Evaluating a Cash Transfer RCT with Panel Data
When randomization is clean, every estimator should land on the truth — and here it does
Nagoya University (GSID)
July 8, 2026
The Tension
Act I
Governments spend billions on cash transfers — but does the money actually raise welfare?
The hard part isn’t sending the money — it is proving it worked.
So we simulate a known truth: the program raises consumption by 12% (\(0.12\) log points). Can the estimators recover it?
One dataset, twelve estimates — and the spread already tells a story
| Estimator family | Estimand | Estimate |
|---|---|---|
| Cross-sectional (RA / IPW / DR) | ATE (offer) | 0.113 |
| Difference-in-differences | ATT (offer) | 0.135–0.137 |
| Endogenous treatment (IV) | ATE (receipt) | 0.147 |
| True effect | — | 0.12 |
Twelve specifications, three estimands, one truth at \(0.12\) — and every 95% CI covers it.
Where we’re going
- Did randomization actually balance the groups?
- Three cross-sectional strategies — model the outcome, the treatment, or both
- Panel power: difference-in-differences and its doubly-robust cousin
- Offer vs. receipt — what imperfect compliance changes
The Investigation
Act II
The lab: 2,000 households, two waves, one known answer
- Outcome — log monthly consumption (\(y\)); true effect \(= 0.12\)
- Design — balanced panel, baseline 2021 + endline 2024, 4,000 rows
- Assignment —
treatrandomized within poverty strata (intent-to-treat) - Receipt —
D, endogenous: only 85% of offered households took up
State the wedge early: random treat is exogenous; actual D is a choice. Most of the deck estimates the offer effect; Act III’s coda returns to receipt.
Randomization worked: every covariate sits under the 10% balance threshold
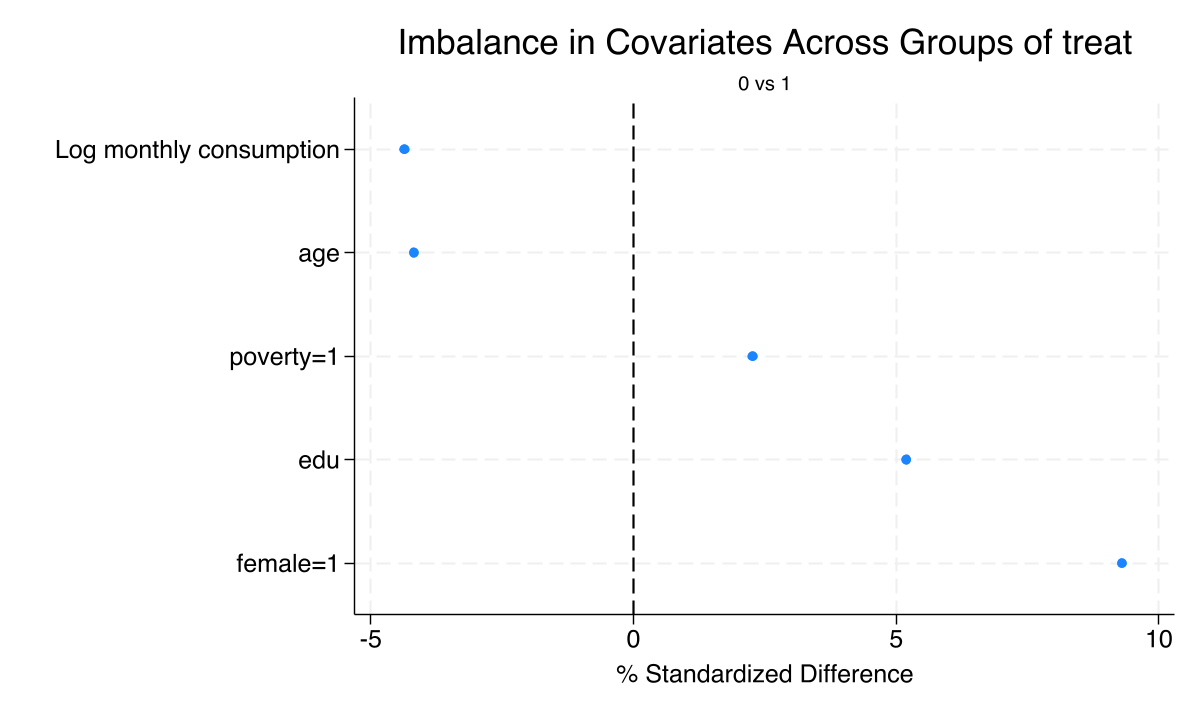
Standardized mean differences for all baseline covariates. Dashed lines mark the \(\pm 10\%\) rule of thumb; female is the only borderline case at \(\approx 9.3\%\).
The only chance imbalance is female-headship — and it is borderline, not broken
| Covariate | Control | Treatment | SMD |
|---|---|---|---|
| Consumption \(y\) | 10.025 | 10.006 | <0.05 |
| Age | 35.34 | 34.93 | <0.05 |
| Education | 11.97 | 12.08 | 0.052 |
| Female-headed | 0.484 | 0.531 | 0.093 |
| Poverty | 0.307 | 0.318 | <0.05 |
\(p = 0.038\) flags female, but the SMD of \(9.3\%\) is the right lens — large \(n\) makes tiny gaps “significant.”
A formal balance check: AIPW on baseline data should — and does — find nothing
\[\hat\tau_{\text{baseline}} = -0.024 \quad (p = 0.196)\]
Run the doubly-robust estimator on baseline only, before the program exists. A null “effect” is exactly what a clean randomization predicts.
Overidentification test: \(\chi^2(5) = 3.22\), \(p = 0.667\) — no residual imbalance after weighting.
After weighting, the two groups’ consumption distributions become indistinguishable
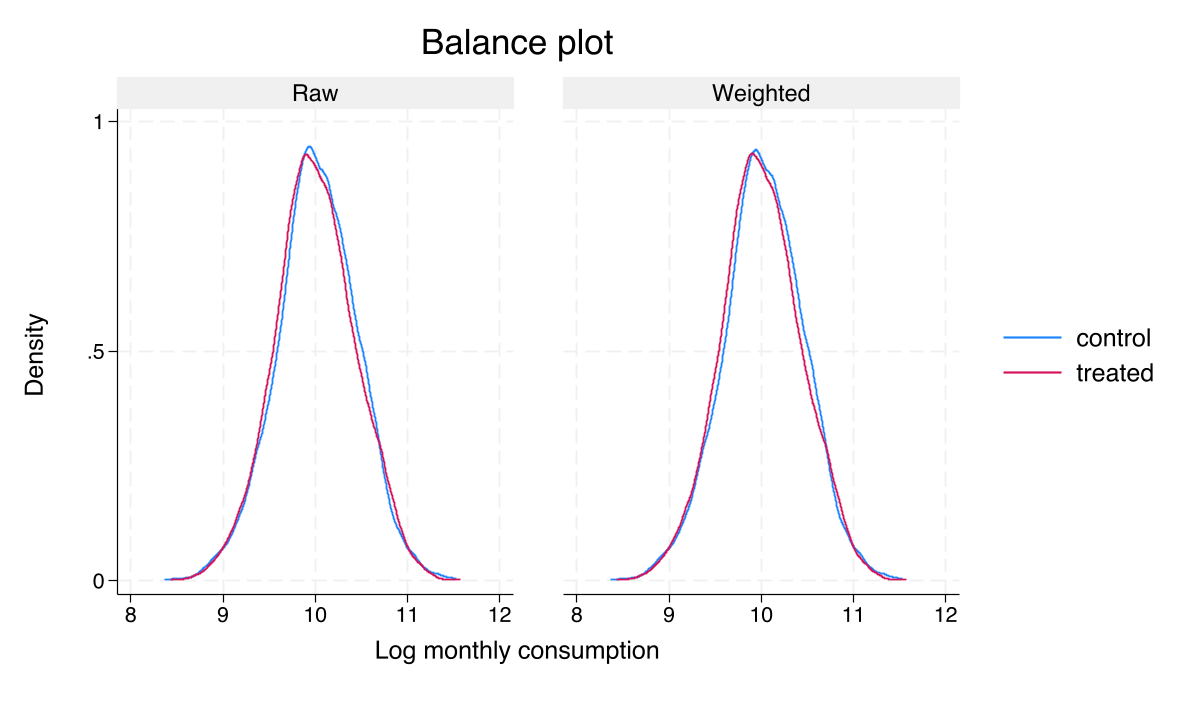
Log-consumption densities for treatment vs. control, before and after AIPW weighting. The weighted curves overlap almost perfectly.
Propensities cluster near 0.5 — exactly the comfortable regime for weighting
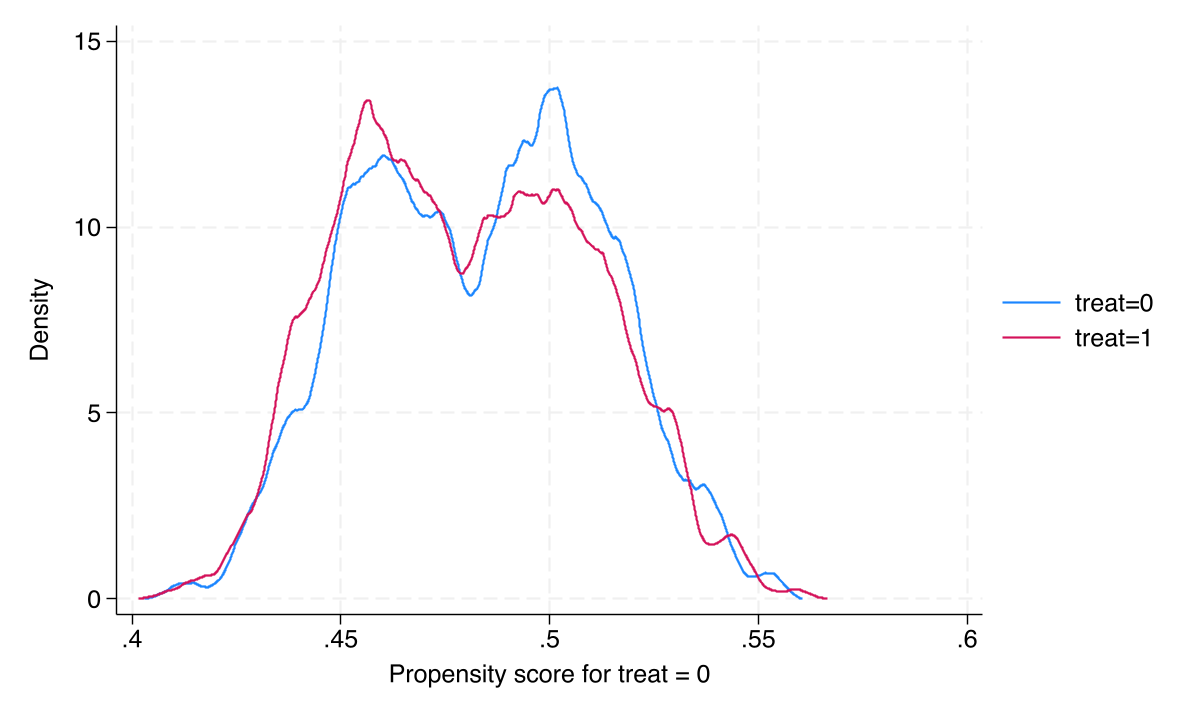
Estimated propensity-score densities for both groups span roughly 0.43–0.55 with heavy overlap and no mass near 0 or 1.
What are we even estimating? ATE and ATT are different questions
ATE
\[E[Y(1) - Y(0)]\]
- The policymaker’s question
- “What if we scale to everyone?”
ATT
\[E[Y(1) - Y(0) \mid T = 1]\]
- The evaluator’s question
- “Did it help the participants?”
Under randomization with homogeneous effects, ATE \(=\) ATT. DiD will only ever give us the ATT.
In an RCT, controls don’t remove bias — they buy precision
Randomized treatment is independent of potential outcomes, so the raw difference in means is already unbiased.
No confounding here, so covariates don’t fix bias — they soak up residual variation and tighten the estimate.
Three strategies, three things to model: outcome, treatment, or both
RA — model the outcome
- Fits \(\hat\mu_1(X)\), \(\hat\mu_0(X)\)
- ATE \(= \frac1N\sum[\hat\mu_1 - \hat\mu_0]\)
- Fails if outcome model wrong
IPW — model the treatment
- Fits propensity \(\hat p(X)\)
- Reweights by \(1/\hat p\), \(1/(1-\hat p)\)
- Fails on extreme weights
Doubly robust (AIPW / IPWRA) fits both — and is consistent if either one is correct.
Doubly robust estimation: one model can be wrong and the answer still holds
\[\hat\tau_{DR}^{ATE} = \frac1N \sum_{i=1}^{N}\Big[\hat\mu_1(X_i) - \hat\mu_0(X_i) + \frac{T_i\,(Y_i - \hat\mu_1)}{\hat p(X_i)} - \frac{(1-T_i)(Y_i - \hat\mu_0)}{1 - \hat p(X_i)}\Big]\]
First two terms: the RA prediction. Last two: IPW residuals that cancel RA’s bias.
Belt and suspenders: if the belt fails, the suspenders hold. Only both wrong is fatal.
The cross-sectional toolkit is six lines of teffects
keep if post==1
* RA — models the outcome only
teffects ra (y c.age c.edu i.female i.poverty) (treat), ate
* IPW — models the treatment only
teffects ipw (y) (treat c.age c.edu i.female i.poverty), ate
* Doubly robust — models both
teffects ipwra (y c.age c.edu i.female i.poverty) (treat c.age c.edu i.female i.poverty), vce(robust)The headline cross-sectional result: every method converges on 0.113
0.113
ATE of the offer · RA, IPW, and doubly-robust IPWRA agree to three decimals (SE 0.019)
RA, IPW, and DR agree because randomization made every model approximately right
| Method | Models | Estimand | Estimate | 95% CI |
|---|---|---|---|---|
| Simple diff-in-means | none | ATE | 0.116 | [0.078, 0.154] |
| Regression adjustment | outcome | ATE | 0.113 | [0.075, 0.150] |
| Inverse prob. weighting | treatment | ATE | 0.113 | [0.075, 0.150] |
| IPWRA (doubly robust) | both | ATE | 0.113 | [0.075, 0.150] |
| True effect | — | — | 0.12 | — |
Adjusted estimates (\(0.113\)) sit just below the raw \(0.116\) — that gap is the precision gain from controlling for the gender imbalance.
Panel data lets each household be its own control — differencing out the invisible
Cross-sectional adjustment can only control for what you observe.
Difference-in-differences compares each household to itself over time, cancelling every time-invariant unobservable — motivation, geography, family culture.
DiD is a difference of differences — the control trend is the counterfactual
\[\hat\tau_{DiD} = \underbrace{(\bar Y_{T,post} - \bar Y_{T,pre})}_{\text{effect}\,+\,\text{trend}} - \underbrace{(\bar Y_{C,post} - \bar Y_{C,pre})}_{\text{trend only}}\]
Treated change = effect + trend. Control change = trend alone. Subtract — the trend cancels.
Identification rides on parallel trends — plausible here because randomization equalized the groups at baseline.
Panel DiD recovers 0.135 — and it is structurally an ATT, not an ATE
0.135 sits just above the cross-sectional \(0.113\) — the wider SE (\(0.027\) vs \(0.019\)) is the price of differencing.
Doubly robust DiD: Sant’Anna–Zhao bring the “either model” guarantee to panels
\[\hat\tau_{DR}^{DiD} = \frac{1}{N_1}\sum_{i=1}^{N}\big[w_1(D_i) - w_0(D_i, X_i)\big]\big[\Delta Y_i - \hat\mu_{0,\Delta}(X_i)\big]\]
Subtract the control-group’s predicted change from each household’s actual change \(\Delta Y_i\), then IPW-reweight so controls resemble the treated. Consistent if either model is right.
Needs only conditional parallel trends — covariate-specific time trends are allowed.
The Resolution
Act III
Two independent DR-DiD implementations agree exactly on 0.137
0.137
ATT of the offer · drdid and xthdidregress aipw match to four decimals (SE 0.027)
Cross-section vs. panel: different estimands, different data, same truth inside the bars
| Method | Estimand | Data | Estimate | 95% CI |
|---|---|---|---|---|
| RA / IPW / DR | ATE | endline | 0.113 | [0.075, 0.150] |
| Basic DiD | ATT | both waves | 0.135 | [0.081, 0.188] |
DR-DiD (drdid) |
ATT | both waves | 0.137 | [0.084, 0.191] |
DR-DiD (xthdidregress) |
ATT | both waves | 0.137 | [0.084, 0.191] |
| True effect | — | — | 0.12 | — |
DiD’s value is not a tighter SE — it is robustness to time-invariant unobservables.
Offer vs. receipt: only 85% complied, so the per-recipient effect is larger
Most of the deck estimated the offer (treat, intent-to-treat). The effect of receipt (D) needs the random offer as an instrument, because take-up is a choice.
| Specification | Estimand | Estimate | 95% CI |
|---|---|---|---|
etregress (IV) |
ATE (receipt) | 0.147 | [0.099, 0.195] |
teffects ipwra + \(y_0\) |
ATE (receipt) | 0.117 | [0.054, 0.180] |
The doubly-robust receipt estimate (\(0.117\)) lands closest to the truth; both cover \(0.12\).
Receipt-model overlap holds too — the IV story rests on solid balance
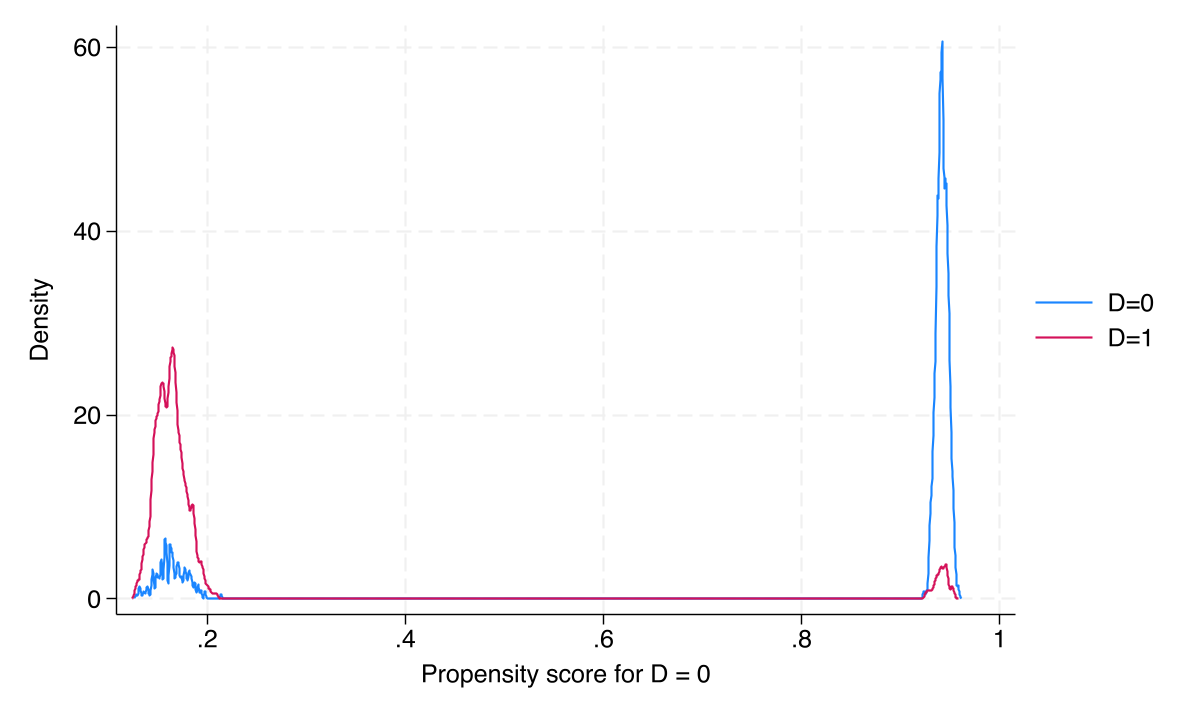
Propensity-score densities for receivers vs. non-receivers of the transfer show ample common support after IPWRA weighting.
Does any of this make the result causal? No — design does, methods only discipline
Objection. Twelve estimators all near 0.12 — surely that proves the cash transfer caused the gain?
Response. The randomization identifies the effect; the estimators merely recover it efficiently and robustly. On real observational data the same methods rest on conditional independence and parallel trends — assumptions a clean RCT hands you for free but the world rarely does.