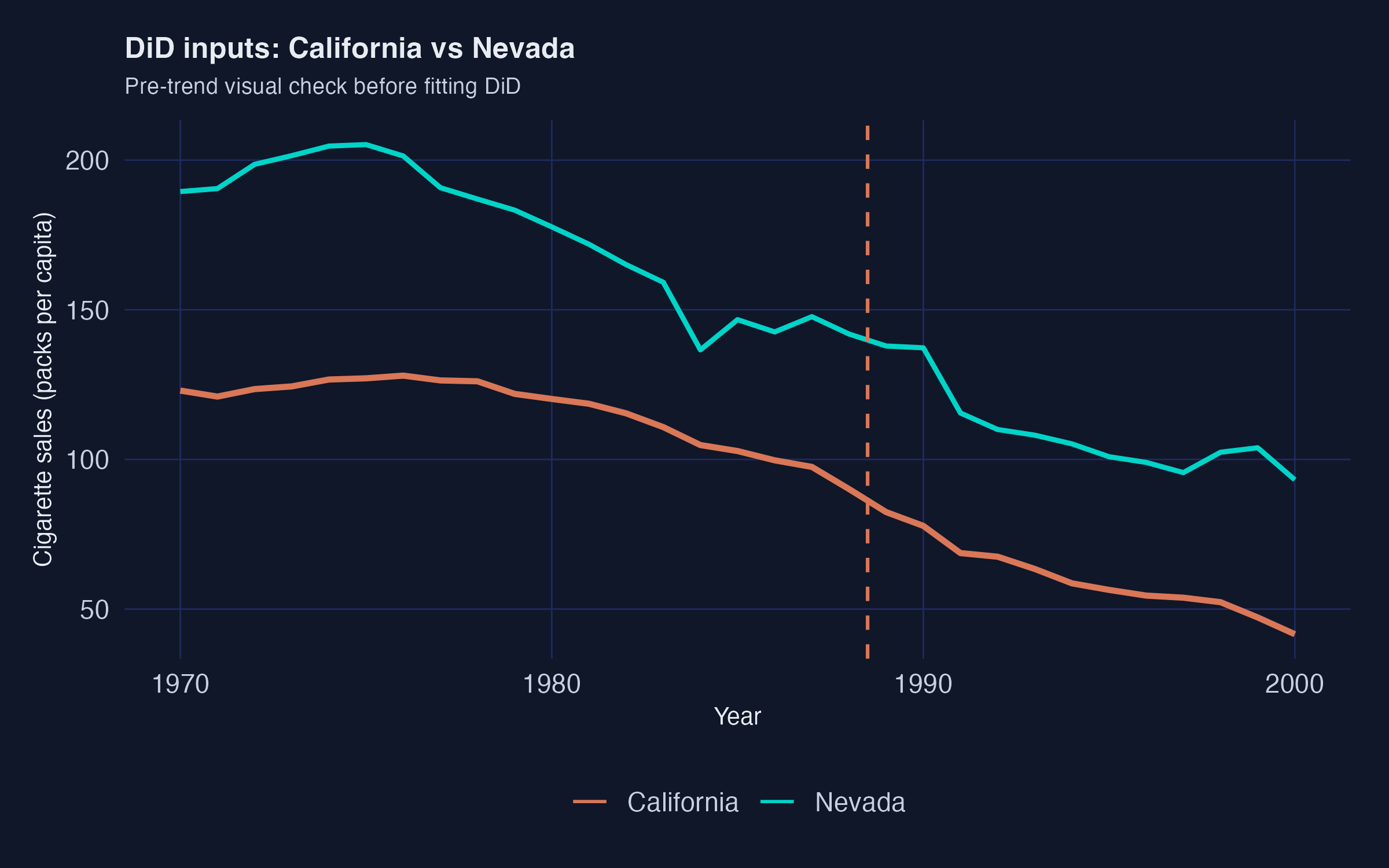
California (orange) vs Nevada (blue): both already falling before 1989, so the difference-in-differences contrast nearly vanishes.
Why the ARIMA counterfactual misfires: it forecasts below what California actually did
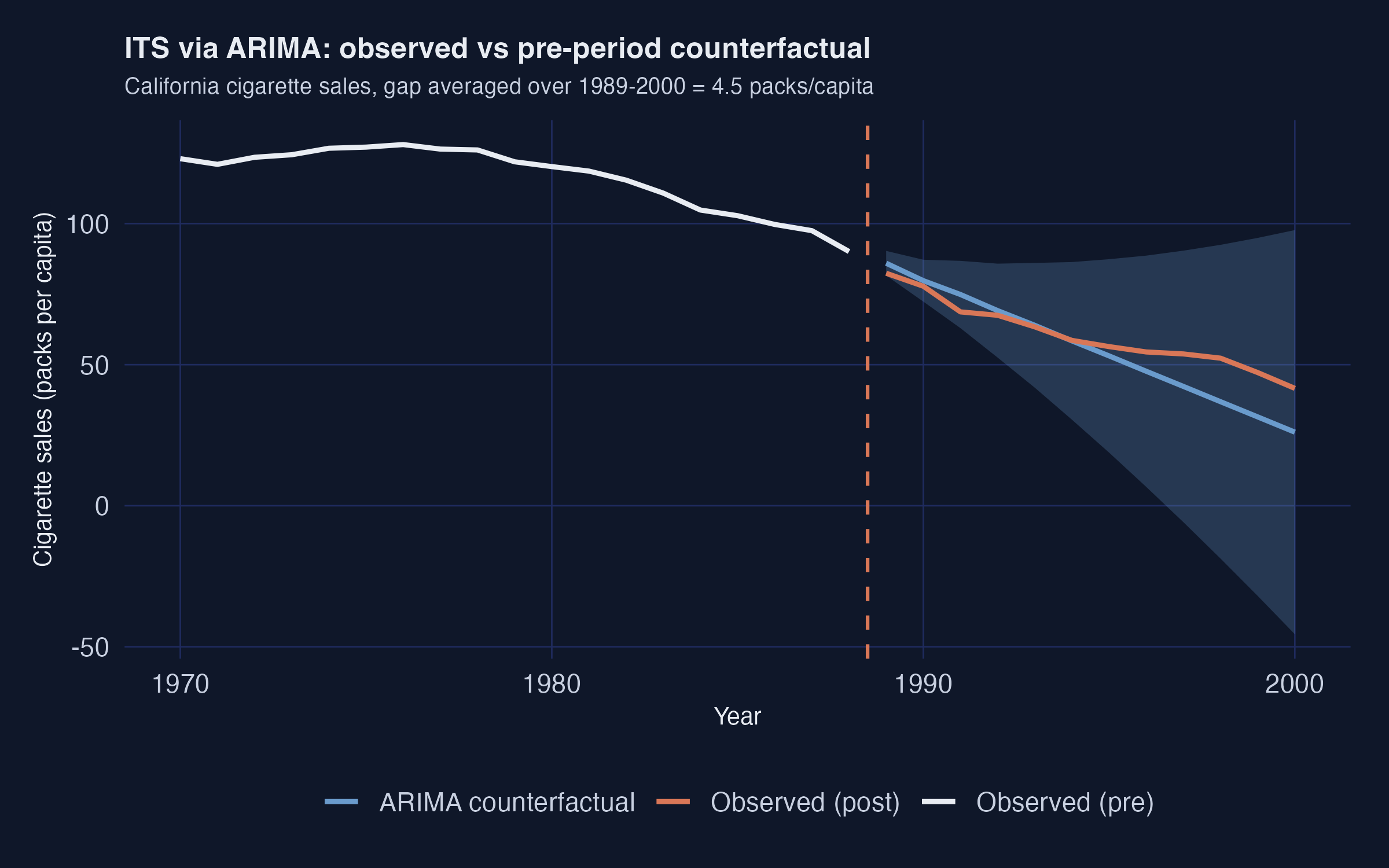
ARIMA(1,2,0) counterfactual (dashed, with 95% band) sits below the observed orange series throughout 1989–2000.
RDD-on-time finds a −20 pack level break right at 1989
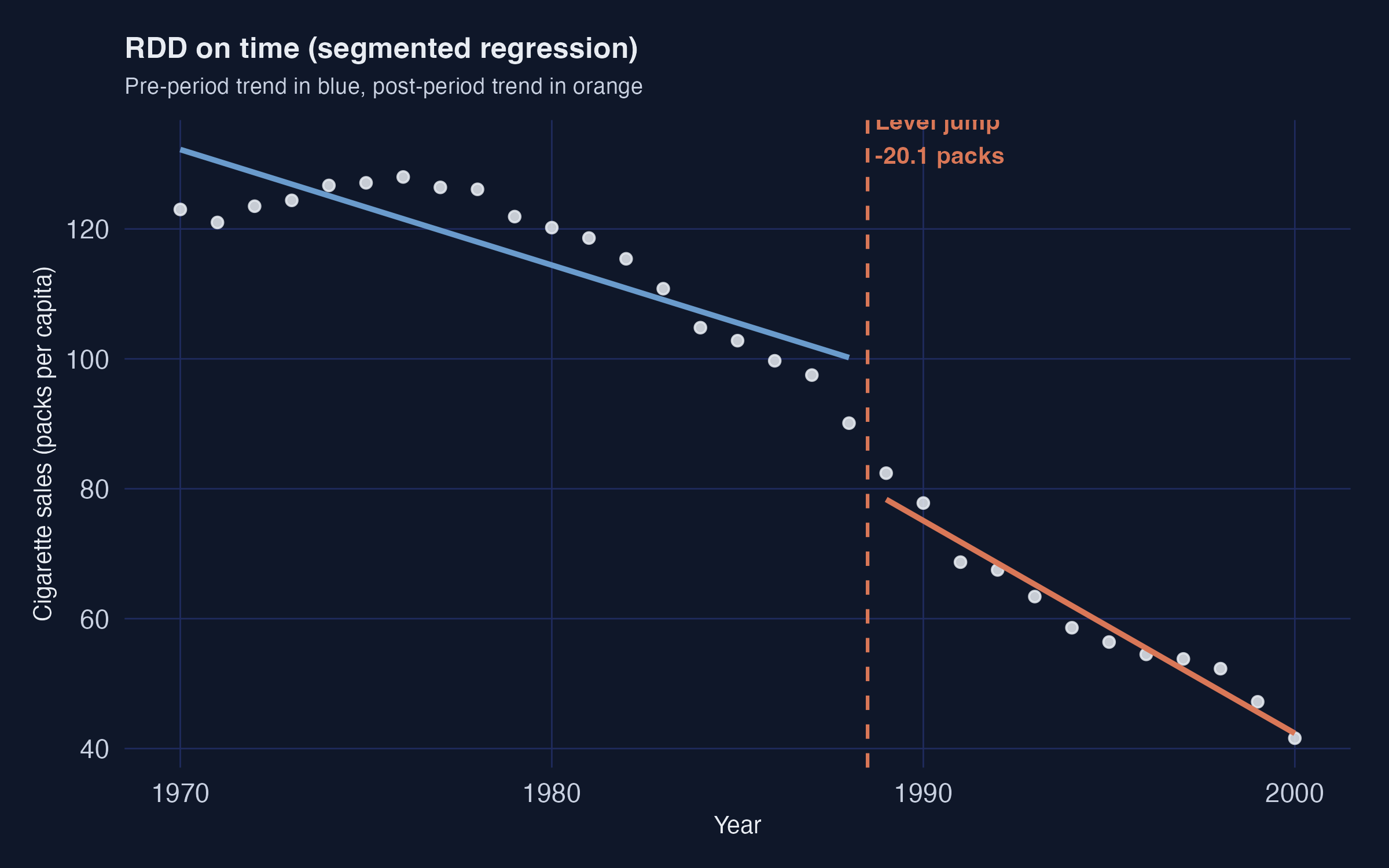
Piecewise pre/post linear fit (\(R^2 = 0.97\)): a clear level jump and a steeper slope at the 1989 threshold.
Synthetic control blends donors instead of picking one: −18.9 packs
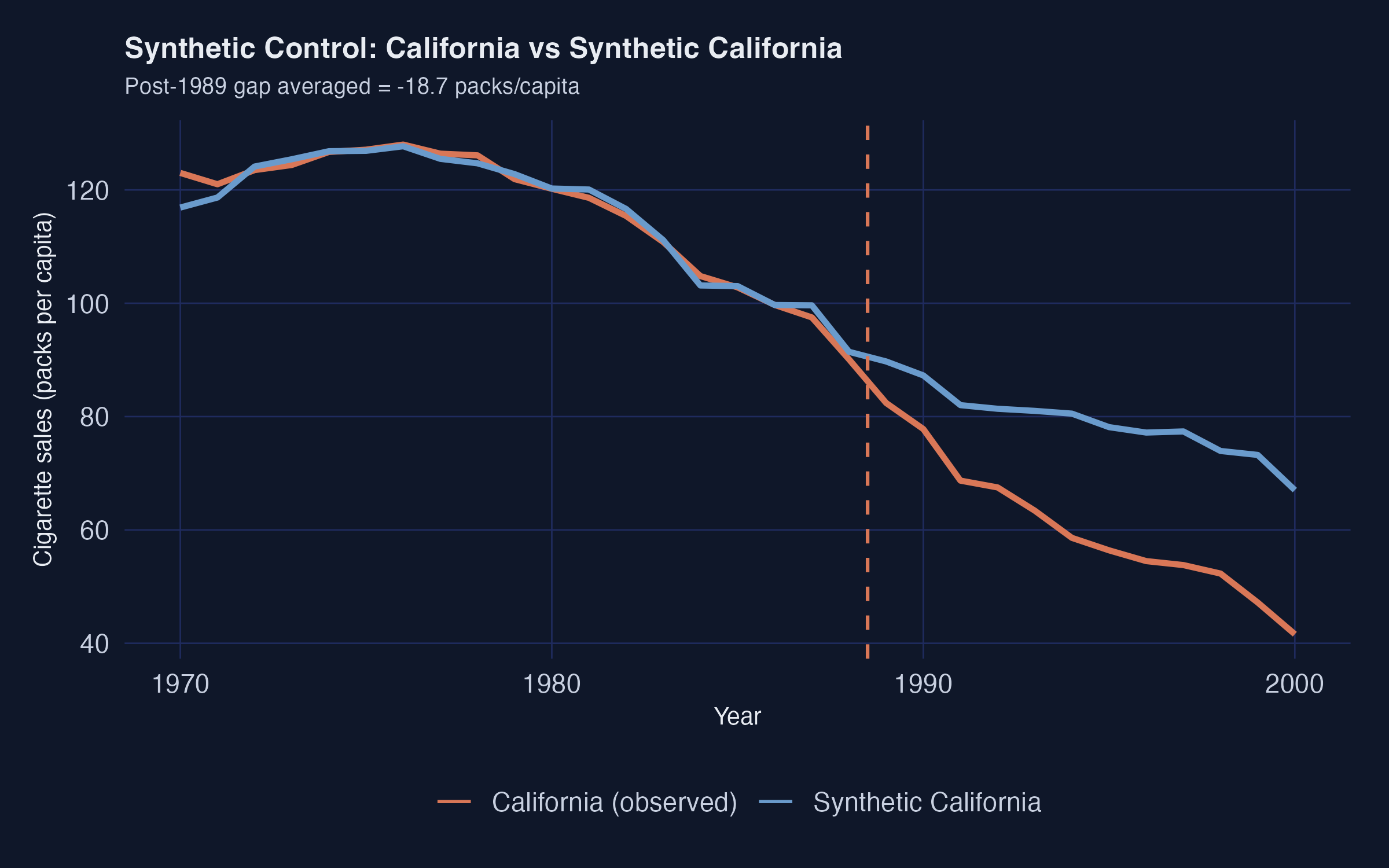
California (observed) vs synthetic California: near-perfect pre-1989 fit, then a gap opens and widens to ~30 packs by 2000.
Synthetic California is five states, anchored on lagged cigarette sales
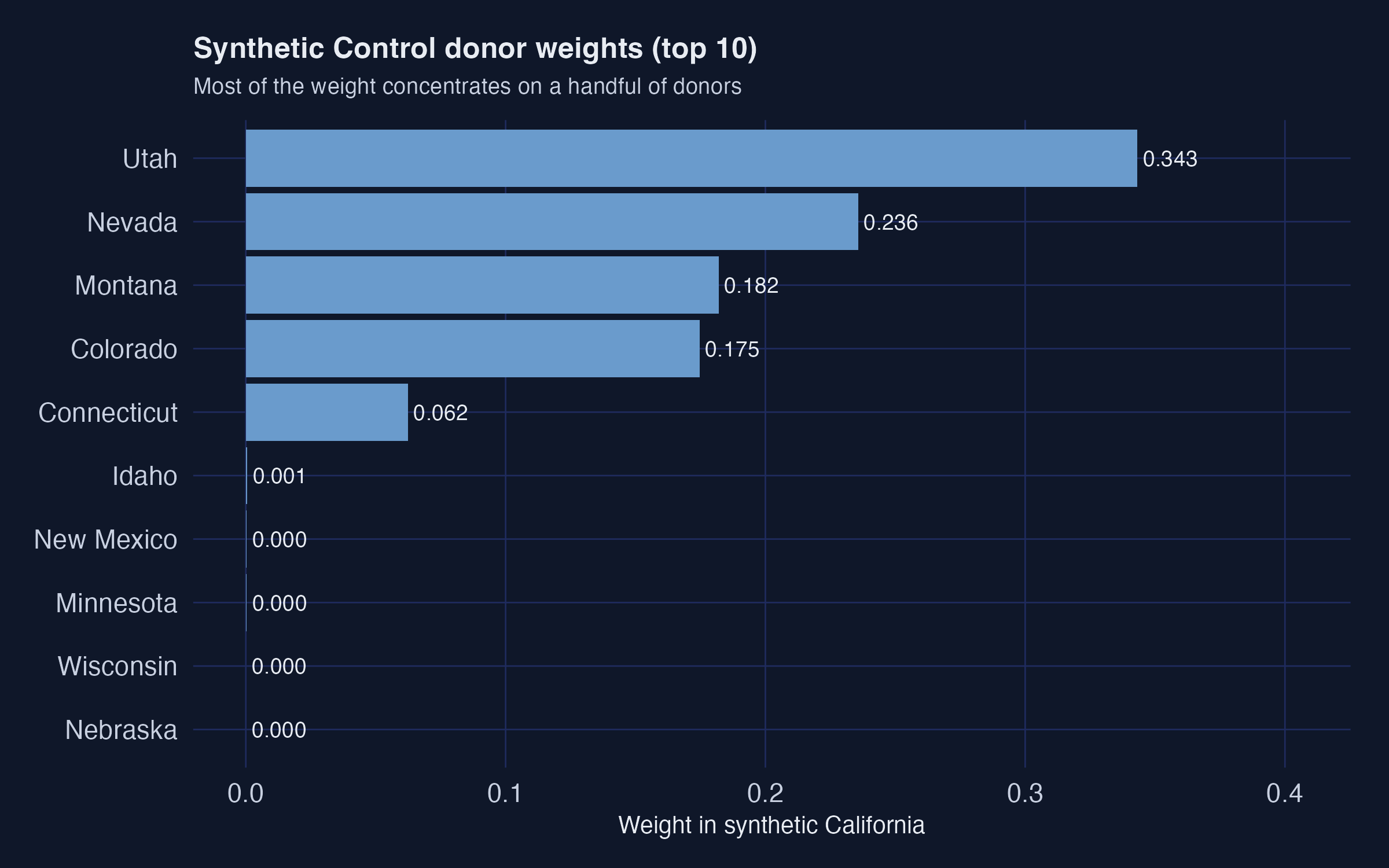
Faceted plot_weights output: five donor states carry ~100% of the weight (left); two lagged outcomes dominate the V matrix (right).
CausalImpact hands the donors to a Bayesian model: −13 packs, 92% posterior probability
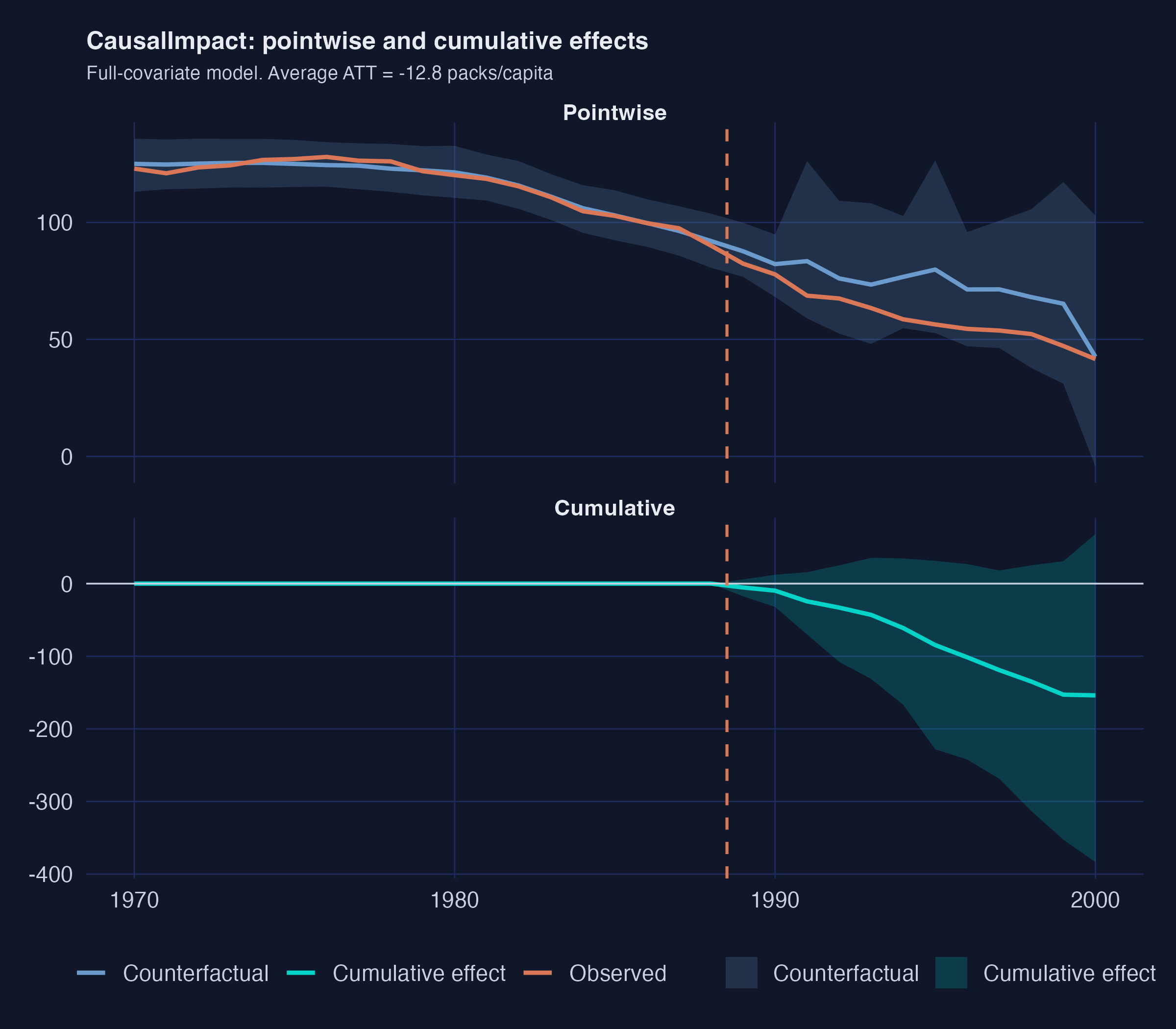
Top: observed California vs Bayesian counterfactual with a widening credible band. Bottom: cumulative effect reaching ~−150 packs by 2000.