Dynamic Panel BMA
Which factors truly drive economic growth — once reverse causality is handled?
Nagoya University (GSID)
July 8, 2026
BMA grades each variable on a continuous PIP scale — population leads at 0.990
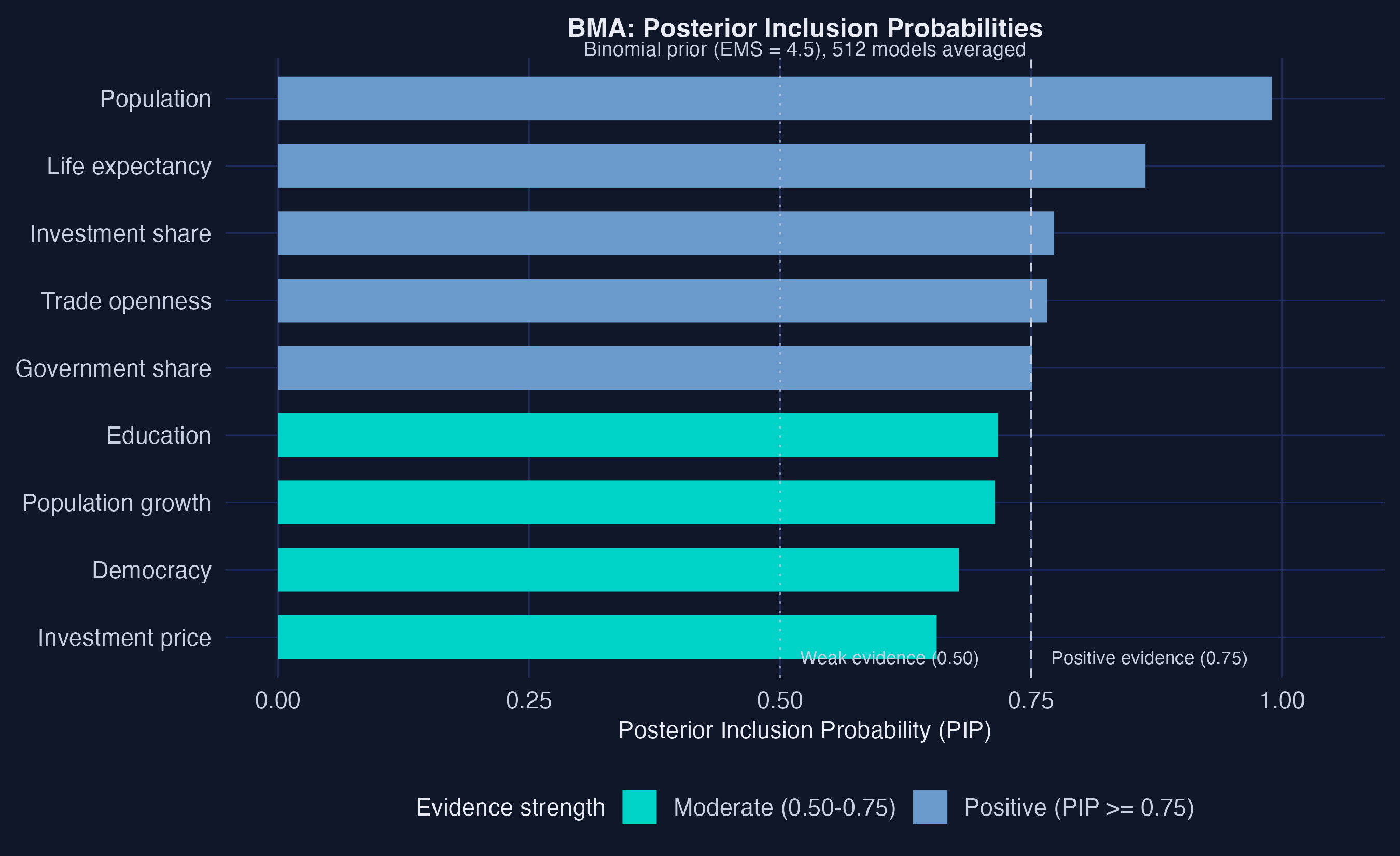
Posterior Inclusion Probabilities, all 9 regressors, sorted with the 0.75 and 0.50 threshold lines.
The data concentrates posterior mass on a few large models
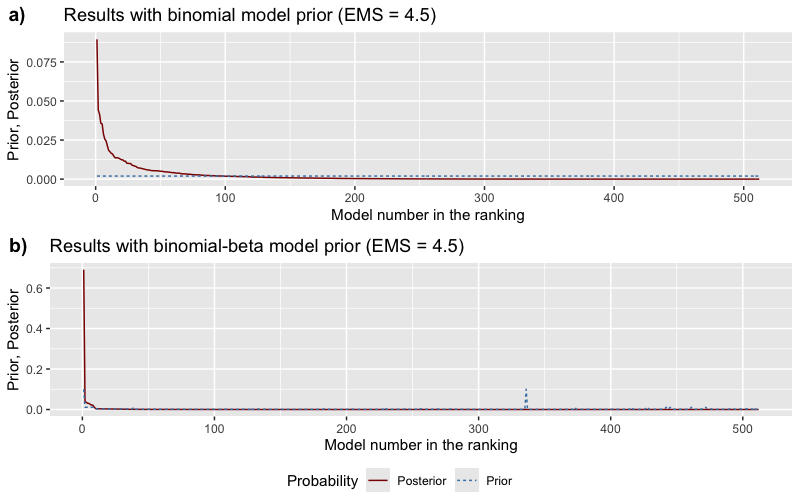
Prior (flat, dashed) vs posterior (concentrated, solid) probability across all 512 models.
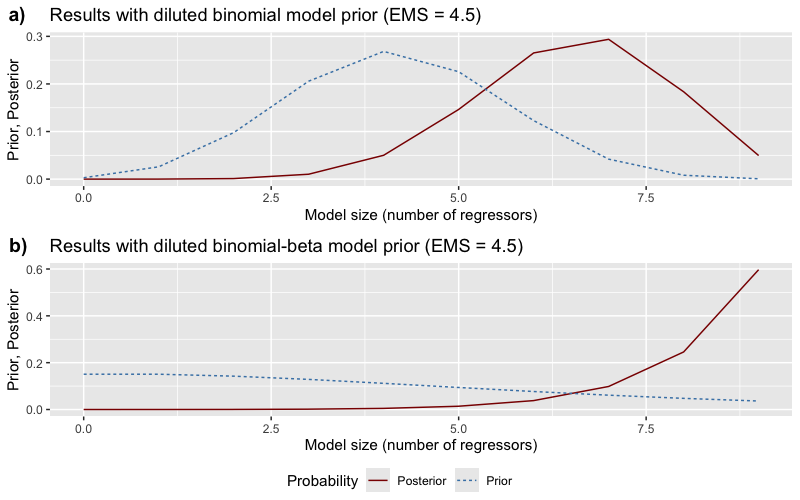
The posterior wants big models — expected size jumps from 4.5 to ~7
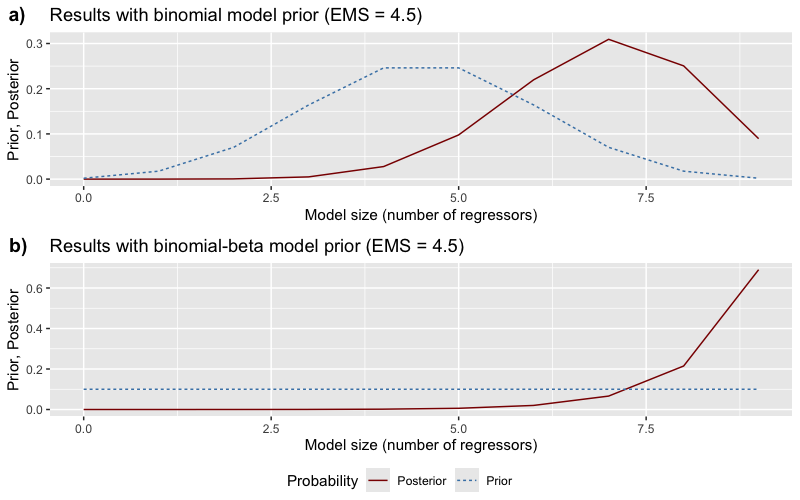
Prior vs posterior distribution over model sizes (regressors excluding the lagged outcome).
Posterior coefficients: population and life expectancy clear zero cleanly
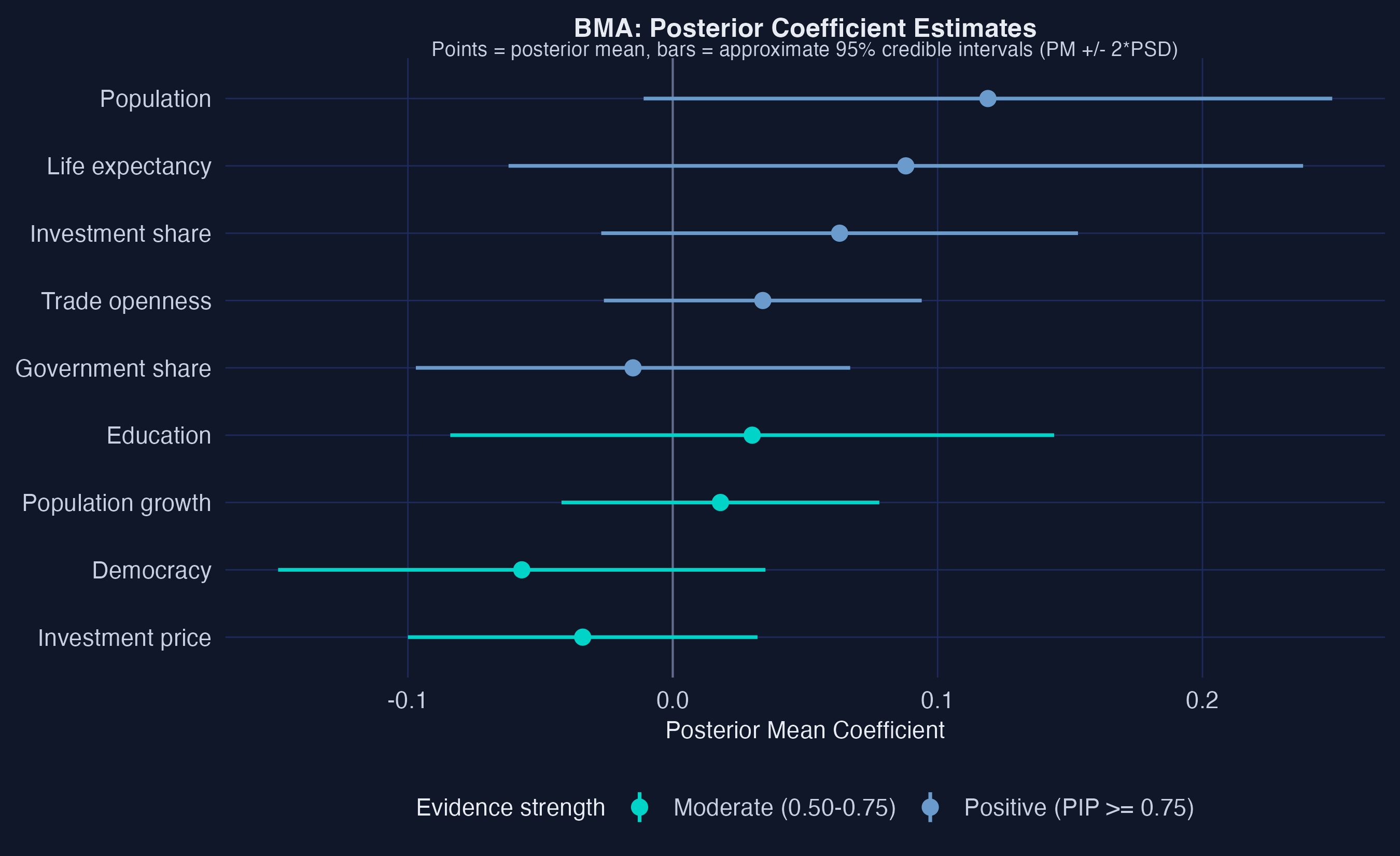
Posterior means with approximate 95% credible intervals (\(\text{PM} \pm 2\cdot\text{PSD}\)) for all 9 regressors.
Population’s coefficient is tight, positive, and centered near 0.12
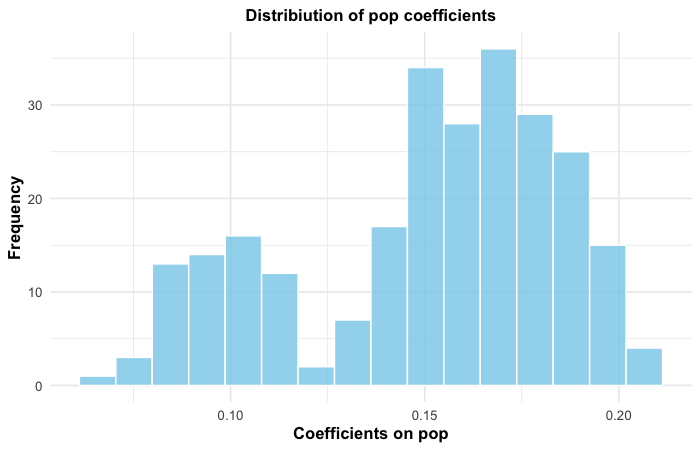
Posterior coefficient distribution for population across all 512 models, weighted by model probability.
A skeptical prior is the real test — only population and life expectancy survive it
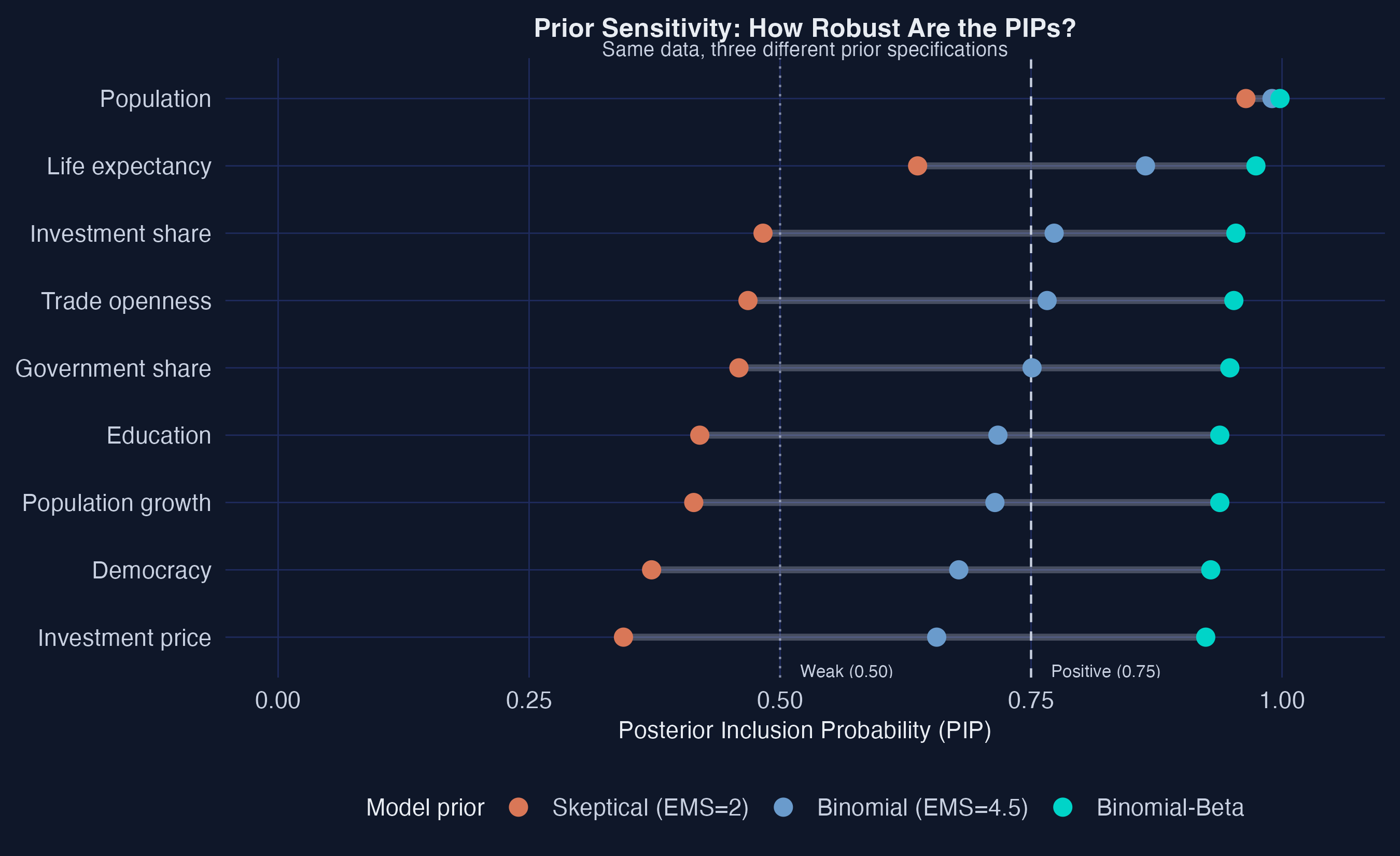
PIPs under three priors (skeptical EMS=2, binomial, binomial-beta). Segment width = sensitivity.
A dilution prior penalizes redundant controls — the ranking holds
Model sizes under the dilution prior (penalizing correlated regressors); expected size falls 6.91 → 6.53.