What Does TWFE Actually Do?
Manual demeaning, OLS, and the Frisch–Waugh–Lovell theorem
−0.055286same coefficient, two routes
3.05e−16max difference · machine epsilon
1,200150 countries × 8 periods
Nagoya University (GSID)
July 8, 2026
Two completely different R commands return the same coefficient
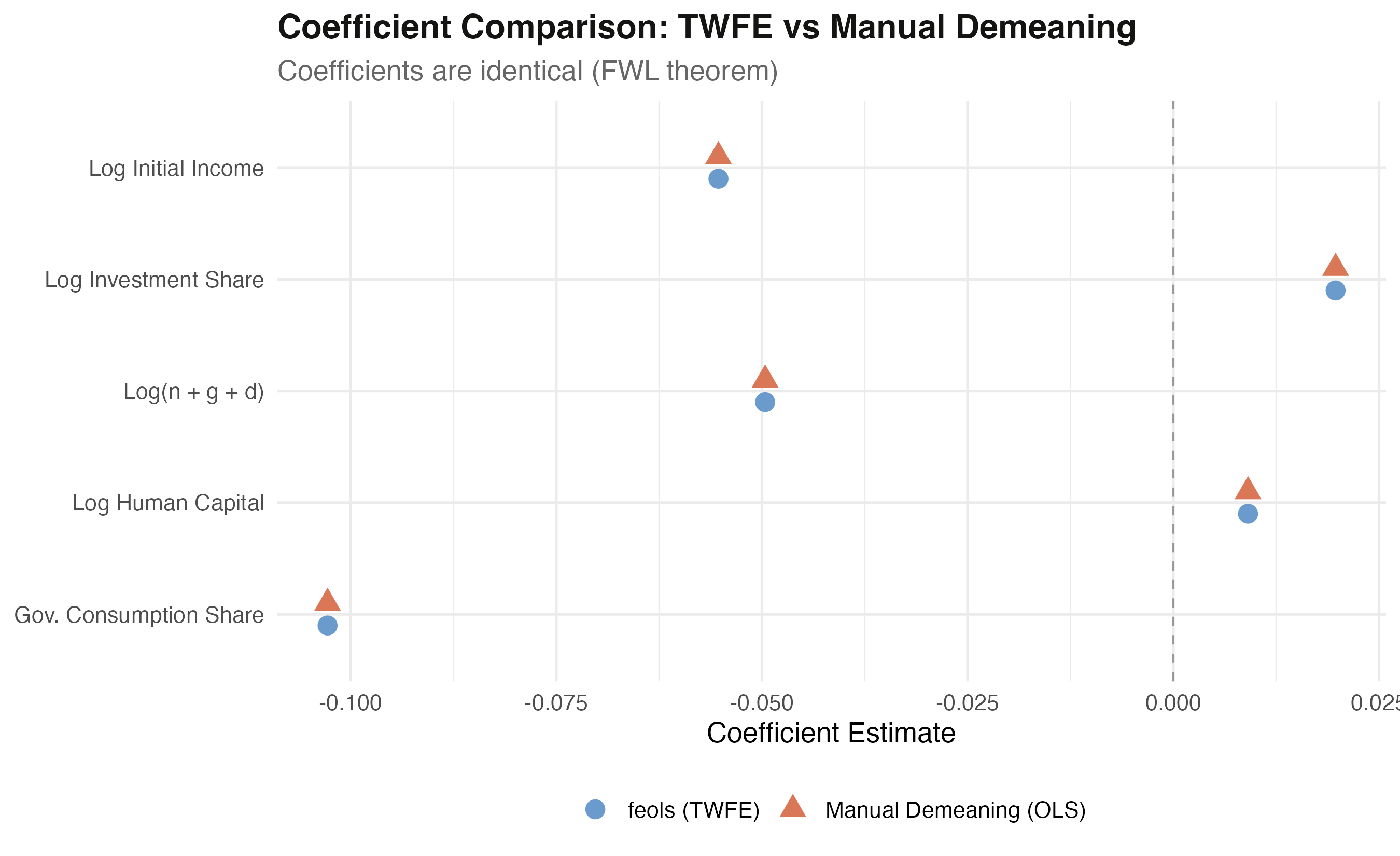
feols TWFE (blue circles) and manual-demeaning OLS (orange triangles) land on the exact same five positions.
The lab: 150 countries, 8 periods, every cell filled
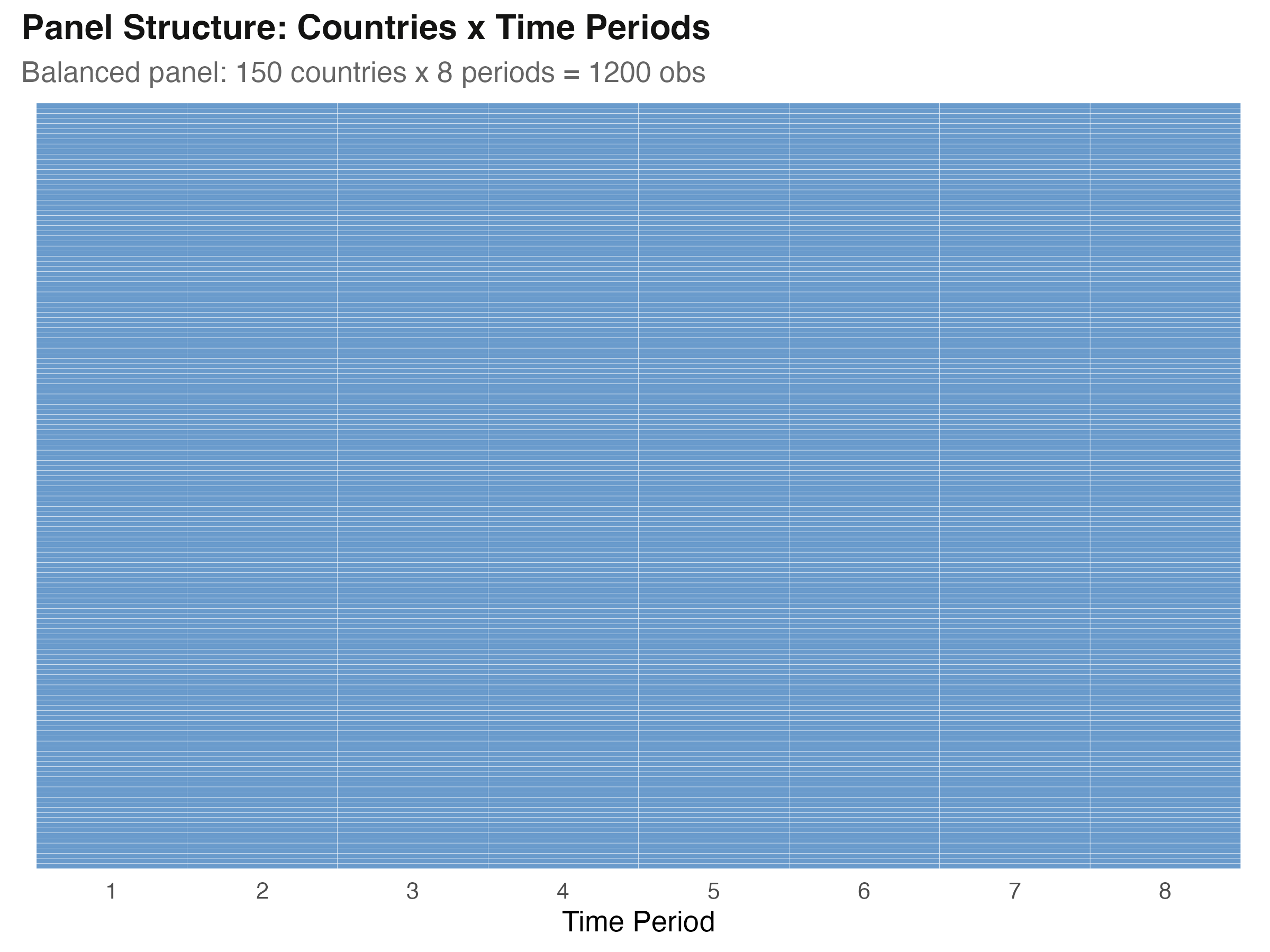
Every one of 150 countries appears in all 8 periods — a perfectly balanced 1,200-row panel.
Demeaning is the picture: wide spread collapses to within-variation
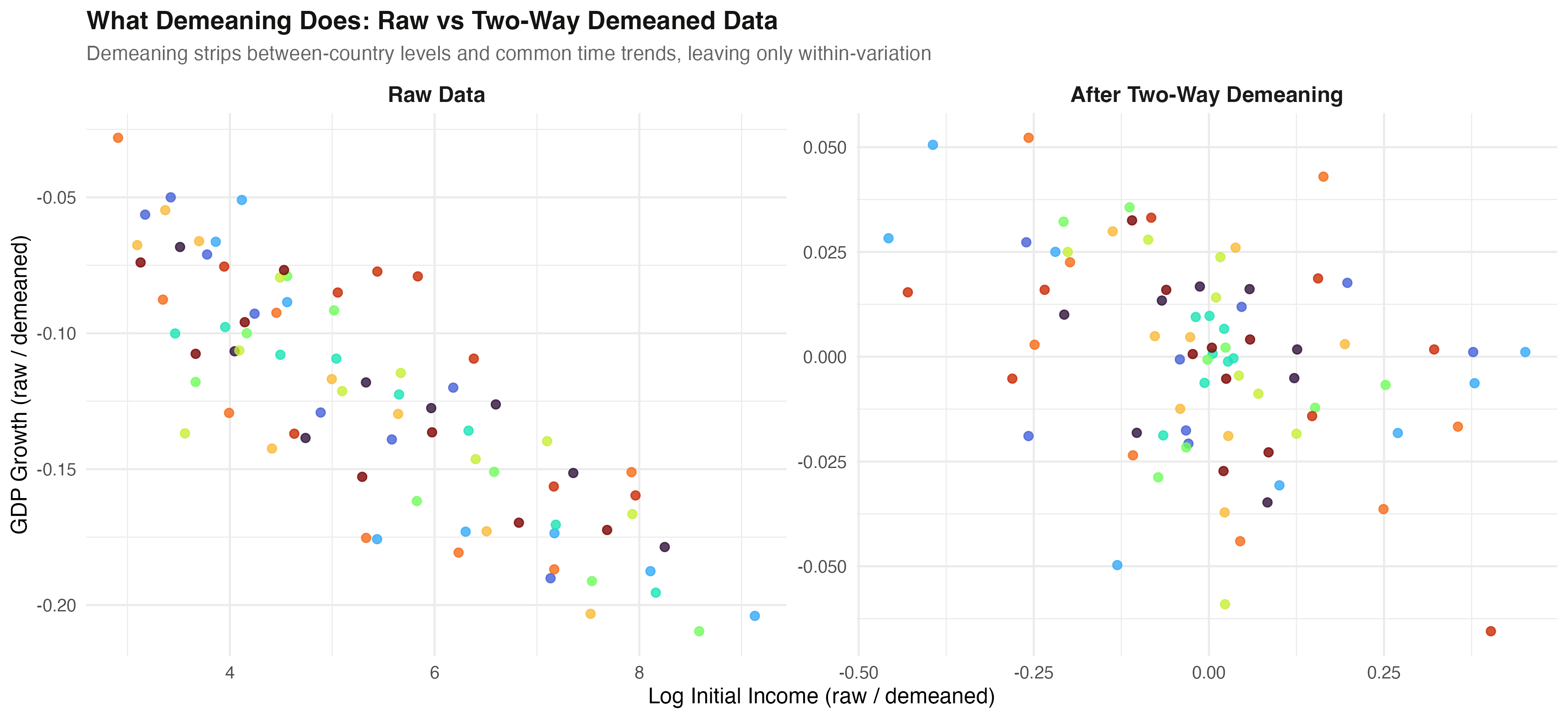
Raw cross-country spread on the left (x from ~3 to 9); after two-way demeaning, the same data compresses to roughly −0.5 to 0.3 around zero.
Inside one country: observed minus two means, plus the grand mean
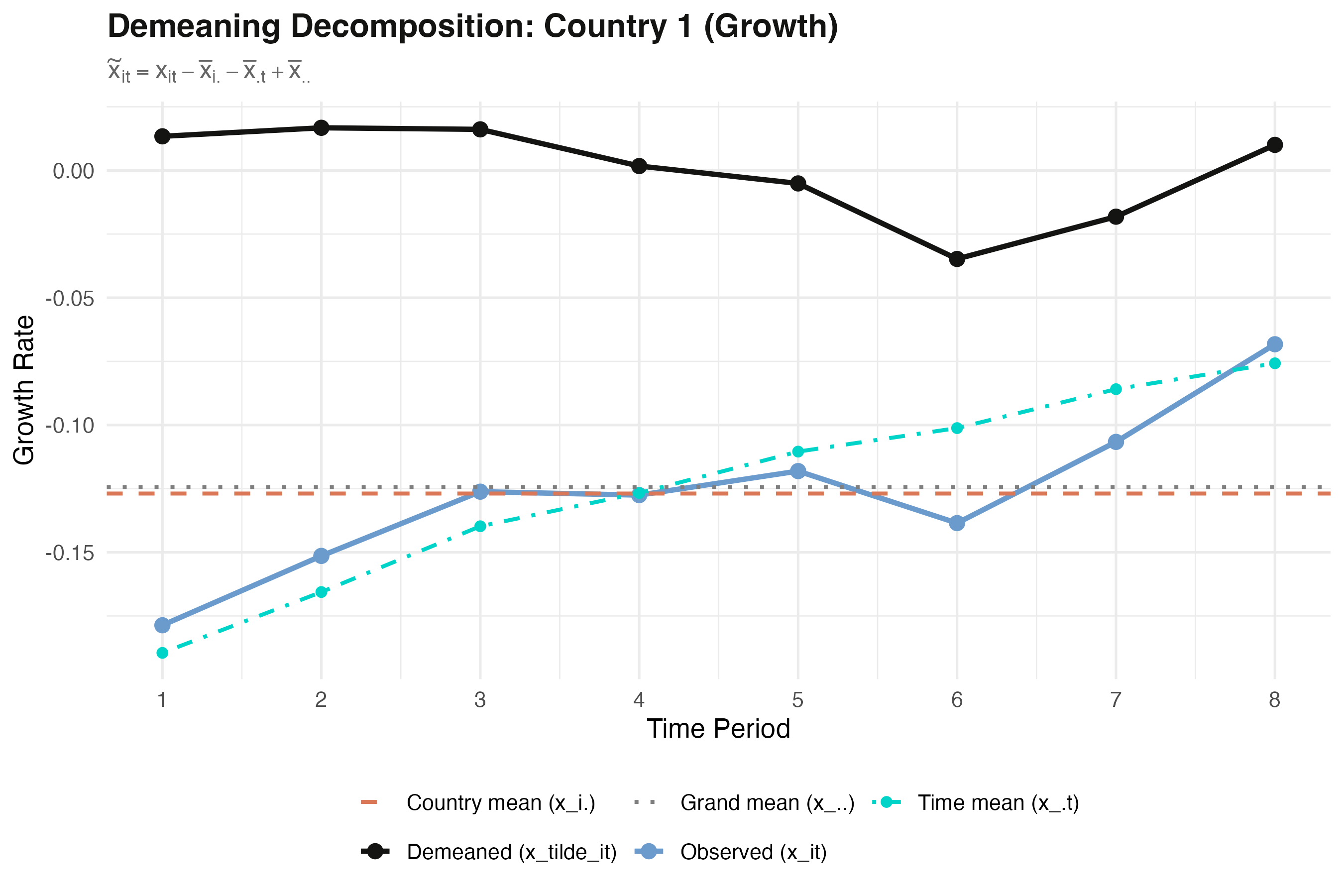
Country 1: observed growth (blue), country mean (orange dashed), time means (teal), grand mean (gray), and the demeaned residual (black) fluctuating around zero.
The catch: identical coefficients, but lm() standard errors are too small
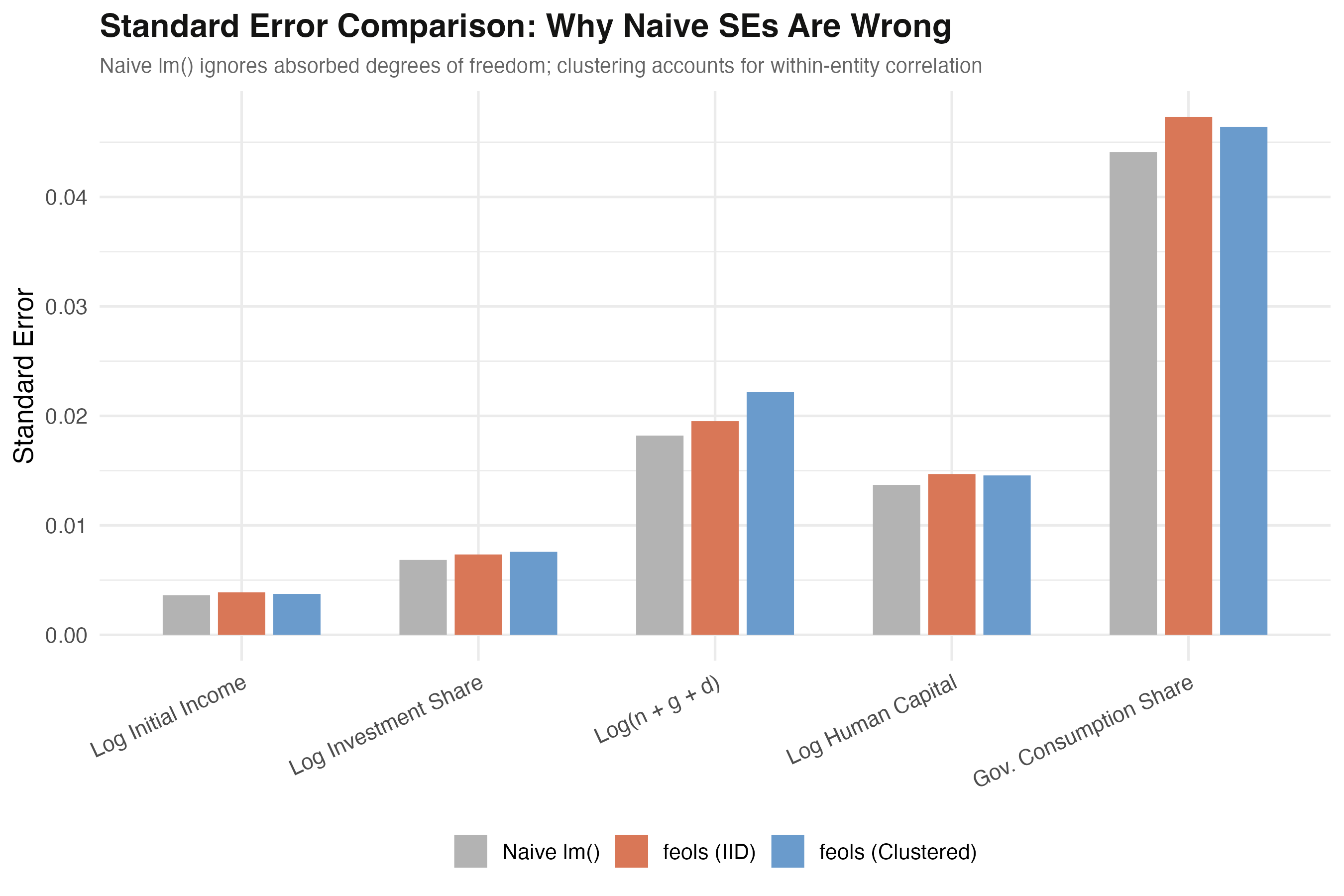
For every regressor the naive lm() bar (gray) is shorter than feols IID (orange) and clustered (blue).