The average effect among households whose covariates equal\(\mathbf{x}\). Where \(\tau(\mathbf{x})\) bends with \(\mathbf{x}\), the program helps some households more than others.
The single ATE is just \(E[\tau(\mathbf{X})]\) — the CATE averaged over the population.
Two assumptions do the causal work — the forest only fits the function
Unconfoundedness
\[y(1),y(0) \perp d \mid \mathbf{x}\]
No unmeasured confounders given the covariates
Justified here by a rich demographic vector
Overlap
\[0 < \Pr(d=1\mid \mathbf{x}) < 1\]
Every profile could be treated or not
37% / 63% split → comfortable overlap
Machine learning chooses controls flexibly; it cannot manufacture identification.
The lab: 9,913 households, eligibility → net financial assets
Outcome — net total financial assets ($), wildly right-skewed: mean $18,054, median just $1,499
assets3, the canonical Chernozhukov–Hansen excerpt shipped with Stata 19.
cate runs cross-fit lasso and a causal forest in one command
webuse assets3, clear* covariates driving the heterogeneity = nuisance controls hereglobal catecovars age educ i.incomecat i.pension i.married i.twoearn i.ira i.ownhomecate po (asset $catecovars) (e401k), rseed(12345671)
Lasso for the nuisance functions (cross-fitted), a generalized random forest for \(\tau(\mathbf{x})\), honest-tree bootstrap for the CIs — Stata 18 needed hand-rolled loops.
Two routes to the same object: PO is robust, AIPW is efficient
PO (partial-linear)
Residualize \(y\) and \(d\) on \(\mathbf{x}\), then regress
Transparent; robust when propensities near 0 or 1
ATE \(= \$7{,}937\)
AIPW (interactive)
Separate outcome models + propensity reweight
Doubly robust: only one nuisance model need be right
ATE \(= \$8{,}120\)
Both return a per-household effect function \(\hat\tau(\mathbf{x}_i)\) — they differ only in how they map nuisances into it.
Three estimators bracket the ATE within a $183 spread
$8,000
Parametric AIPW $8,019 · ML PO $7,937 · ML AIPW $8,120 — agreement across very different specifications
First, does the effect vary at all? The test says yes
Estimator
\(\chi^2(1)\)
\(p\)
Verdict
cate po
4.11
0.043
reject homogeneity
cate aipw
5.54
0.019
reject homogeneity
estat heterogeneity — \(H_0:\ \tau(\mathbf{x})\) is constant. Both reject at 5%, so the heterogeneity hunt is not chasing noise.
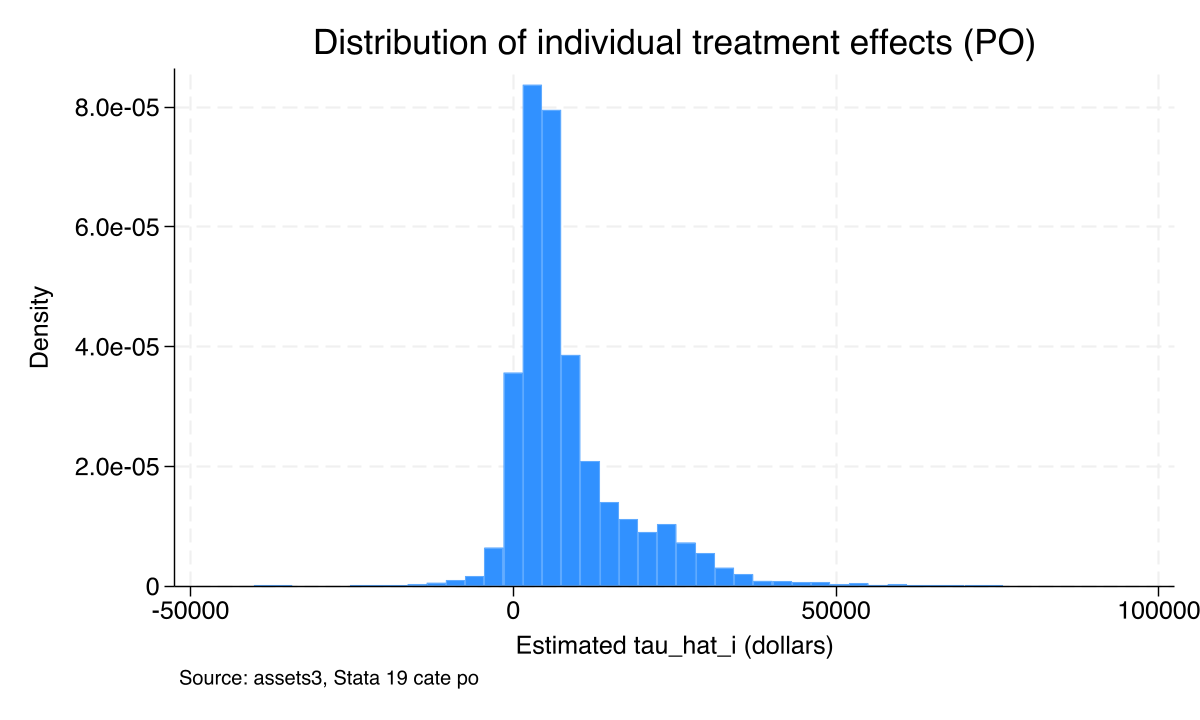
The average of $7,937 hides a long right tail of large effects
PO-estimated individual effects \(\hat\tau_i\) across 9,913 households: a tight mode near $5–10k, a tail past $80k, and a small mass near or below zero.
A linear projection of \(\hat\tau_i\) says income is the only strong signal
Covariate
Effect on \(\hat\tau_i\) ($)
\(p\)
Highest income category
+18,195
0.001
Homeowner
+3,163
0.058
Age (per year)
+205
0.082
Education (per year)
−442
0.365
estat projection: the only coefficient significant at 1% is the top income category. \(R^2=0.0045\) — most heterogeneity is nonlinear, captured by the forest, not the projection.
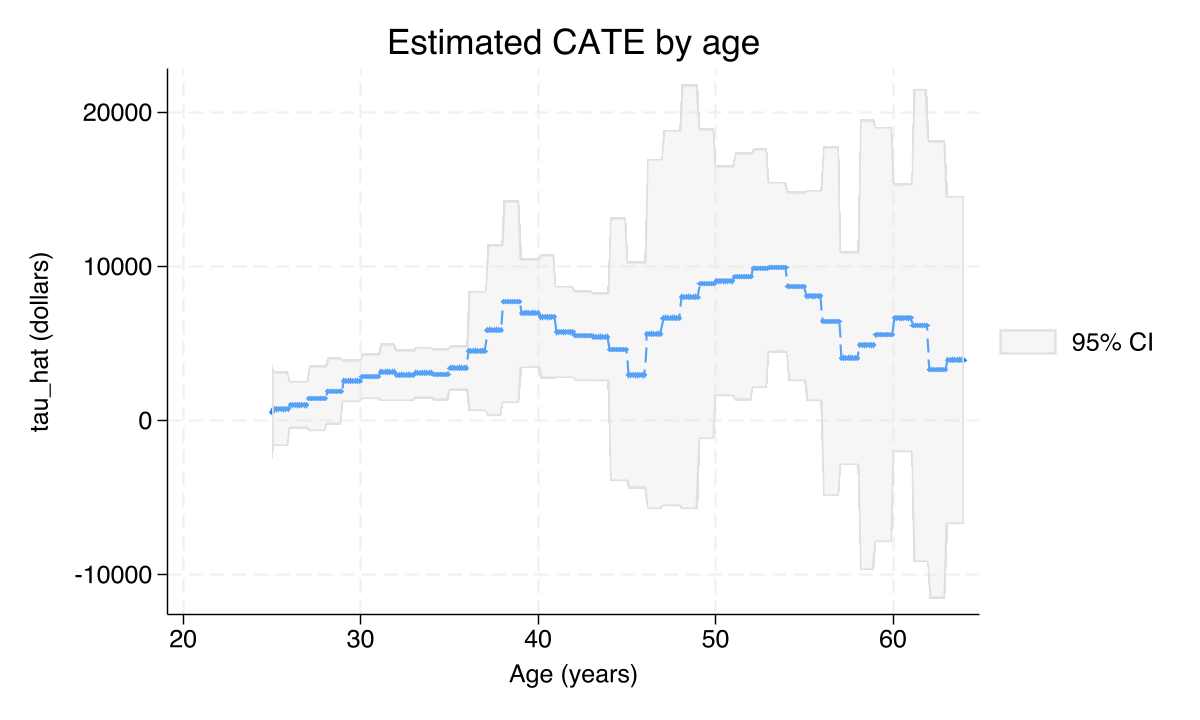
Effects climb with age; education barely moves them
PO-estimated CATE by age (others fixed at means): slightly negative in the mid-20s, clearly positive by 35–40, still rising through the 50s.
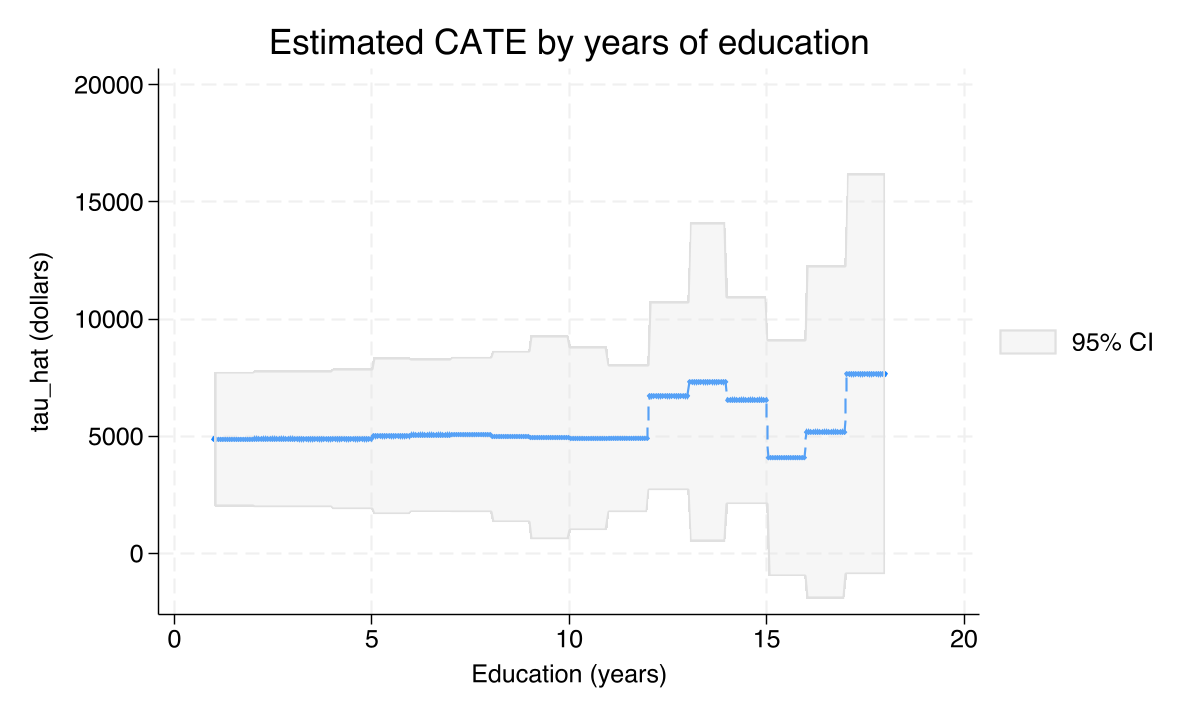
Education is a flat line — once you know income, it adds nothing
PO-estimated CATE by years of education: broadly flat around $1–3k from 8 to 18 years of schooling.
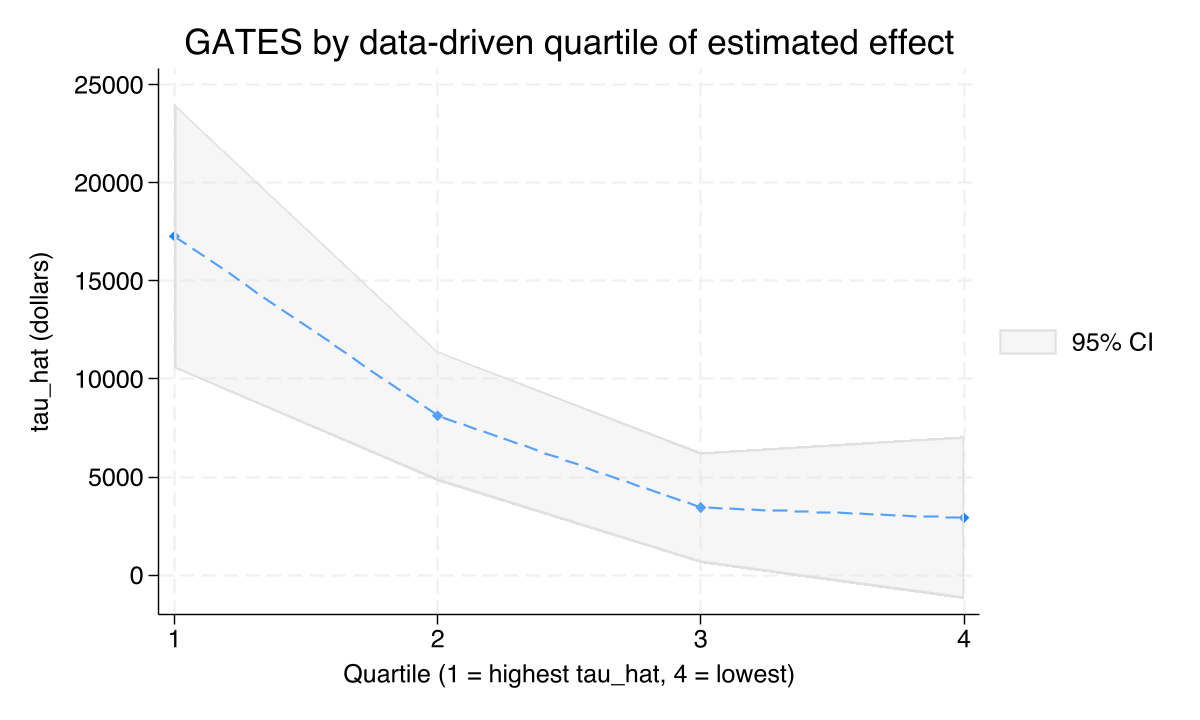
Let the data sort the households: the top quartile gains 5.9× the bottom
GATES by data-driven quartile of predicted effect: $17,279 → $8,121 → $3,444 → $2,919. A clean monotonic ladder; the bottom bin is not distinguishable from zero.
The high-effect quartile earns $35,878 more than the low-effect one
Covariate
Top quartile
Bottom quartile
Diff
\(t\)
Income ($)
62,739
26,861
35,878
56.2
Age (years)
45.2
35.0
10.2
35.7
Education (years)
14.0
12.7
1.4
18.6
estat classification: the data sorted itself; income is the dominant marker of who responds. All three gaps have \(t>18\).
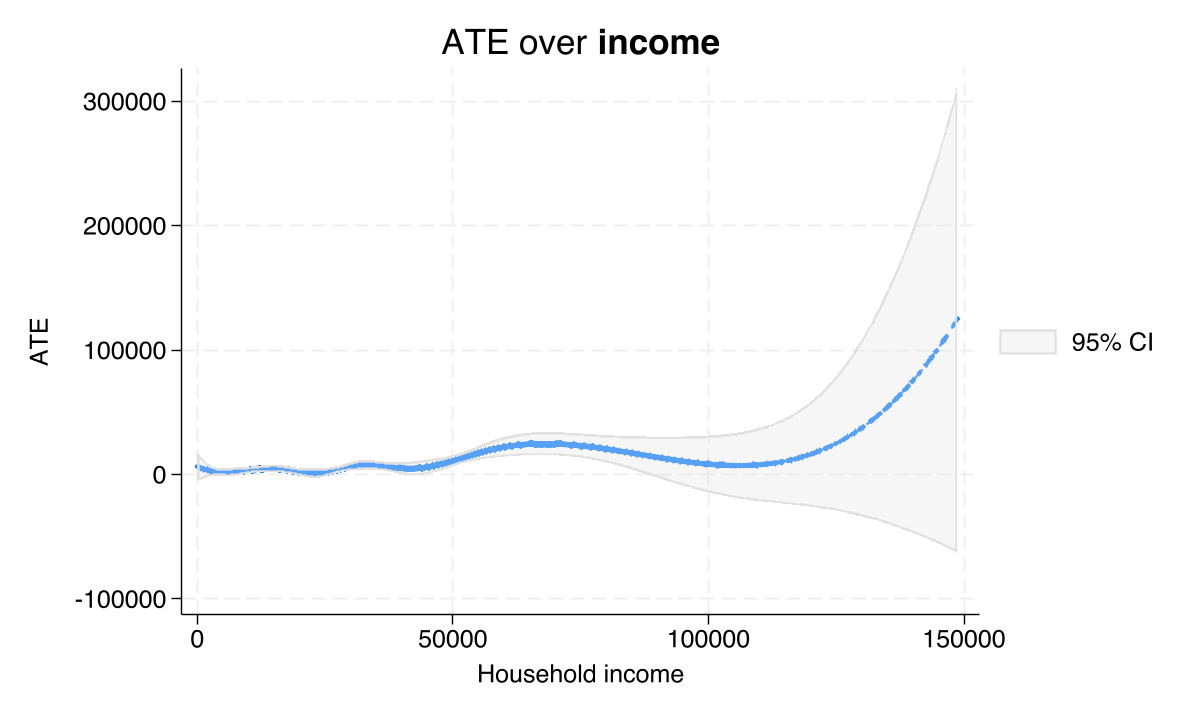
A smooth fit: each extra $1,000 of income adds ~$213 to the effect
Cubic B-spline of \(\hat\tau\) vs household income (income \(\le\) $150k): a smooth upward slope, steepest in the middle of the distribution.
The Resolution
Act III
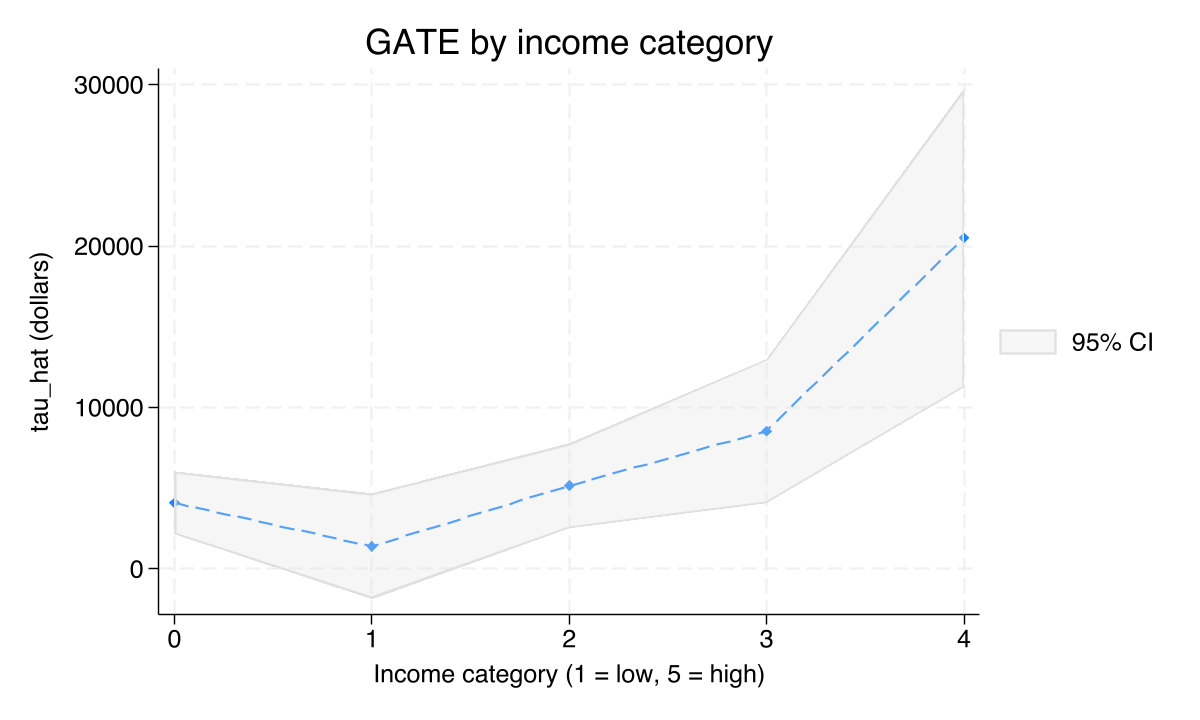
The top income group gains $20,511 — five times the average household
$20,511
GATE, highest income category (vs ~$4,000 at the bottom). Joint test of equality across groups: \(\chi^2(4)=18.44\), \(p=0.001\)
A quarter of households gain little or nothing — invisible in the ATE
The bottom GATES quartile is $2,919 with \(p=0.167\) — not statistically distinguishable from zero.
Combined with the small negative left tail of the histogram: roughly one in four households appears to gain close to nothing from eligibility.
Does the causal forest make this causal? No — the assumptions still carry it
Objection. A machine that flexibly selects controls surely earns us the causal interpretation.
Response. It does not. \(\tau(\mathbf{x})\) is identified only under unconfoundedness and overlap. The forest fits the function; it cannot rule out an unmeasured confounder.
The average is a press release; the CATE is the policy
ATE \(\approx \$8{,}000\) — agreed across three estimators within $183
But effects span $1,400 → $20,511 across income groups (\(p=0.001\))
Income is the moderator: +$213 per $1,000, +$18,195 at the top
One in four households gains essentially nothing
Estimate the CATE, not just the ATE — the average is hiding who your policy actually helps.