What Does TWFE Actually Do? Manual Demeaning and the FWL Theorem
1. Overview
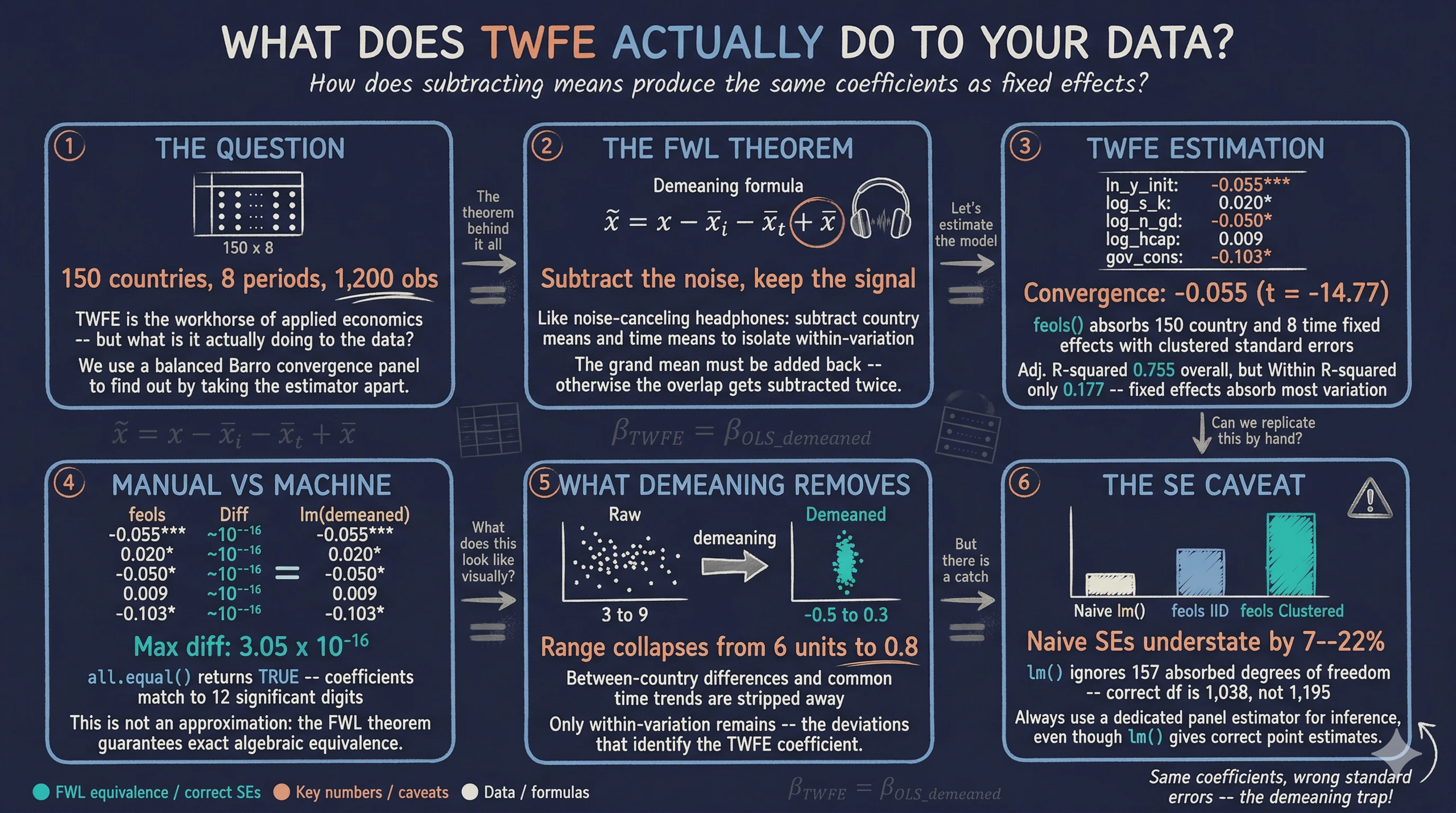
Two-way fixed effects (TWFE) is one of the most widely used estimators in applied economics. Packages like fixest make it easy to estimate TWFE models with a single line of code. But what does the estimator actually do to the data? Why do time-invariant regressors like geography or colonial origin get dropped? And if you run lm() on manually demeaned data, should you get the same answer?
This tutorial answers these questions by taking TWFE apart. We estimate a standard growth regression with country and time fixed effects, then replicate the exact same coefficients by hand — subtracting country means, time means, and adding back the grand mean before running ordinary least squares. The result is not an approximation: the coefficients match to 12 significant digits. The theoretical foundation for this equivalence is the Frisch-Waugh-Lovell (FWL) theorem, a fundamental result in econometrics that connects controlling for variables in a regression to projecting them out by residualization.
We use a balanced panel of 150 countries observed over 8 time periods from the Barro convergence dataset. Along the way, we also discover why standard errors from naive lm() on demeaned data are wrong — and why you should always use a dedicated panel estimator for inference.
Learning objectives:
- Understand what two-way fixed effects does mechanically to the data and why time-invariant regressors are dropped
- Implement the two-way demeaning formula step by step: subtract country means, subtract time means, add back the grand mean
- Verify the Frisch-Waugh-Lovell theorem empirically by comparing
feols()andlm()coefficients - Interpret why naive standard errors from
lm()on demeaned data are incorrect and howfixestcorrects them - Visualize the demeaning transformation to build intuition about within-variation identification
2. The Frisch-Waugh-Lovell Theorem
Before diving into code, let us build the conceptual foundation. The FWL theorem answers a simple question: if you want to estimate the effect of $X$ on $Y$ while controlling for a set of variables $Z$, do you need to include everything in one big regression?
Think of it like noise-canceling headphones. Instead of listening to music with the engine noise mixed in, the headphones first subtract out the engine noise from what you hear. The result is the same music you would hear in a silent room. The FWL theorem says: instead of including all control variables in one regression, you can first “subtract them out” from both $Y$ and $X$, and then regress the residuals on each other. The coefficient on $X$ will be identical either way.
Applying FWL to two-way fixed effects
In a TWFE model, the “controls” $Z$ are the full set of country dummies and time dummies. Including all these dummies is equivalent to subtracting group means. For a variable $x_{it}$ observed for country $i$ in period $t$, the two-way demeaned version is:
$$\tilde{x}_{it} = x_{it} - \bar{x}_{i \cdot} - \bar{x}_{\cdot t} + \bar{x}_{\cdot \cdot}$$
In words, this formula says: take the observed value, subtract the country average (to remove persistent country differences), subtract the time-period average (to remove common shocks), and add back the overall average (to correct for double-subtracting the grand mean).
Here is what each symbol means:
- $x_{it}$ is the observed value for country $i$ at time $t$ — in code, this is a single cell in the panel dataset
- $\bar{x}_{i \cdot}$ is the country mean — the average of $x$ across all periods for country $i$
- $\bar{x}_{\cdot t}$ is the time mean — the average of $x$ across all countries in period $t$
- $\bar{x}_{\cdot \cdot}$ is the grand mean — the overall average of $x$ across all observations
Why add back the grand mean?
When we subtract both the country mean and the time mean, the grand mean gets subtracted twice — once as part of $\bar{x}_{i \cdot}$ and once as part of $\bar{x}_{\cdot t}$. Adding $\bar{x}_{\cdot \cdot}$ back corrects for this double subtraction. Think of it like a Venn diagram with two overlapping circles. If you subtract both circles entirely, the overlap region gets removed twice. Adding the overlap back once restores the correct amount. Without this correction, the demeaned variables would not be centered at zero, and the equivalence with TWFE would break.
The FWL theorem guarantees this equivalence formally:
$$\hat{\beta}_{\text{TWFE}} = \hat{\beta}_{\text{OLS on demeaned data}}$$
In words, the slope coefficients from a regression that includes a full set of entity and time dummies are exactly equal to the slopes from OLS applied to the two-way demeaned data. Not approximately — exactly. Let us verify this with real data.
3. Setup
We need fixest for TWFE estimation and tidyverse for data wrangling and visualization. The scales package provides axis formatting utilities.
library(fixest)
library(tidyverse)
library(scales)
set.seed(42)
# Site color palette
STEEL_BLUE <- "#6a9bcc"
WARM_ORANGE <- "#d97757"
NEAR_BLACK <- "#141413"
TEAL <- "#00d4c8"
# Variables to demean
VARS_TO_DEMEAN <- c("growth", "ln_y_initial", "log_s_k",
"log_n_gd", "log_hcap", "gov_cons")
We define the six variables that will be demeaned: the dependent variable (growth) and all five regressors. Keeping them in a vector allows us to apply the demeaning formula programmatically rather than copying and pasting for each variable.
4. Data Loading and Panel Structure
We load a balanced panel dataset with 150 countries observed over 8 time periods. The data comes from a Barro convergence exercise where the key question is whether poorer countries grow faster (conditional convergence). We convert id and time to factors so R treats them as categorical grouping variables.
panel_data <- read.csv("referenceMaterials/barro_convergence_panel.csv")
panel_data$id <- factor(panel_data$id)
panel_data$time <- factor(panel_data$time)
cat("Countries:", nlevels(panel_data$id), "\n")
cat("Time periods:", nlevels(panel_data$time), "\n")
cat("Total observations:", nrow(panel_data), "\n")
cat("Balanced panel:", all(table(panel_data$id) == nlevels(panel_data$time)), "\n")
Countries: 150
Time periods: 8
Total observations: 1200
Balanced panel: TRUE
The dataset is a perfectly balanced panel of 150 countries observed across 8 time periods, yielding 1,200 total observations. A balanced panel means every country appears in every period with no missing cells — the ideal setting for demonstrating the demeaning formula. The key variables are:
growth: annualized GDP per capita growth rate (dependent variable)ln_y_initial: log of initial income (convergence term)log_s_k: log of the investment sharelog_n_gd: log of population growth plus depreciationlog_hcap: log of human capitalgov_cons: government consumption share
 Panel structure heatmap showing all 150 countries observed across 8 time periods with no missing cells.
Panel structure heatmap showing all 150 countries observed across 8 time periods with no missing cells.
The heatmap confirms the balanced structure. Every one of the 150 countries is observed in all 8 time periods. This balance simplifies our demeaning procedure because we can use the closed-form formula directly, without the iterative projection that unbalanced panels would require.
5. TWFE Estimation with fixest
The fixest package makes TWFE estimation straightforward. The formula uses | to separate the regressors (left) from the fixed effects dimensions (right). Writing | id + time tells feols() to absorb both country and time fixed effects. Internally, fixest performs an efficient iterative demeaning algorithm to remove the fixed effects before estimating the slope coefficients.
twfe_model <- feols(
growth ~ ln_y_initial + log_s_k + log_n_gd + log_hcap + gov_cons | id + time,
data = panel_data
)
summary(twfe_model)
OLS estimation, Dep. Var.: growth
Observations: 1,200
Fixed-effects: id: 150, time: 8
Standard-errors: Clustered (id)
Estimate Std. Error t value Pr(>|t|)
ln_y_initial -0.055286 0.003744 -14.765156 < 2.2e-16 ***
log_s_k 0.019725 0.007583 2.601311 0.010223 *
log_n_gd -0.049614 0.022168 -2.238117 0.026696 *
log_hcap 0.009081 0.014564 0.623549 0.533877
gov_cons -0.102795 0.046398 -2.215501 0.028243 *
RMSE: 0.020517 Adj. R2: 0.755103
Within R2: 0.176777
The TWFE model reveals strong conditional beta-convergence — the hypothesis that poorer countries tend to grow faster, so income levels converge over time. The coefficient on log initial income is -0.055 (t = -14.77, p < 2.2e-16), meaning that a 1% higher initial income is associated with 0.055 percentage points slower subsequent growth, after controlling for the other covariates. Investment has the expected positive effect (0.020, p = 0.010), population growth has the expected negative effect (-0.050, p = 0.027), and government consumption is significantly negative (-0.103, p = 0.028). Human capital is positive but not statistically significant (0.009, p = 0.534). The model explains 75.5% of total variation (Adj. R-squared = 0.755), though only 17.7% of the within-variation (Within R-squared = 0.177) — typical for panel models where fixed effects absorb most cross-country heterogeneity.
Now let us replicate these coefficients by hand.
6. Manual Demeaning — Step by Step
We now walk through the demeaning procedure one step at a time. The goal is to transform every variable so that the country and time effects are removed. We will then run plain OLS on the result and verify that the coefficients match.
Step 1: Country means
For each country, we compute the average of each variable across all time periods. This gives us one mean per country per variable — capturing persistent country characteristics like geography, institutions, or long-run income level.
country_means <- panel_data |>
group_by(id) |>
summarise(across(all_of(VARS_TO_DEMEAN), mean), .groups = "drop")
Step 2: Time means
For each time period, we compute the average of each variable across all countries. These time means capture common shocks or trends that affect all countries in a given period — for instance, a global recession or a worldwide productivity boom.
time_means <- panel_data |>
group_by(time) |>
summarise(across(all_of(VARS_TO_DEMEAN), mean), .groups = "drop")
Step 3: Grand mean
The grand mean is simply the overall average of each variable across all countries and all time periods. It is a single number per variable, and we need it to correct for the double subtraction.
grand_means <- colMeans(panel_data[VARS_TO_DEMEAN])
growth ln_y_initial log_s_k log_n_gd log_hcap gov_cons
-0.1243637 5.3643127 -1.5699117 -2.6569021 0.6645657 0.1461335
Step 4: Apply the demeaning formula
Now we bring everything together. We merge the country means and time means back into the main dataset, then apply the formula $\tilde{x}_{it} = x_{it} - \bar{x}_{i \cdot} - \bar{x}_{\cdot t} + \bar{x}_{\cdot \cdot}$ programmatically to each variable.
# Merge means
panel_dm <- panel_data |>
left_join(
country_means |> rename_with(~ paste0(.x, "_cmean"), all_of(VARS_TO_DEMEAN)),
by = "id"
) |>
left_join(
time_means |> rename_with(~ paste0(.x, "_tmean"), all_of(VARS_TO_DEMEAN)),
by = "time"
)
# Apply demeaning formula
for (v in VARS_TO_DEMEAN) {
panel_dm[[paste0(v, "_dm")]] <-
panel_dm[[v]] -
panel_dm[[paste0(v, "_cmean")]] -
panel_dm[[paste0(v, "_tmean")]] +
grand_means[v]
}
Let us verify that the demeaning worked correctly. If the formula is implemented right, the mean of each demeaned variable should be approximately zero.
Mean of demeaned variables (should be ~0):
growth_dm : -8.114169e-17
ln_y_initial_dm : 8.295170e-15
log_s_k_dm : -1.482923e-15
log_n_gd_dm : 1.599953e-15
log_hcap_dm : 5.384582e-17
gov_cons_dm : 1.832302e-16
All six demeaned variables have means on the order of $10^{-15}$ to $10^{-17}$ — effectively zero within floating-point precision. The demeaning formula is implemented correctly: the within-variation that remains is purely the deviation from both entity-specific and time-specific patterns.
7. OLS on the Demeaned Data
With the demeaning complete, we run a standard OLS regression on the demeaned variables using base R’s lm(). We deliberately use lm() rather than feols() to emphasize that this is plain ordinary least squares — no fixed effects machinery is involved.
manual_model <- lm(
growth_dm ~ ln_y_initial_dm + log_s_k_dm + log_n_gd_dm + log_hcap_dm + gov_cons_dm,
data = panel_dm
)
summary(manual_model)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.035e-16 5.938e-04 0.000 1.00000
ln_y_initial_dm -5.529e-02 3.618e-03 -15.282 < 2e-16 ***
log_s_k_dm 1.972e-02 6.846e-03 2.881 0.00403 **
log_n_gd_dm -4.961e-02 1.820e-02 -2.726 0.00651 **
log_hcap_dm 9.081e-03 1.370e-02 0.663 0.50751
gov_cons_dm -1.028e-01 4.411e-02 -2.331 0.01994 *
Residual standard error: 0.02057 on 1194 degrees of freedom
Multiple R-squared: 0.1768
Two things stand out. First, the intercept is 5.03 x 10^-16 — effectively zero. After proper two-way demeaning, the mean of all demeaned variables is near zero, so there is nothing left for the intercept to capture. This is a good sanity check: if the grand mean correction had been omitted, the intercept would be non-zero. Second, the slope coefficients look identical to those from feols(). But “look identical” is not the same as “are identical.” The next section proves they are.
8. Coefficient Comparison: The Proof
We now place the coefficients from both approaches side by side and compute their difference. If the FWL theorem holds, the slope coefficients must be identical up to floating-point precision.
twfe_coefs <- coef(twfe_model)
manual_coefs <- coef(manual_model)[-1] # drop intercept
names(manual_coefs) <- names(twfe_coefs)
comparison <- data.frame(
feols_TWFE = round(twfe_coefs, 12),
Manual_OLS = round(manual_coefs, 12),
Difference = twfe_coefs - manual_coefs
)
all.equal(unname(twfe_coefs), unname(manual_coefs))
Side-by-side coefficient comparison:
variable feols_TWFE manual_OLS difference
ln_y_initial -0.055286009819 -0.055286009819 -4.163336342e-17
log_s_k 0.019724899416 0.019724899416 3.469446952e-18
log_n_gd -0.049613972524 -0.049613972524 -2.775557562e-16
log_hcap 0.009081150621 0.009081150621 3.469446952e-17
gov_cons -0.102795317426 -0.102795317426 -3.053113318e-16
Maximum absolute difference: 3.053113e-16
all.equal() test: TRUE
This is the central result of the tutorial. All five slope coefficients are identical to at least 12 significant digits. The largest difference is 3.05 x 10^-16 — on the order of IEEE 754 double-precision machine epsilon (~2.2 x 10^-16). R’s all.equal() function confirms equality within its default tolerance. This is not an approximation: it is an exact algebraic identity guaranteed by the Frisch-Waugh-Lovell theorem.
 Coefficient comparison: feols TWFE (blue circles) and manual demeaning OLS (orange triangles) occupy the exact same positions.
Coefficient comparison: feols TWFE (blue circles) and manual demeaning OLS (orange triangles) occupy the exact same positions.
The dot plot makes the equivalence visually concrete. For each of the five covariates, the steel blue circle (feols TWFE) and warm orange triangle (manual demeaning OLS) occupy the exact same position. Government consumption has the largest coefficient in magnitude at -0.103, while the convergence parameter (log initial income) sits at -0.055. The dashed zero line helps distinguish positive from negative effects.
9. Visualizing What Demeaning Does
The coefficient equivalence is proven, but what does demeaning look like? How does it change the data? The following visualizations build intuition about the transformation.
 Before vs after two-way demeaning: the wide cross-country spread (left) collapses to a narrow range around zero (right).
Before vs after two-way demeaning: the wide cross-country spread (left) collapses to a narrow range around zero (right).
The faceted scatter plot tells the story. In the left panel (raw data), 10 countries are plotted with log initial income on the x-axis and growth on the y-axis. Each country’s observations form a distinct cluster at different income levels — the x-axis spans roughly 3 to 9. In the right panel (after demeaning), the same data is compressed to approximately -0.5 to 0.3 around zero. The between-country income differences and common time trends have been stripped away, leaving only the within-variation — the deviations from each country’s own average and each period’s common trend. This is the variation that identifies the TWFE coefficient.
Decomposing the formula for one country
To see exactly how the formula works, let us trace each component for Country 1’s growth rate across all 8 periods.
 Demeaning decomposition for Country 1: observed growth (blue), country mean (orange dashed), time means (teal), grand mean (gray), and the demeaned residual (black).
Demeaning decomposition for Country 1: observed growth (blue), country mean (orange dashed), time means (teal), grand mean (gray), and the demeaned residual (black).
The decomposition makes the formula concrete. The observed growth values (blue line) decline from about -0.18 to -0.07. The country mean (orange dashed line) is a flat horizontal at -0.127 — this is $\bar{x}_{i \cdot}$. The time means (teal dot-dash line) capture the common cross-country trend, declining from -0.189 to -0.076 — this is $\bar{x}_{\cdot t}$. The grand mean (gray dotted) sits at -0.124 — this is $\bar{x}_{\cdot \cdot}$. The demeaned series (black line) is the residual: $\tilde{x}_{it} = x_{it} - \bar{x}_{i \cdot} - \bar{x}_{\cdot t} + \bar{x}_{\cdot \cdot}$. It fluctuates around zero, capturing only the within-country, within-period deviations that TWFE uses for identification.
10. A Caveat: Standard Errors Differ
While the coefficients are identical, the standard errors from lm() on demeaned data are wrong. This is a critical practical point that many textbooks gloss over.
se_naive <- summary(manual_model)$coefficients[-1, "Std. Error"]
se_feols_iid <- se(twfe_model, se = "iid")
se_feols_cl <- se(twfe_model) # default: clustered by first FE
Standard error comparison:
variable se_naive_lm se_feols_iid se_feols_cluster
ln_y_initial 0.00361766 0.00388000 0.00374436
log_s_k 0.00684559 0.00734199 0.00758268
log_n_gd 0.01820117 0.01952104 0.02216773
log_hcap 0.01369872 0.01469209 0.01456365
gov_cons 0.04410809 0.04730660 0.04639822
Why do they differ? The lm() function does not know that 157 degrees of freedom were consumed by estimating 150 country effects and 8 time effects (minus 1 for normalization). It uses $df = N \times T - K = 1{,}195$ when the correct value is $N \times T - N - T + 1 - K = 1{,}038$. This makes naive SEs systematically too small — they understate uncertainty by 7–22% depending on the variable.
 Standard error comparison: naive lm() (gray) systematically underestimates uncertainty compared to feols IID (orange) and clustered (blue).
Standard error comparison: naive lm() (gray) systematically underestimates uncertainty compared to feols IID (orange) and clustered (blue).
The grouped bar chart makes the pattern clear. For every variable, the gray bars (naive lm()) are shorter than the orange (feols IID) and blue (feols clustered) bars. The gap is most visible for log(n+g+d), where the naive SE is 0.0182 versus 0.0222 for clustered — a 22% understatement. The feols IID SEs correct for the degrees-of-freedom adjustment, while the clustered SEs additionally account for within-entity serial correlation. The practical lesson: always use a dedicated panel estimator for inference, even though lm() on demeaned data gives the correct point estimates.
11. Discussion
This tutorial has demonstrated a fundamental equivalence in econometrics. TWFE is not a special estimator — it is ordinary least squares applied to data that has been demeaned by entity and time. The fixest package automates this process efficiently, but the underlying operation is straightforward subtraction. The FWL theorem guarantees the equivalence mathematically, and our empirical verification confirms it to machine precision.
Three practical insights emerge:
-
Demeaning reveals what FE can and cannot identify. Any variable that does not vary within a country over time (like geography or colonial history) has a country mean equal to itself. After demeaning, such a variable becomes zero everywhere and drops out of the regression. This is why fixed effects models cannot estimate the effect of time-invariant characteristics.
-
The grand mean correction is not optional. Omitting the $+ \bar{x}_{\cdot \cdot}$ term in the demeaning formula would double-subtract the overall level, producing a non-zero intercept and subtly wrong demeaned values. The correction is algebraically necessary for the FWL equivalence to hold.
-
Correct coefficients do not mean correct inference. The
lm()standard errors are too small because they ignore the degrees of freedom consumed by the absorbed fixed effects. In applied work, this means artificially narrow confidence intervals and inflated t-statistics. Always usefeols()or an equivalent panel estimator for standard errors and hypothesis testing.
12. Summary and Next Steps
Key takeaways:
-
TWFE estimation via
feols()and OLS on manually demeaned data produce identical coefficients — the maximum difference across 5 coefficients is 3.05 x 10^-16, confirming the FWL theorem. -
The demeaning formula subtracts entity means and time means, then adds back the grand mean to correct for double subtraction. After demeaning, all variable means are effectively zero (order of 10^-15).
-
The Within R-squared of 0.177 versus the overall Adjusted R-squared of 0.755 shows that most variation in growth is absorbed by the fixed effects, not by the regressors.
-
Naive
lm()standard errors understate uncertainty by 7–22% because they ignore the 157 degrees of freedom consumed by the fixed effects. Always use a dedicated panel estimator for inference.
Limitations:
- The dataset is simulated, so coefficient values reflect the data-generating process rather than real-world economic dynamics.
- The tutorial assumes a balanced panel. With unbalanced panels, the simple closed-form demeaning still works algebraically, but
fixestuses a more efficient iterative algorithm. - The SE comparison covers only IID and entity-clustered SEs. Other corrections (heteroskedasticity-robust, Driscoll-Kraay for cross-sectional dependence) may be relevant in applied work.
Next steps:
- Apply the demeaning logic to understand why specific variables drop out of your own FE models.
- Explore heterogeneous treatment effects with interaction-weighted TWFE estimators.
- Read Cunningham (2021), Causal Inference: The Mixtape, Chapter 9, for the connection between TWFE demeaning and difference-in-differences designs.
13. Exercises
-
Omit the grand mean correction. Modify the demeaning formula to skip the $+ \bar{x}_{\cdot \cdot}$ term. Run
lm()on the incorrectly demeaned data. What happens to the intercept? Do the slope coefficients still match the TWFE estimates? Why or why not? -
One-way demeaning. Repeat the exercise using only entity demeaning (subtract country means, skip time means). Compare the coefficients to a one-way FE model (
feols(growth ~ ... | id)). Verify the equivalence and examine how the coefficients change compared to the two-way specification. -
Visualize a different variable. Recreate the demeaning decomposition plot (Section 9) for
log_s_k(investment share) instead ofgrowth. Does the country mean, time mean, or within-variation dominate for this variable? What does this tell you about the source of variation that identifies its coefficient?
14. References
-
Frisch, R. and Waugh, F.V. (1933). “Partial Time Regressions as Compared with Individual Trends.” Econometrica, 1(4), 387–401.
-
Lovell, M.C. (1963). “Seasonal Adjustment of Economic Time Series and Multiple Regression Analysis.” Journal of the American Statistical Association, 58(304), 993–1010.
-
Berge, L. (2018). fixest: Fast Fixed-Effects Estimations. R package. CRAN
-
Cunningham, S. (2021). Causal Inference: The Mixtape. Yale University Press. Online edition
-
Barro, R.J. and Sala-i-Martin, X. (2004). Economic Growth. 2nd edition. MIT Press.
Carlos Mendez
Associate Professor of Development Economics
My research interests focus on the integration of development economics, spatial data science, and econometrics to better understand and inform the process of sustainable development across regions.