DiD with Geocoded Microdata
When distance defines treatment: the ring design
Nagoya University (GSID)
July 8, 2026
One number hides the story: −5.78% on average, but −20.6% within 300 feet
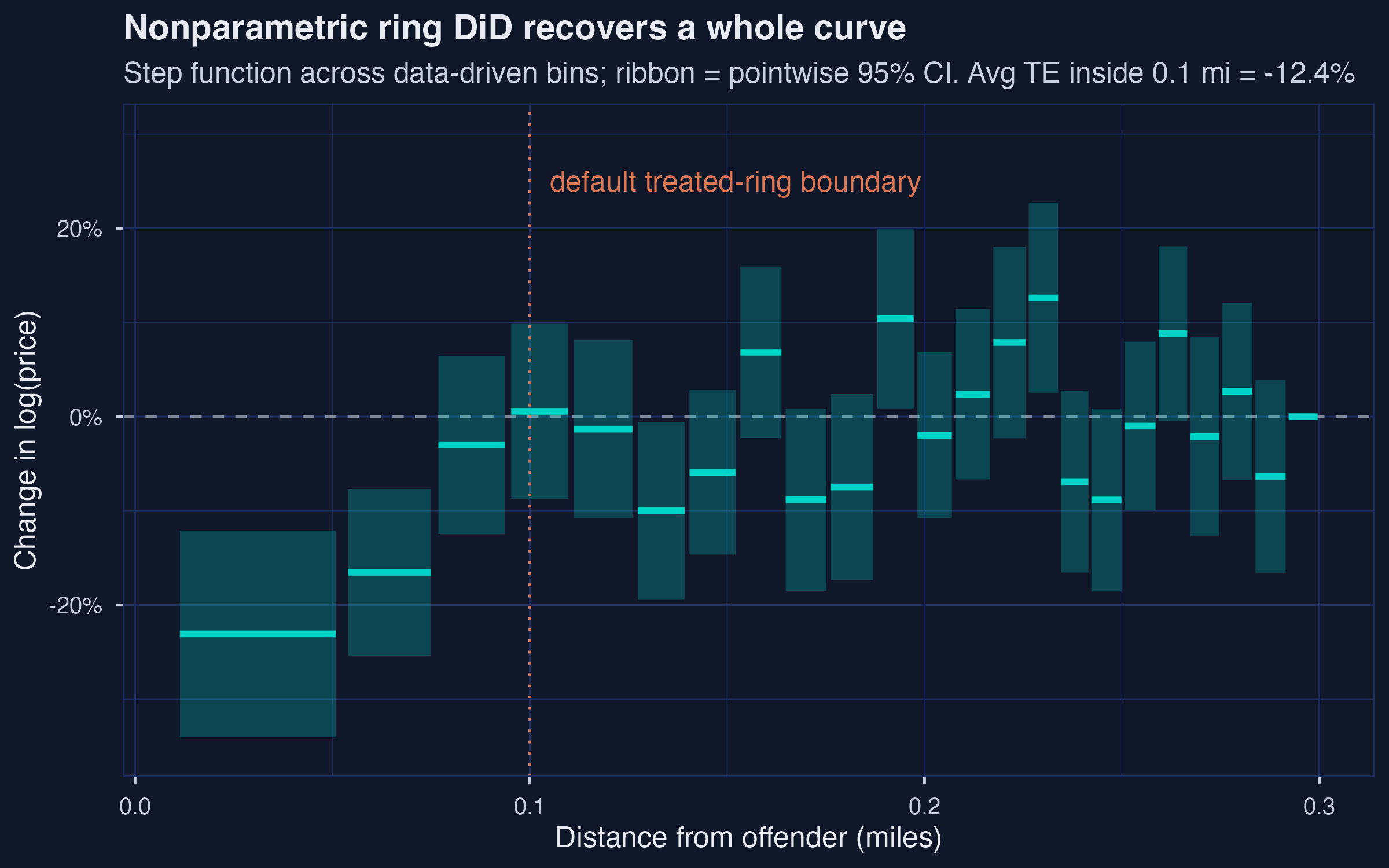
Nonparametric ring DiD on Linden-Rockoff: 23 bins; two closest bins at −20.6% and −15.2%; the curve crosses zero at \(d \approx 0.094\) mi.
Distance buys identification but spends sample: 6% treated, 28% control, 65% dropped

Toy ring geometry: 126 treated, 566 control, 1,308 dropped out of 2,000 random points.
Build a world where the truth is known: \(\tau(d)\) vanishes exactly at 0.75 mi
\[\tau(d) = 1.5 \cdot \exp(-2.3\, d) \cdot \mathbf{1}\{d \le 0.75\}\]
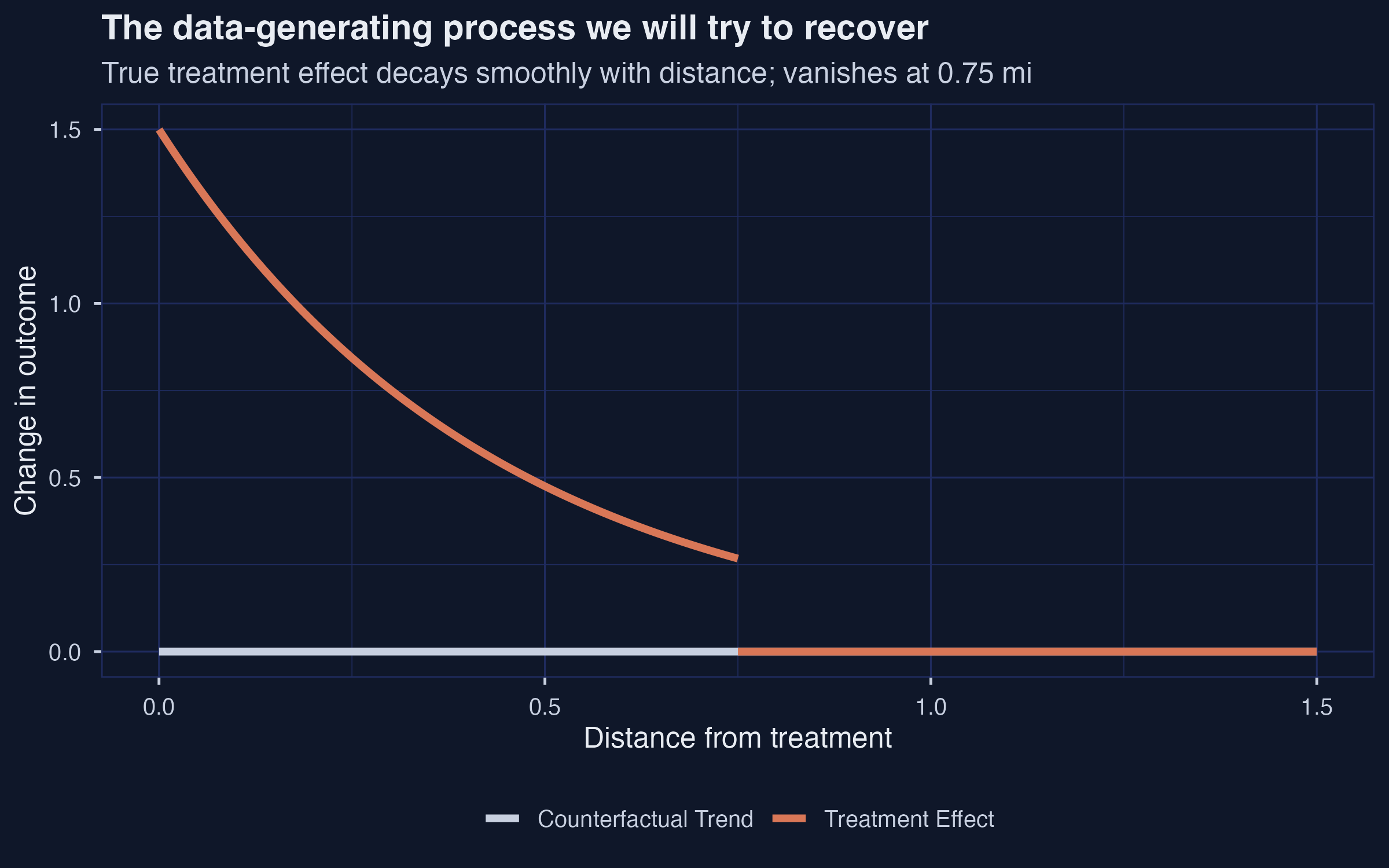
True treatment-effect curve: \(\approx 1.5\) at the point, decaying smoothly, zero past 0.75 mi; mean over the affected region \(= 0.726\).
With the correct radius, the parametric estimator nails the truth: 0.726
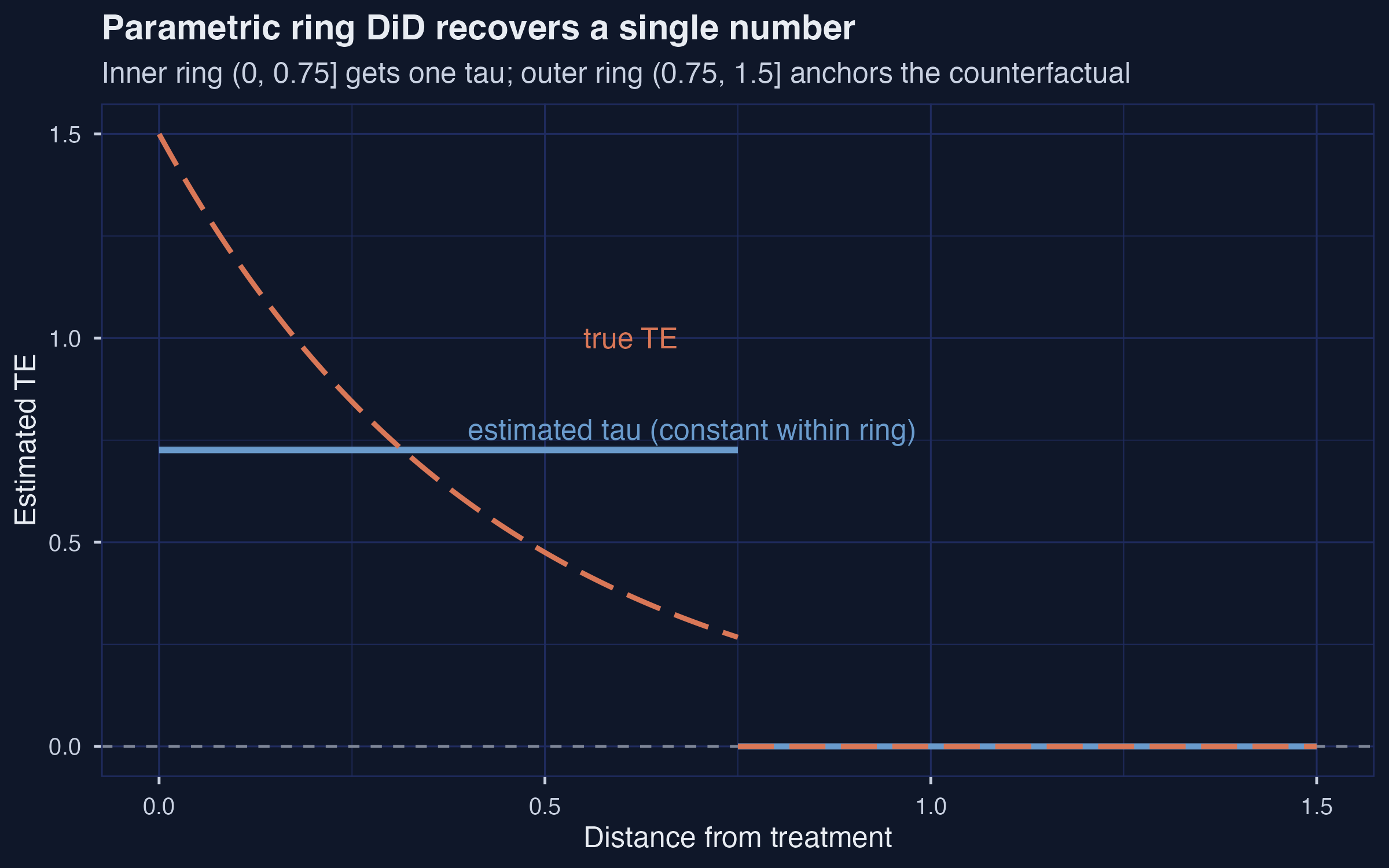
Parametric ring DiD at the correct cutoff recovers the truth: \(\hat\tau = 0.726\), 95% CI \([0.716, 0.736]\).
Same data, three radii, three answers: 0.913 / 0.726 / 0.456
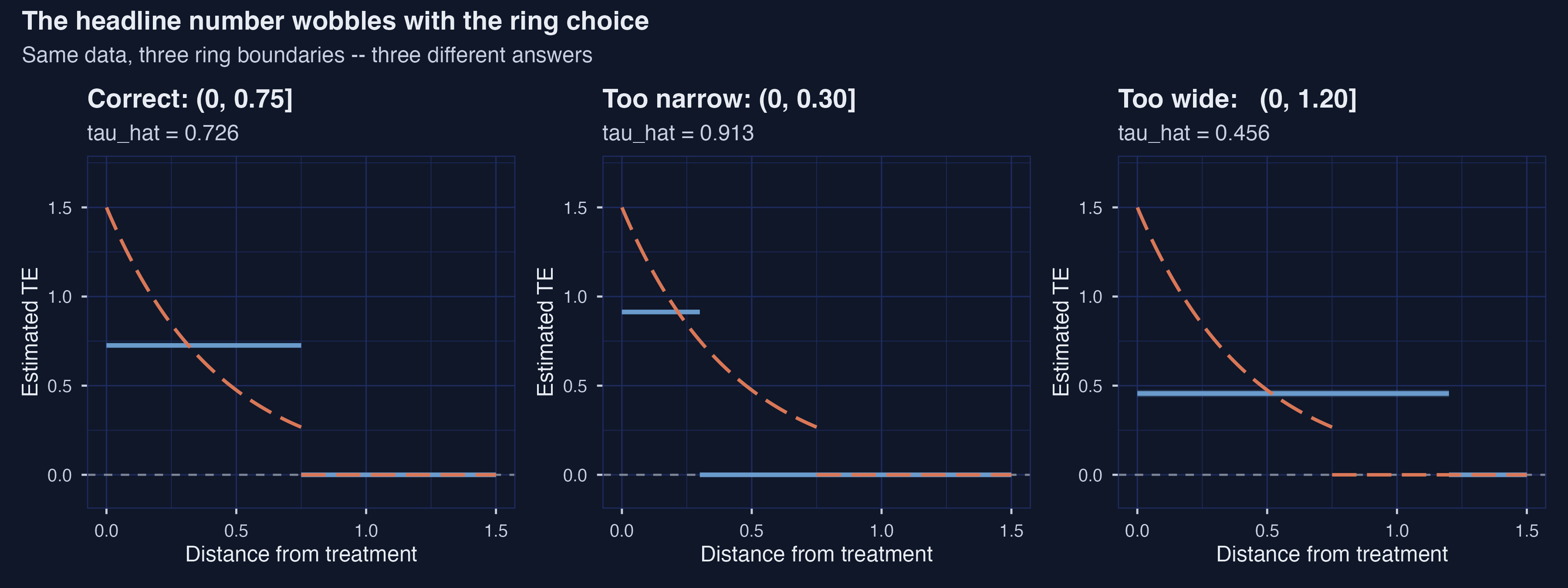
Same data, three ring choices: 0.913 (too narrow), 0.726 (correct), 0.456 (too wide). Both bad-case 95% CIs exclude the truth.
| Choice | \(\hat\tau\) | Bias |
|---|---|---|
| Too narrow (0, 0.30] | 0.913 | +25.7% — averages the steepest slice |
| Correct (0, 0.75] | 0.726 | none |
| Too wide (0, 1.20] | 0.456 | −37.1% — dilutes with zero-effect units |
Let the data choose: partition distance into bins and trace the whole curve
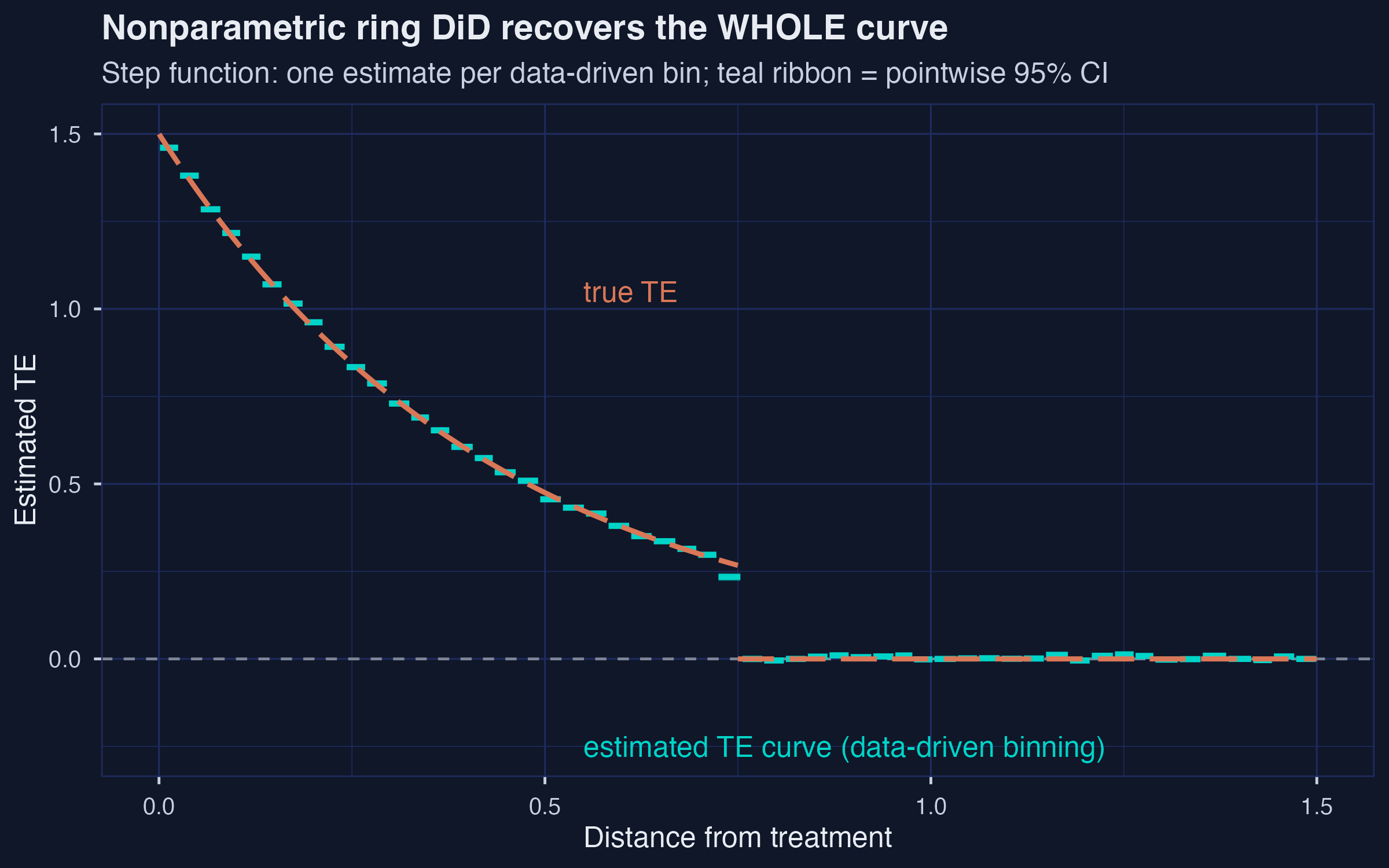
The nonparametric estimator recovers the whole TE curve — 53 quantile-spaced bins, no cutoff committed up front; left-most bin \(\hat\tau = 1.461\) vs truth 1.5.
Eyeballing the cutoff is the same fragility in disguise — three bandwidths, three radii
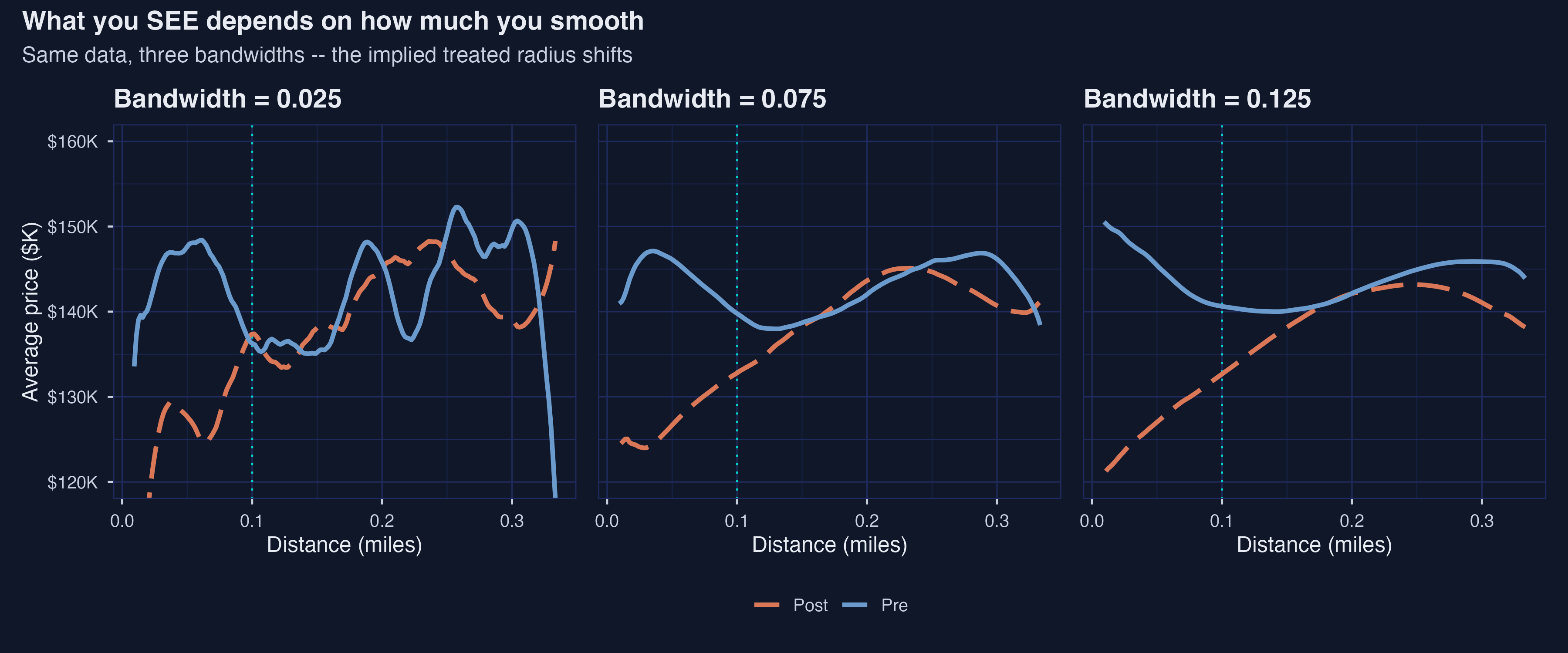
Same data, three smoothing bandwidths — the implied treated radius shifts from ~0.10 mi (bw 0.025) to ~0.20 mi (bw 0.125).
Redraw the radius and the headline wobbles 52% — the sign holds, the magnitude doesn’t
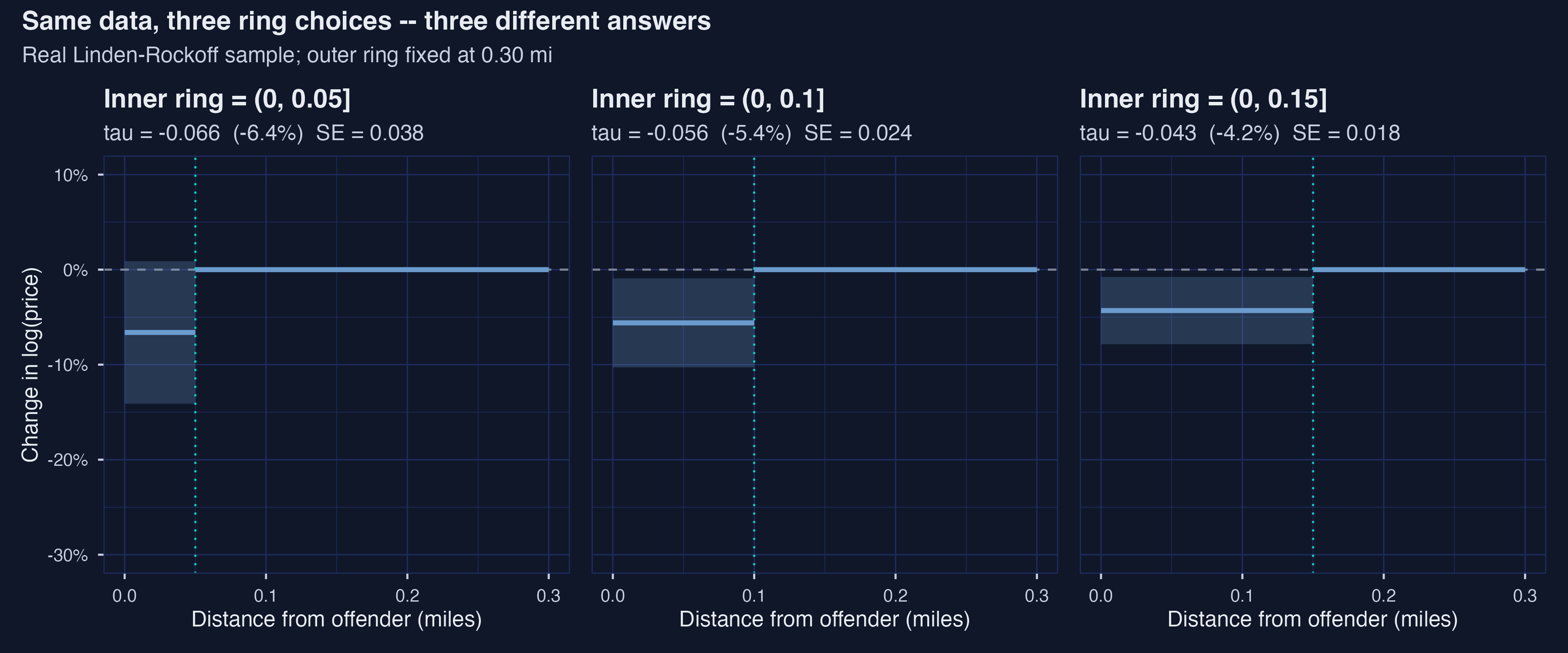
Three inner-ring cutoffs on the same data: ATT moves from −6.40% (0.05 mi) to −4.21% (0.15 mi) — a 52% relative spread driven entirely by the cutoff.
| Cutoff | ATT (%) | 95% CI |
|---|---|---|
| 0.05 mi | −6.40% | \([-14.1\%, +0.9\%]\) |
| 0.10 mi | −5.45% | \([-10.3\%, -0.9\%]\) |
| 0.15 mi | −4.21% | \([-7.8\%, -0.8\%]\) |