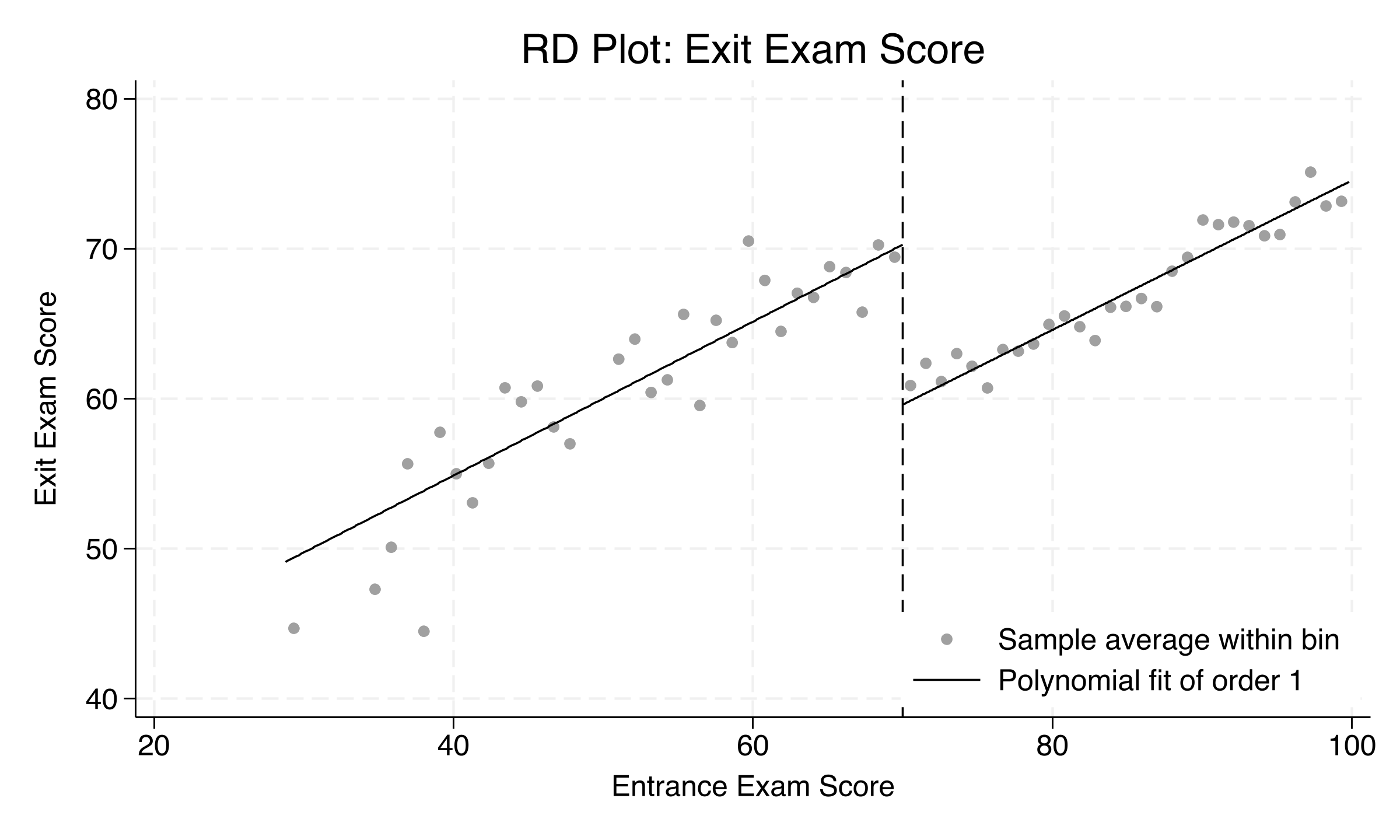
Smaller bandwidth → less bias (more comparable units) but more variance (fewer observations). rdrobust picks the MSE-optimal \(h\) automatically.
With an MSE-optimal bandwidth of 9.98, the LATE is −8.58
−8.58
rdrobust RD effect (robust 95% CI −12.14 to −4.54, \(p<0.001\)); only the 400 students within ±10 of the cutoff are used
Same finding, two conventions — both say tutoring helps by ~9–11
Parametric OLS
Sign: \(+10.80\)
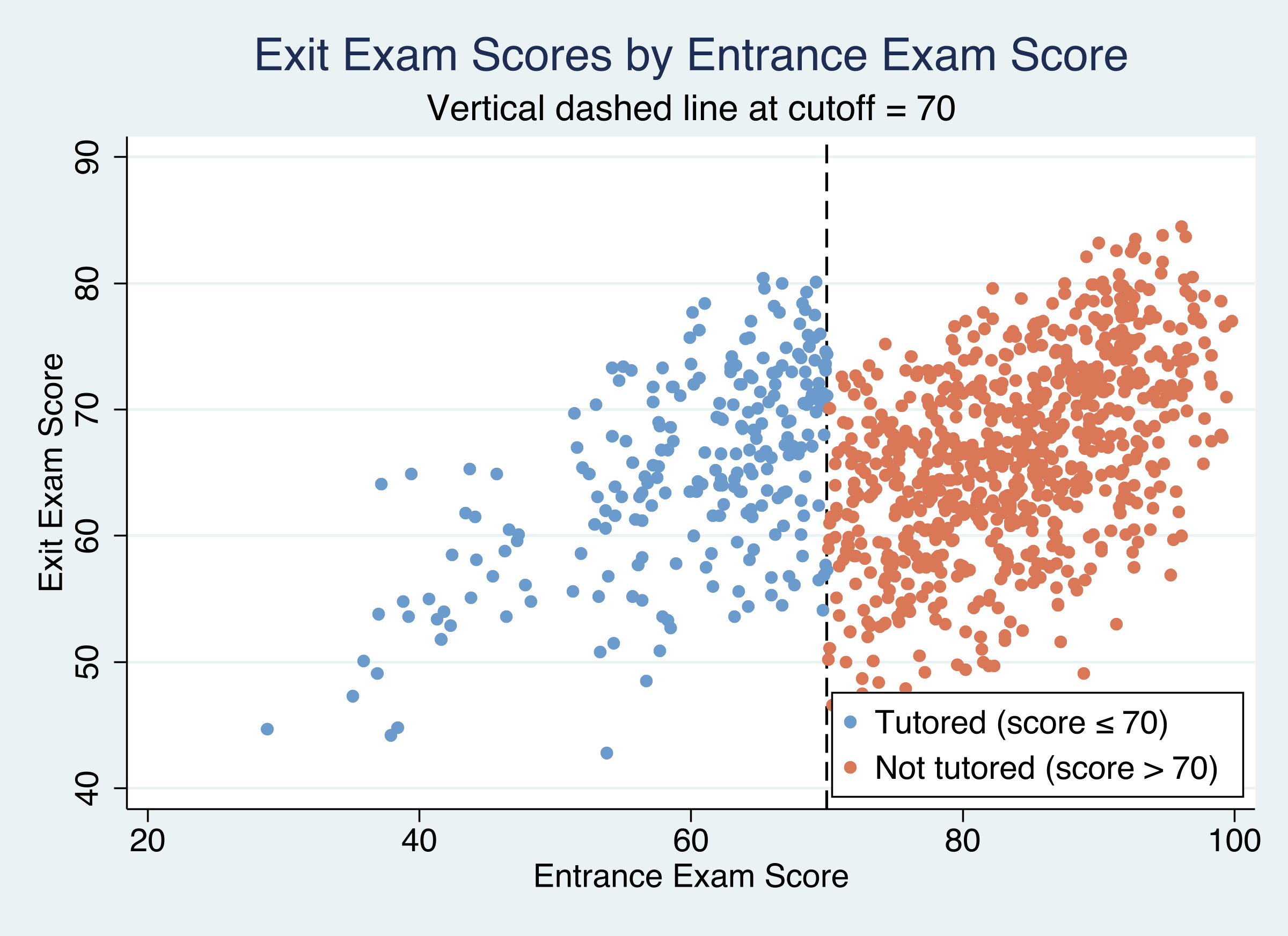
Sample: all 1,000 students
Imposes a global linear trend
“Effect of being tutored”
Nonparametric rdrobust
Sign: \(-8.58\)
Sample: ~400 near the cutoff
No functional-form assumption
“Jump left→right across 70”
Opposite signs, identical message: tutoring raises exit scores by roughly 9–11 points at the cutoff.
The Resolution
Act III
The estimate barely moves from BW 5 to 20: −8.20 to −9.16
Bandwidth
\(\hat\tau\)
SE
\(p\)
5
−8.202
2.337
<0.001
10
−8.581
1.615
<0.001
15
−8.842
1.312
<0.001
20
−9.157
1.131
<0.001
Less than one point across a 4× change in window — not a bandwidth artifact.
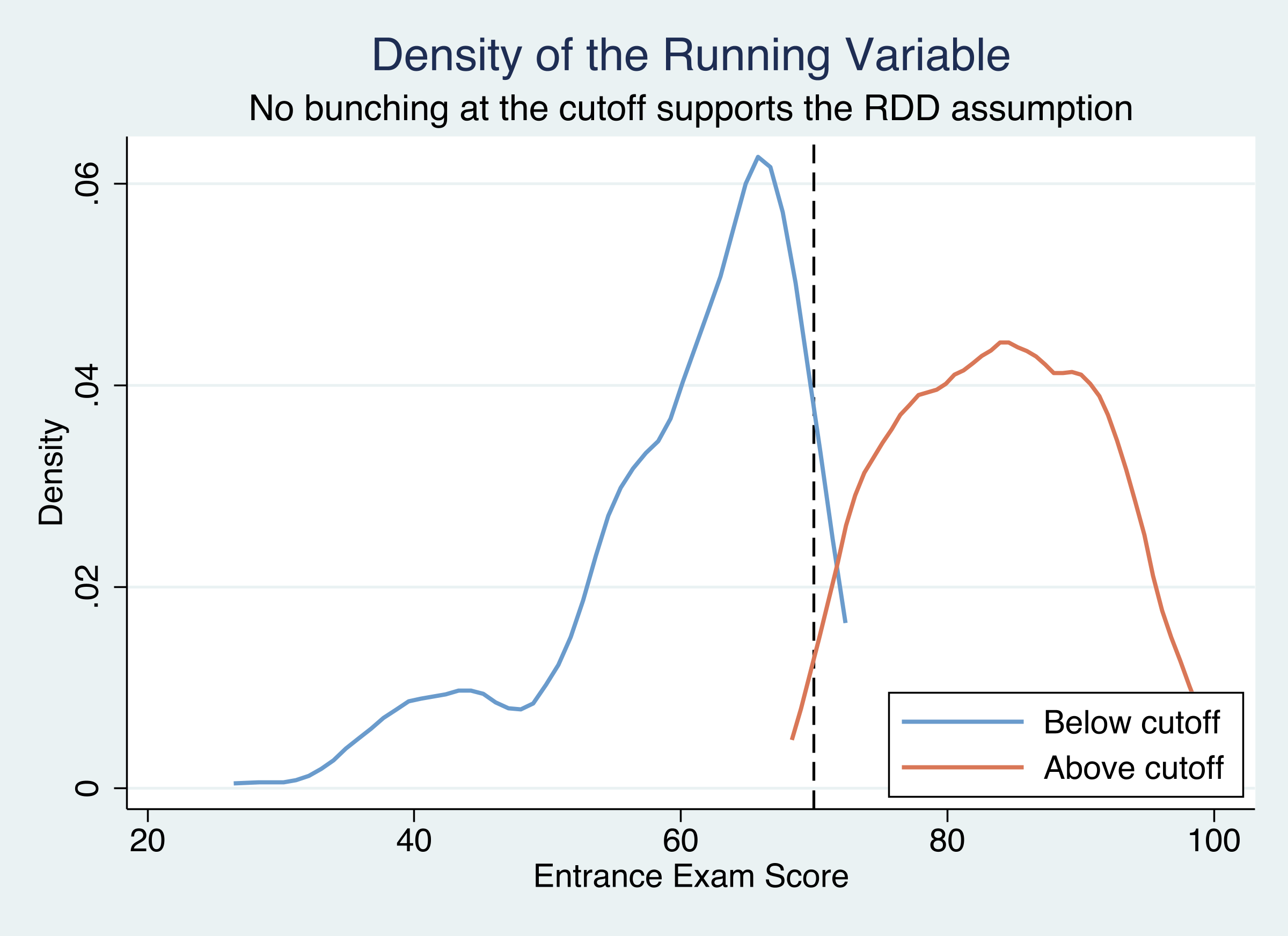
The McCrary test finds no manipulation: density p = 0.58
Kernel densities of the running variable, each side of the cutoff. Similar heights at 70 → no bunching.
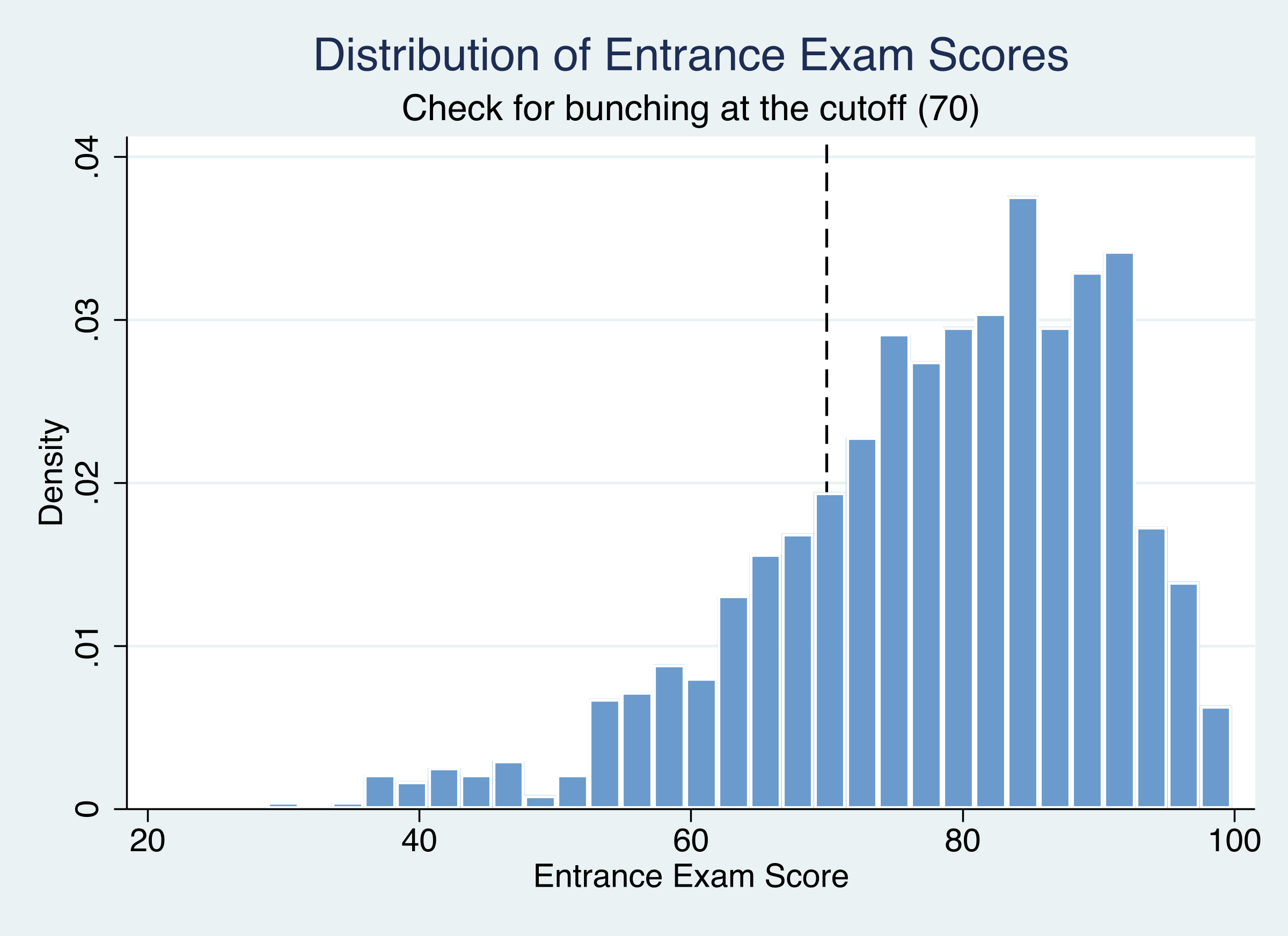
The histogram confirms it: no spike or heaping at the cutoff
Distribution of entrance exam scores; vertical line at 70. The mass transitions smoothly through the threshold.
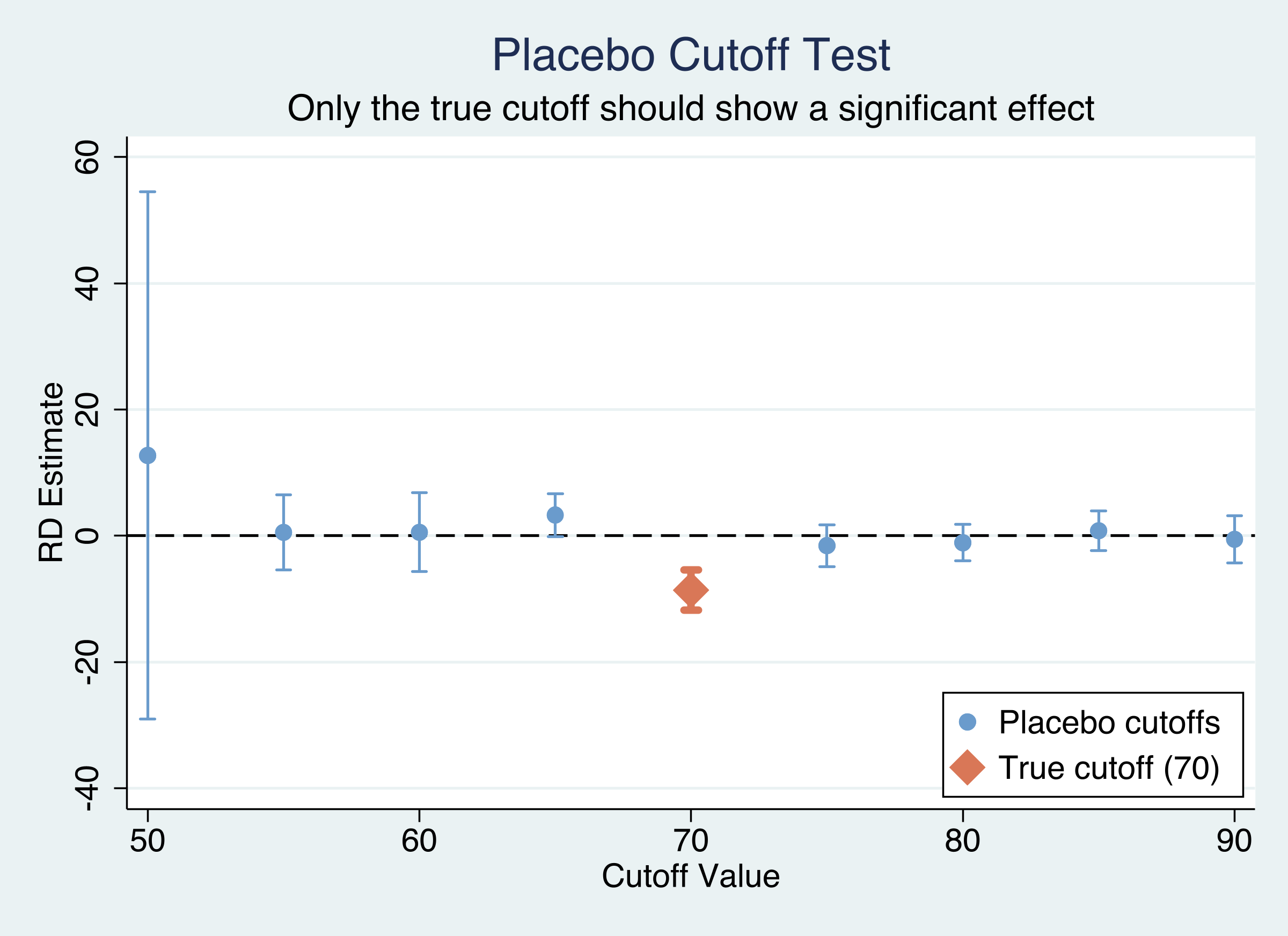
The discontinuity is unique to 70 — every placebo cutoff is null
rdrobust at 9 cutoffs with 95% CIs. Only the true cutoff at 70 (orange) excludes zero; placebos straddle zero.
Does machine-picking the bandwidth make this causal? No.
Objection. A data-driven bandwidth and a clever package can’t manufacture identification.
Response. Correct — and we never claim they do. Identification rests on continuity at 70; rdrobust just estimates the jump. The density and placebo tests defend that assumption — they don’t replace it.
Both methods agree: rule-based tutoring lifts exit scores 9–11 points
Approach
Estimate
95% CI
\(p\)
Parametric OLS (linear)
+10.80
9.22 – 12.38
<0.001
Parametric OLS (quadratic)
+9.22
6.87 – 11.57
<0.001
Nonparametric rdrobust
8.58
4.54 – 12.14
<0.001
9–11 points is ~13–16% of the mean exit score (66.2) — passing vs failing for a borderline student.
Let the cutoff, not your model, do the identifying.