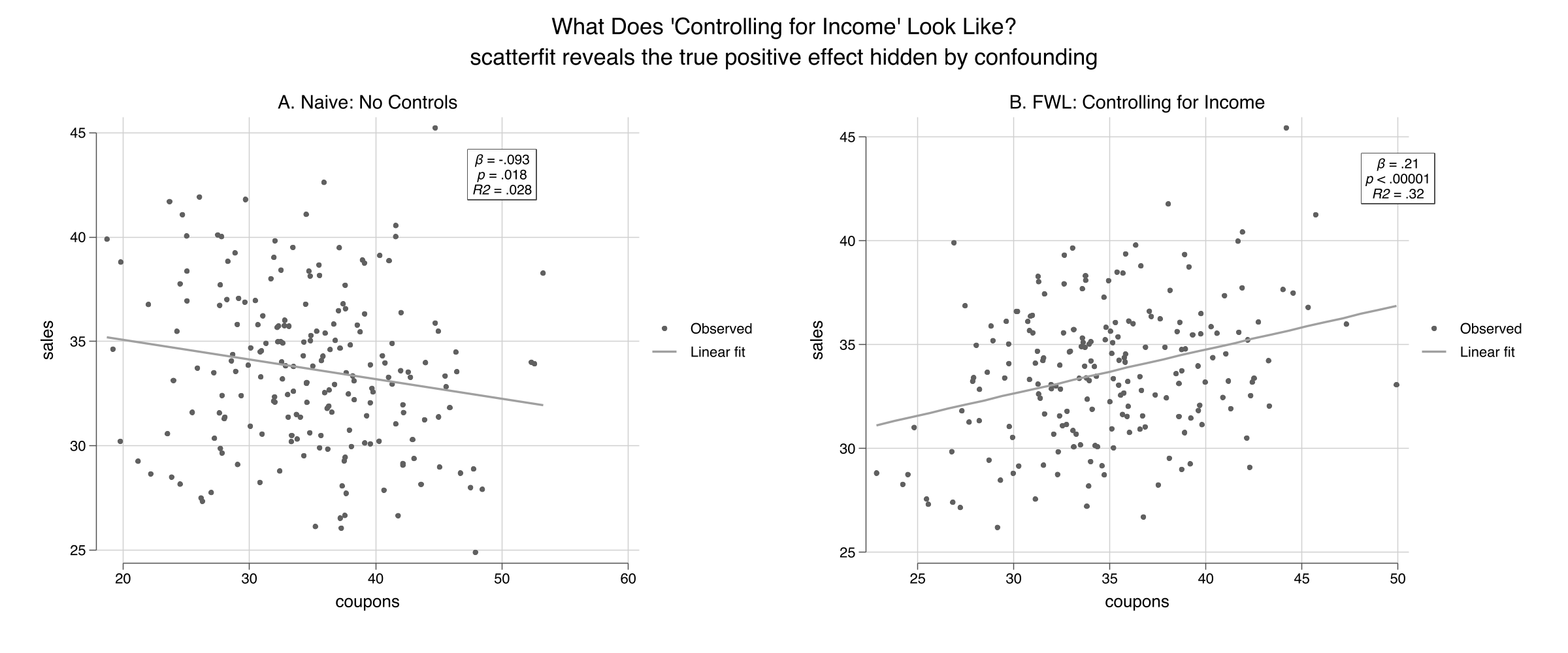
The manual slope 0.212288 equals the full-regression coefficient 0.212288 — not close, identical.
The residual regression reproduces the coefficient to six decimals
0.212288
Manual FWL slope = full-regression coupon coefficient. Same number, two paths.
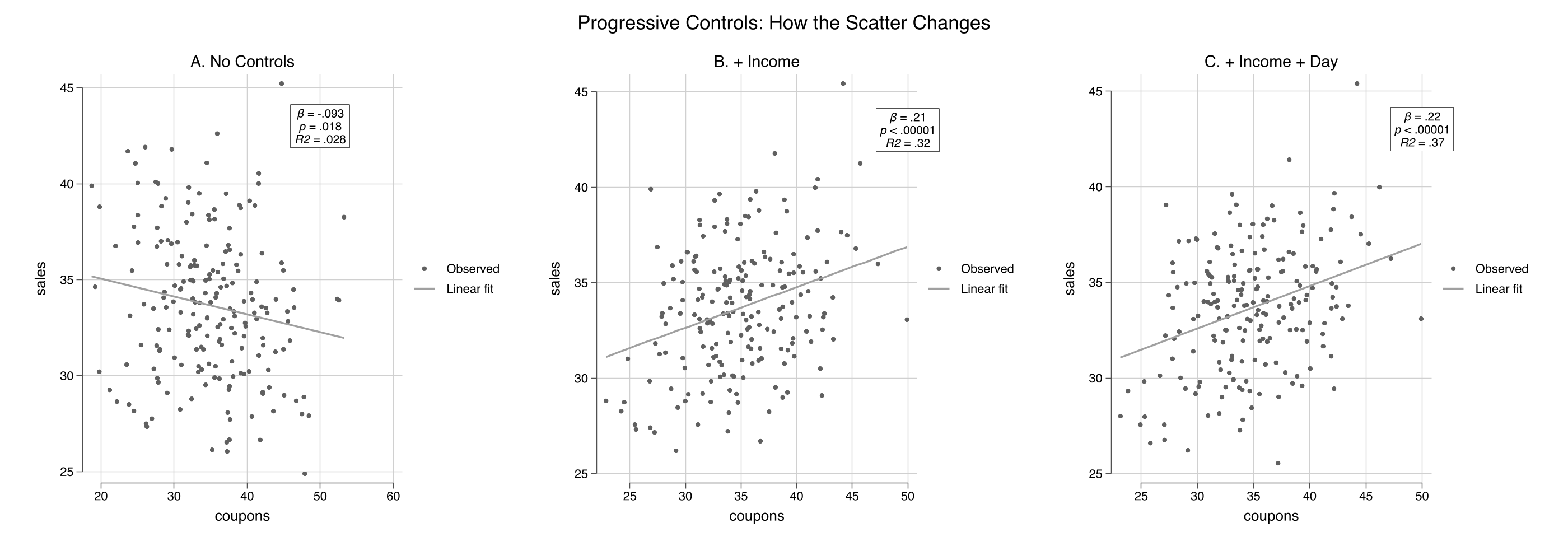
Add controls progressively and watch the scatter tighten
No controls (left, R² = 0.028) → + income (center, R² = 0.32) → + income + day-of-week (right, R² = 0.37). Each panel residualizes on more, so the cloud tightens.
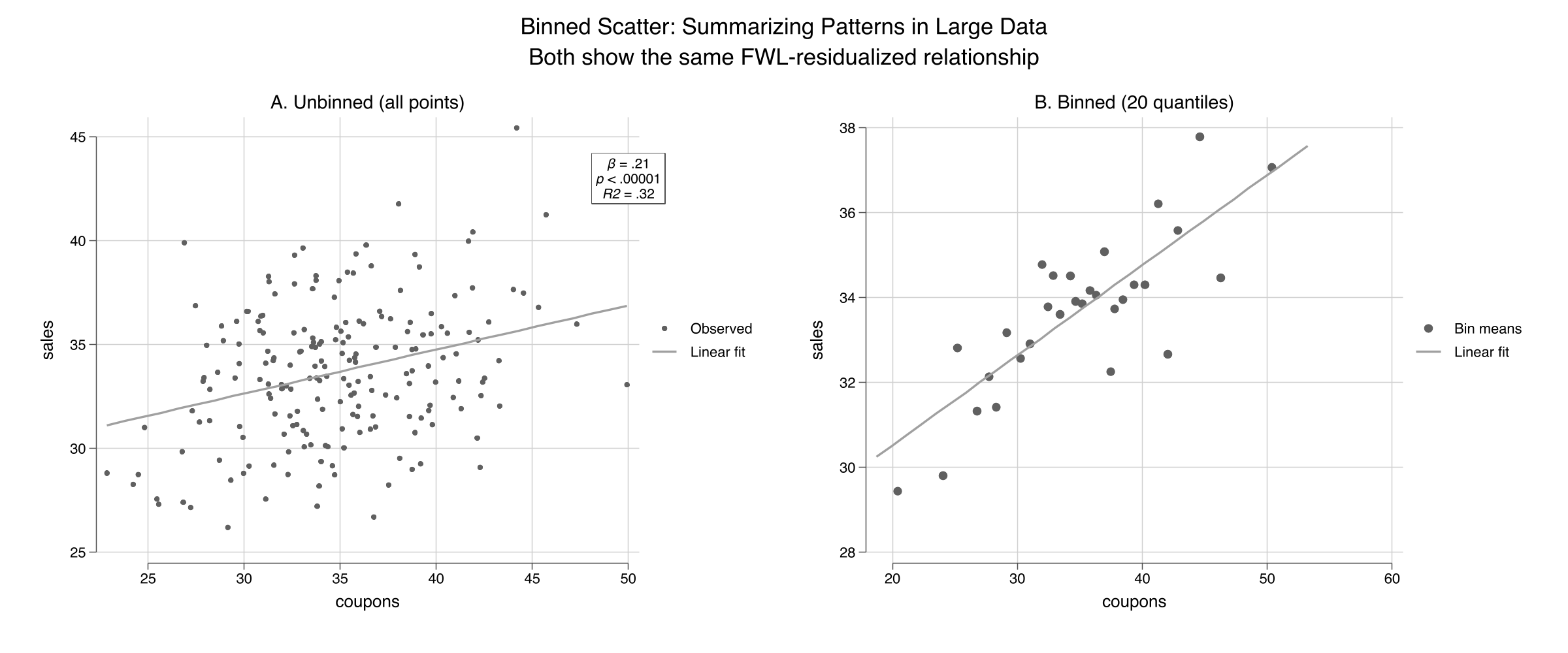
For thousands of points, bin the scatter — the slope is unchanged
Unbinned (left) vs. binned into 20 quantiles (right). Both show the same FWL-residualized fit (β = 0.21, R² = 0.32); binning replaces 200 points with 20 readable means.
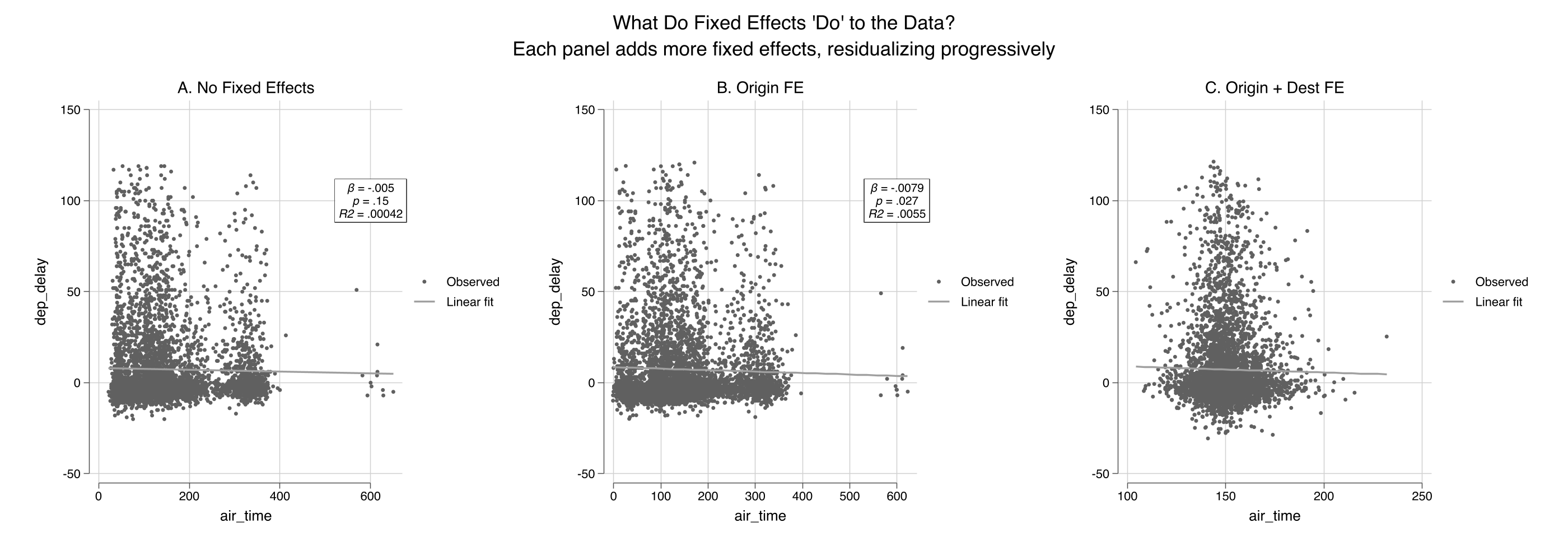
Fixed effects are just FWL on group dummies — and they reshape the cloud
Air-time vs. delay, NYC flights. No FE (left, R² ≈ 0) → origin FE (center) → origin + destination FE (right). fcontrols() demeans by group via reghdfe.
The Resolution
Act III
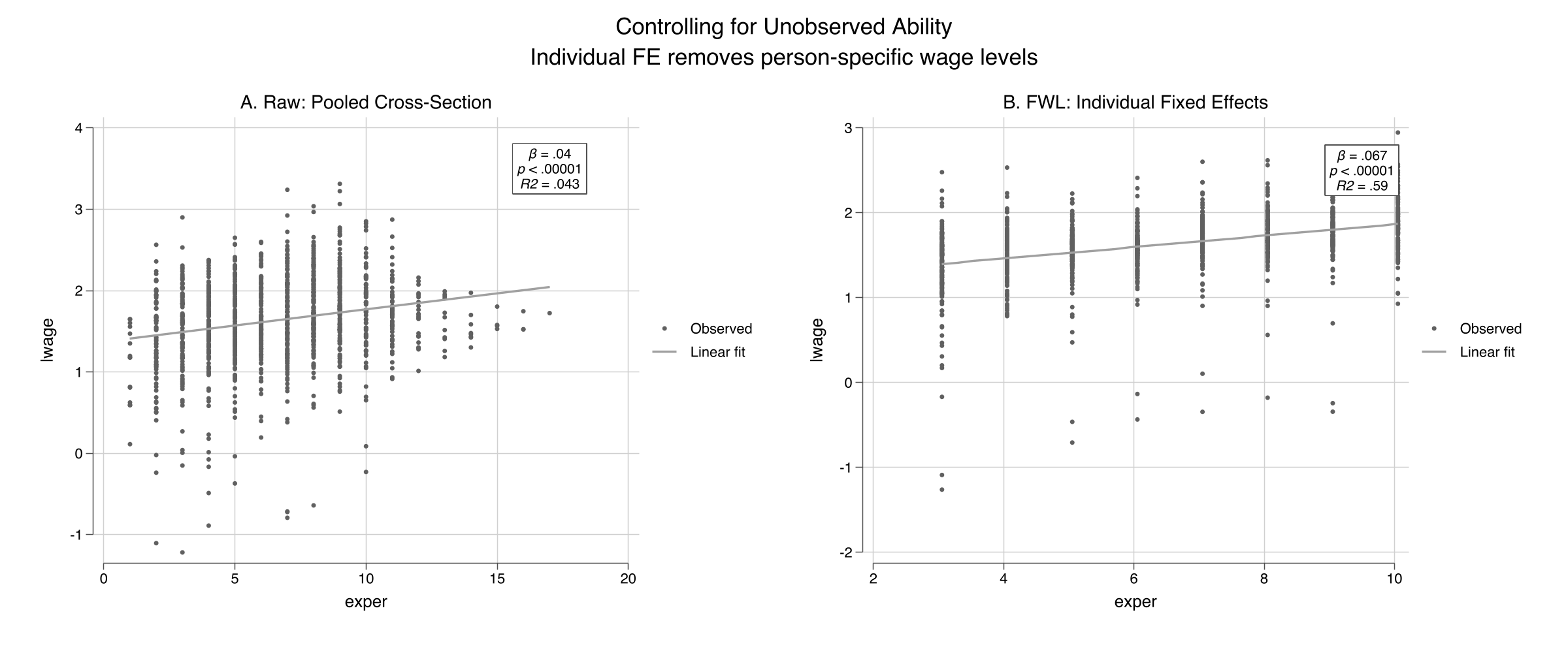
In a wage panel, individual fixed effects lift R² from 0.04 to 0.59
Raw pooled cross-section (left, R² = 0.043) vs. individual fixed-effects residualized scatter (right, R² = 0.59). fcontrols(nr) strips each person’s average — within-person experience returns ≈ 7%.
One algebra, three languages — only the syntax changes
Stata (scatterfit)
scatterfit y x — raw
, controls(z) — partial out Z
, fcontrols(fe) — group FE
, binned · regparameters()
R / Python
R: fwl_plot(y ~ x + z)
R: fwl_plot(y ~ x | fe)
Python: manual resid()
no binning / on-plot stats
The numbers match across all three because the datasets are identical — FWL is the same theorem everywhere.
Does the scatter make this causal? No — it only makes the algebra visible
Objection. A partial-regression plot looks like proof that coupons cause +0.212.
Response. It is not. FWL is an algebraic identity — it visualizes “holding Z fixed,” nothing more. The +0.212 is causal here only because we built the DGP.
“Controlling for X” is a residual-on-residual slope you can finally draw.