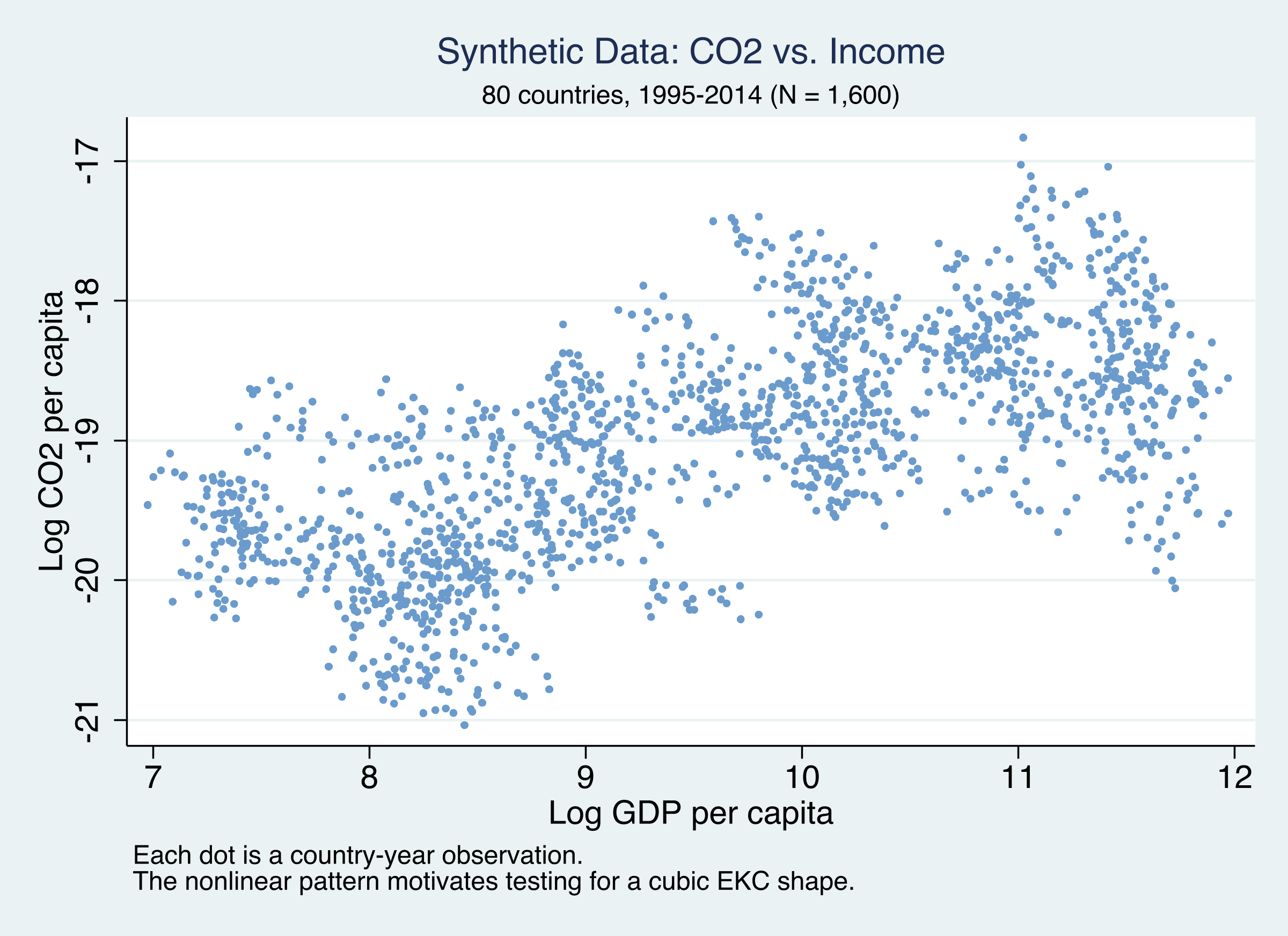
A cubic in log GDP \(G\) gives the inverted-N; \(\alpha_i\) and \(\delta_t\) absorb country and year heterogeneity; \(\mathbf{X}^{\text{true}}\) is the 5 controls we must rediscover.
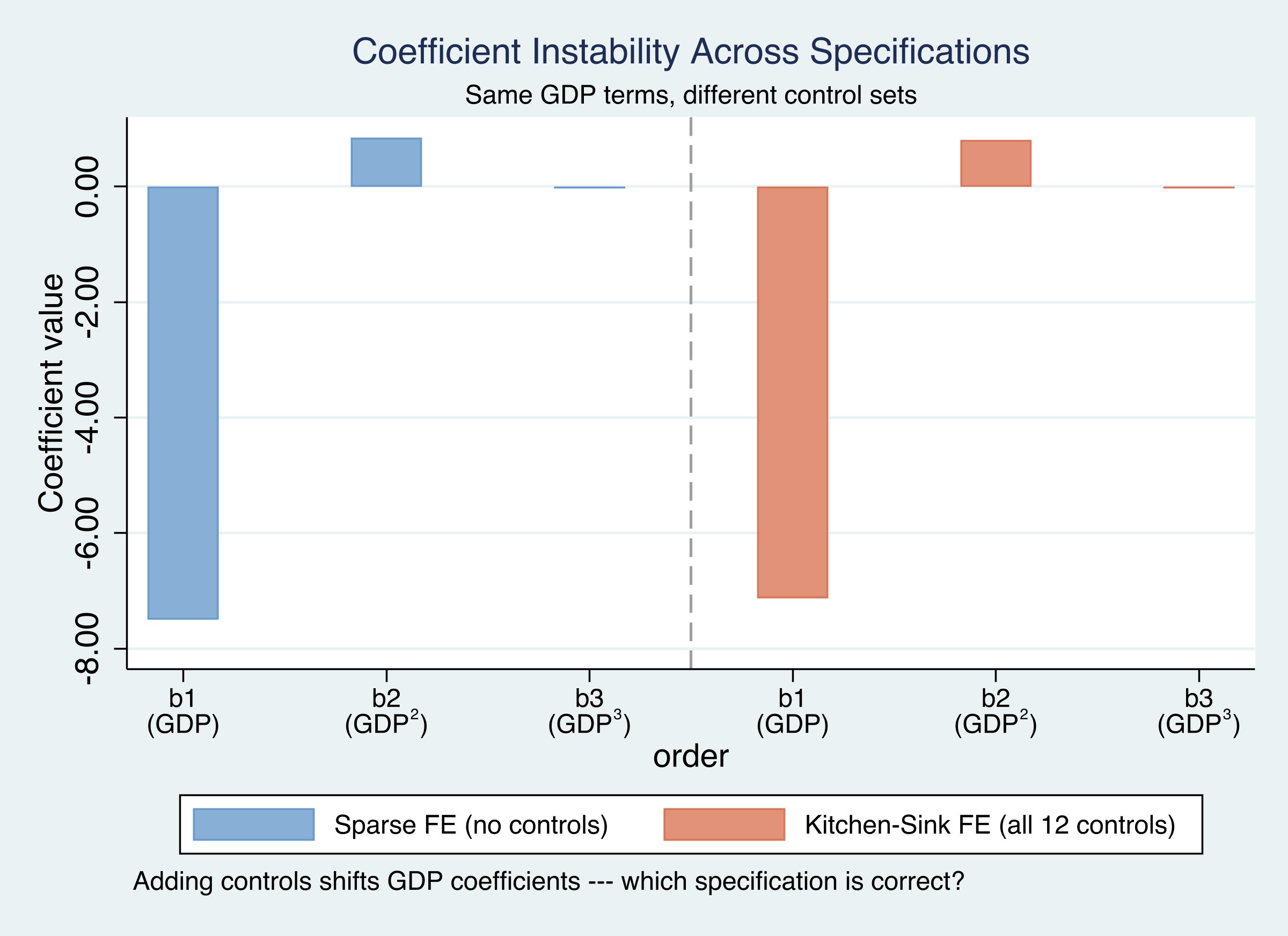
Adding all 12 controls shifts the GDP coefficient — yet still won’t say which controls belong
GDP polynomial coefficients shift between the sparse and kitchen-sink fixed effects specifications — the visible signature of model uncertainty.
BMA averages over all 4,096 models and weights each by how well it fits
Each model’s weight is its fit (marginal likelihood) times its prior. Better-fitting, parsimonious models earn more weight — BMA’s built-in Occam’s razor.
Instead of betting on one horse, BMA spreads bets across the whole field.
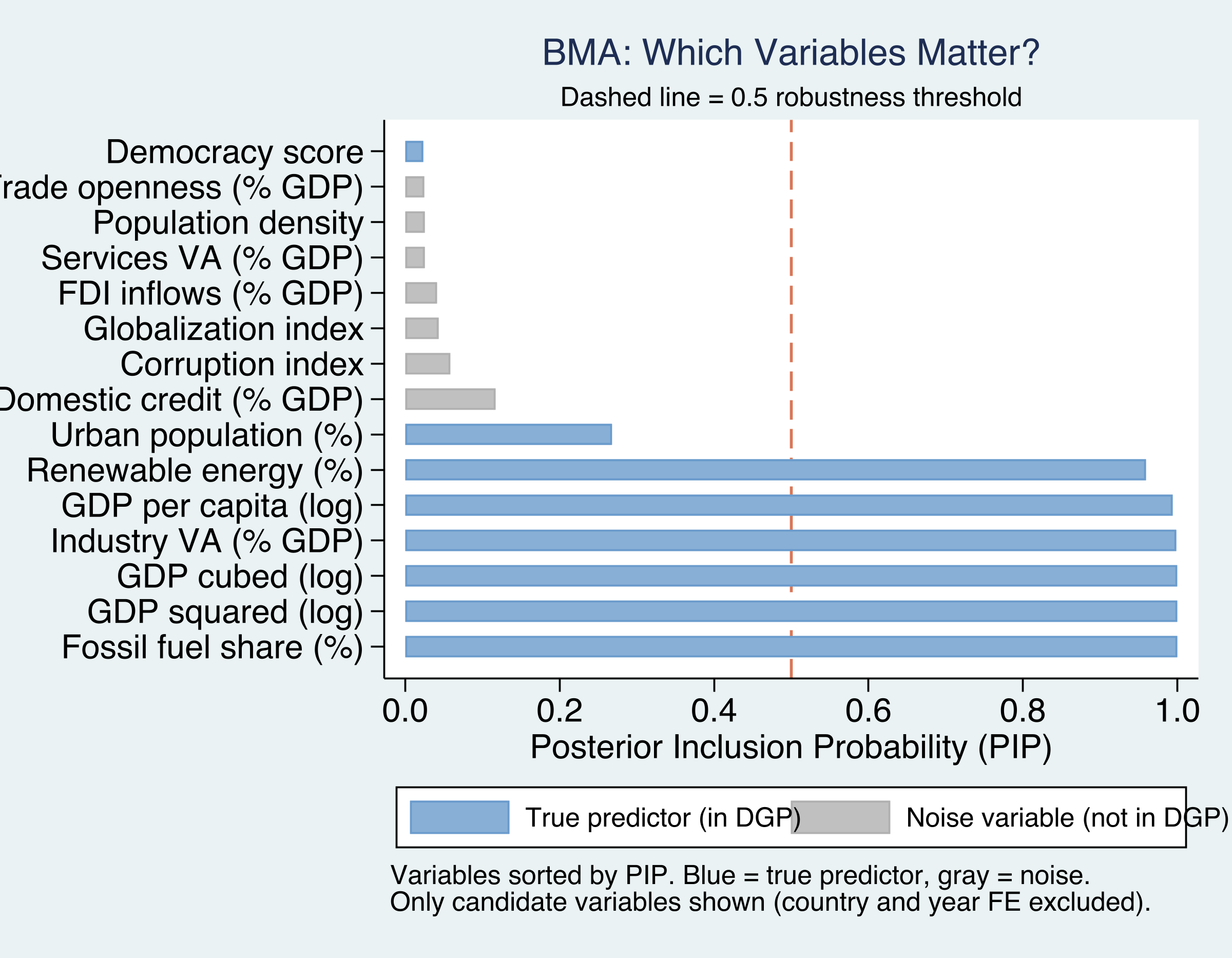
The PIP is a democratic vote: what share of good models keep a variable?
A variable in every high-probability model has \(\text{PIP} \to 1\); one only in long-shot models stays near 0. We treat \(\text{PIP} \geq 0.80\) as “robust.”
Six lines of Stata run BMA with fixed effects always in the model
($fe, always) forces country and year FE into every model; groupfv moves the 80 country dummies as one package, not 80 independent choices.
BMA recovers the GDP coefficient almost exactly — −7.139 vs true −7.100
−7.139
BMA posterior mean on \(\beta_1\) · true DGP value −7.100; cubic term −0.030 matches the truth exactly
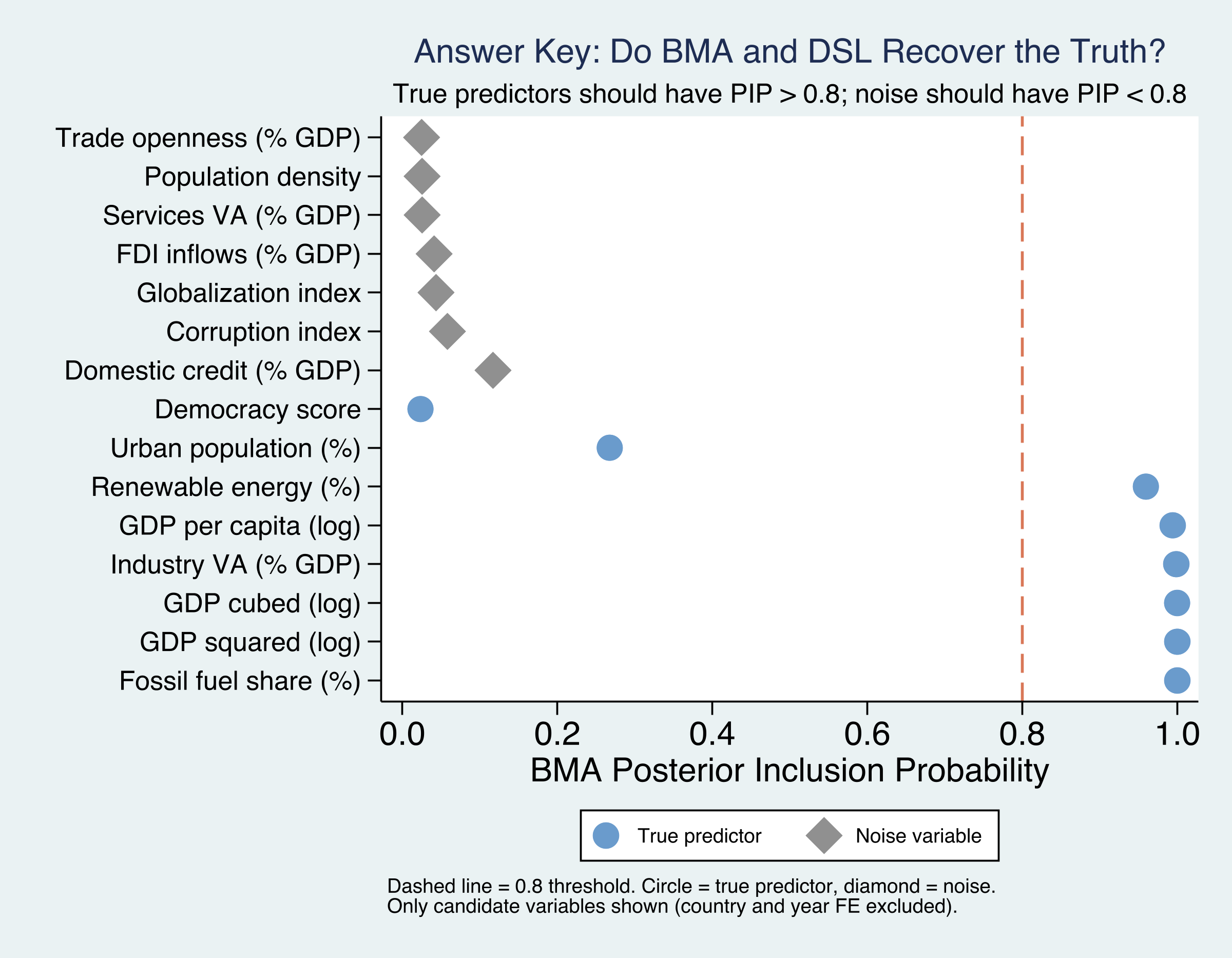
BMA flags 6 of 8 true predictors and zero noise — the answer key confirmed
PIPs for all 15 variables: true predictors (steel blue) clear the 0.80 line; all 7 noise variables (gray) sit near zero.
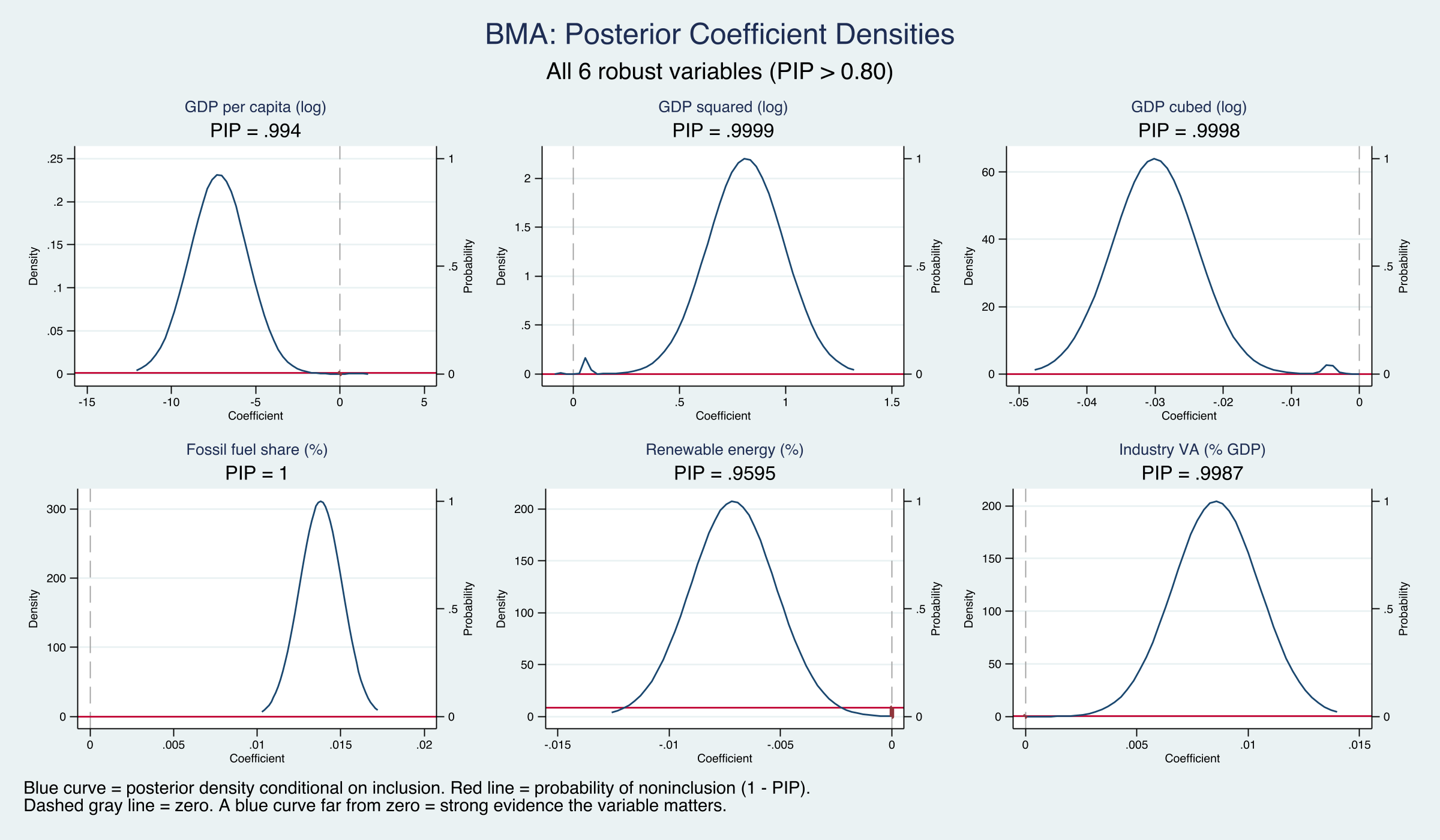
The posterior densities sit far from zero — strong evidence for all six robust variables
Posterior coefficient densities for the six PIP > 0.80 variables. Top row: GDP linear, squared, cubic. Bottom: fossil fuel, renewable, industry. All concentrated away from zero.
DSL takes a different road: select controls twice, then run a clean OLS
LASSO on the outcome (\(\hat S_Y\)) and on each GDP term (\(\hat S_{D_k}\)); the union is the safety net; then OLS on that union.
The second selection catches a confounder the outcome-LASSO would miss — that is the “double.”
With fixed effects, DSL gives fast, valid estimates — −7.433 in seconds
Coefficient
DSL (FE)
True DGP
Significant?
\(\beta_1\) (GDP)
−7.433
−7.100
yes
\(\beta_2\) (GDP\(^2\))
0.840
0.810
yes
\(\beta_3\) (GDP\(^3\))
−0.031
−0.030
yes
Cluster-robust SEs, four internal LASSOs, union, then OLS — all in seconds. Wald \(\chi^2 = 53.15\), \(p < 0.001\).
Strip the fixed effects and the GDP coefficient explodes to −21.26
−21.26
Pooled BMA \(\beta_1\) (no FE) · 3× the true −7.100; pooled DSL agrees at −22.03
Worse, pooled BMA hands robust status to 5 noise variables
With fixed effects
6 variables clear PIP \(\geq 0.80\)
all 7 noise → PIP \(\approx 0\)
zero false positives
intervals cover the truth
Pooled (no FE)
12 of 15 clear PIP \(\geq 0.80\)
services, credit, pop. density → PIP = 1.000
5 false positives
intervals miss the truth, all 3 terms
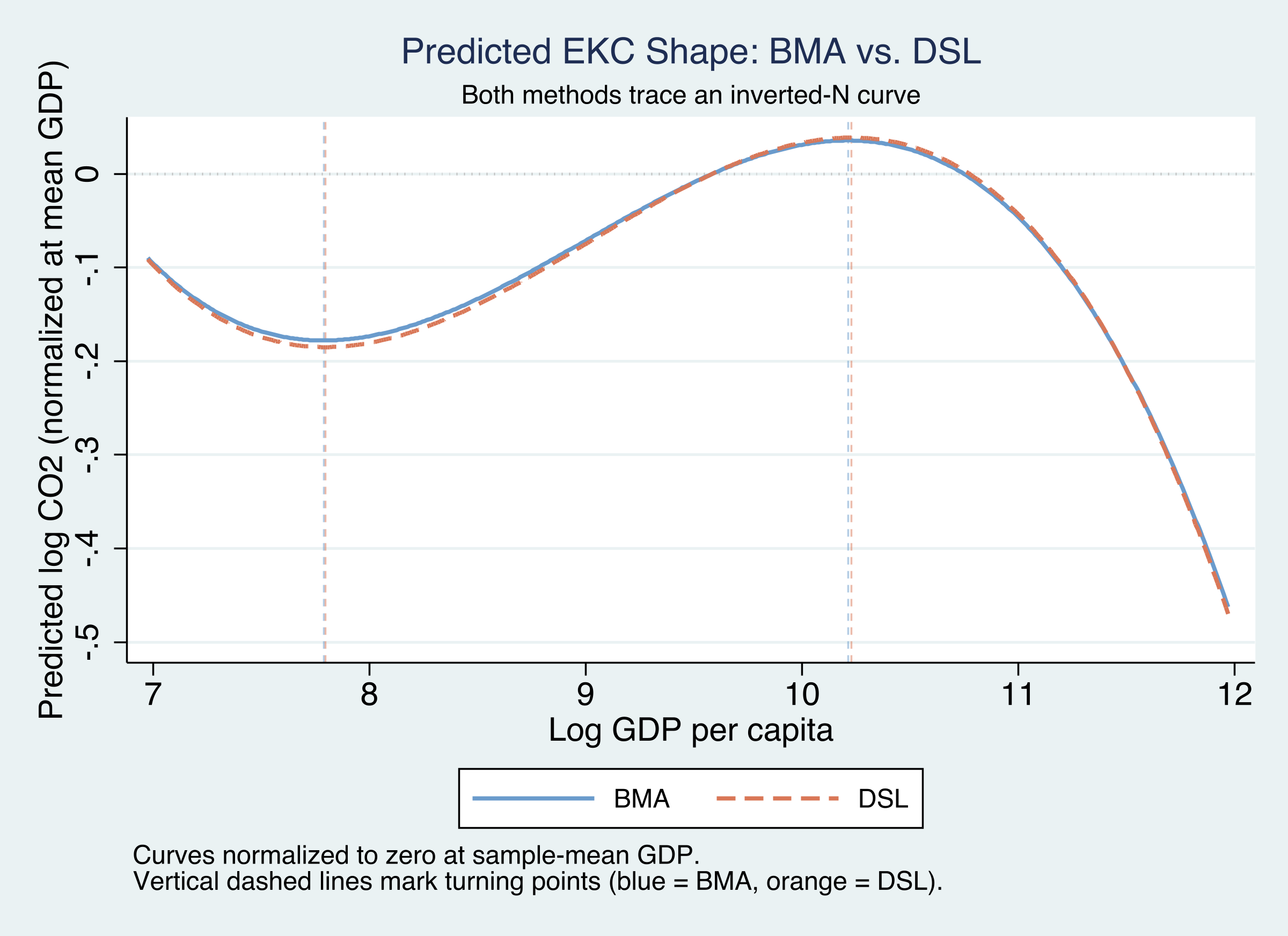
Both curves trace the same inverted-N — BMA and DSL agree on the shape
Predicted EKC curves (normalized at mean GDP): BMA (solid blue) and DSL (dashed orange) are nearly indistinguishable, with closely aligned turning points.
Does machine selection make this causal? No — it disciplines, it does not identify
Objection. “BMA and LASSO pick controls automatically — surely that delivers the causal effect of income on emissions.”
Response. No. These are model-uncertainty tools, not identification tools. They tame which controls enter and report honest robustness (PIPs, valid SEs). Identifying a causal EKC still needs the usual assumptions — and the synthetic answer key grades recovery of a known DGP, not a real-world causal claim.
The Resolution
Act III
The verdict: 6 of 8 true predictors recovered, zero false positives — with fixed effects