Did Proposition 99 cut smoking? We can never observe the California that voted no
In November 1988, California raised its cigarette tax by 25 cents a pack and funded an anti-smoking campaign.
To measure the effect we need California’s smoking without the law — a counterfactual we never get to see. Every method here is a different way to imagine it.
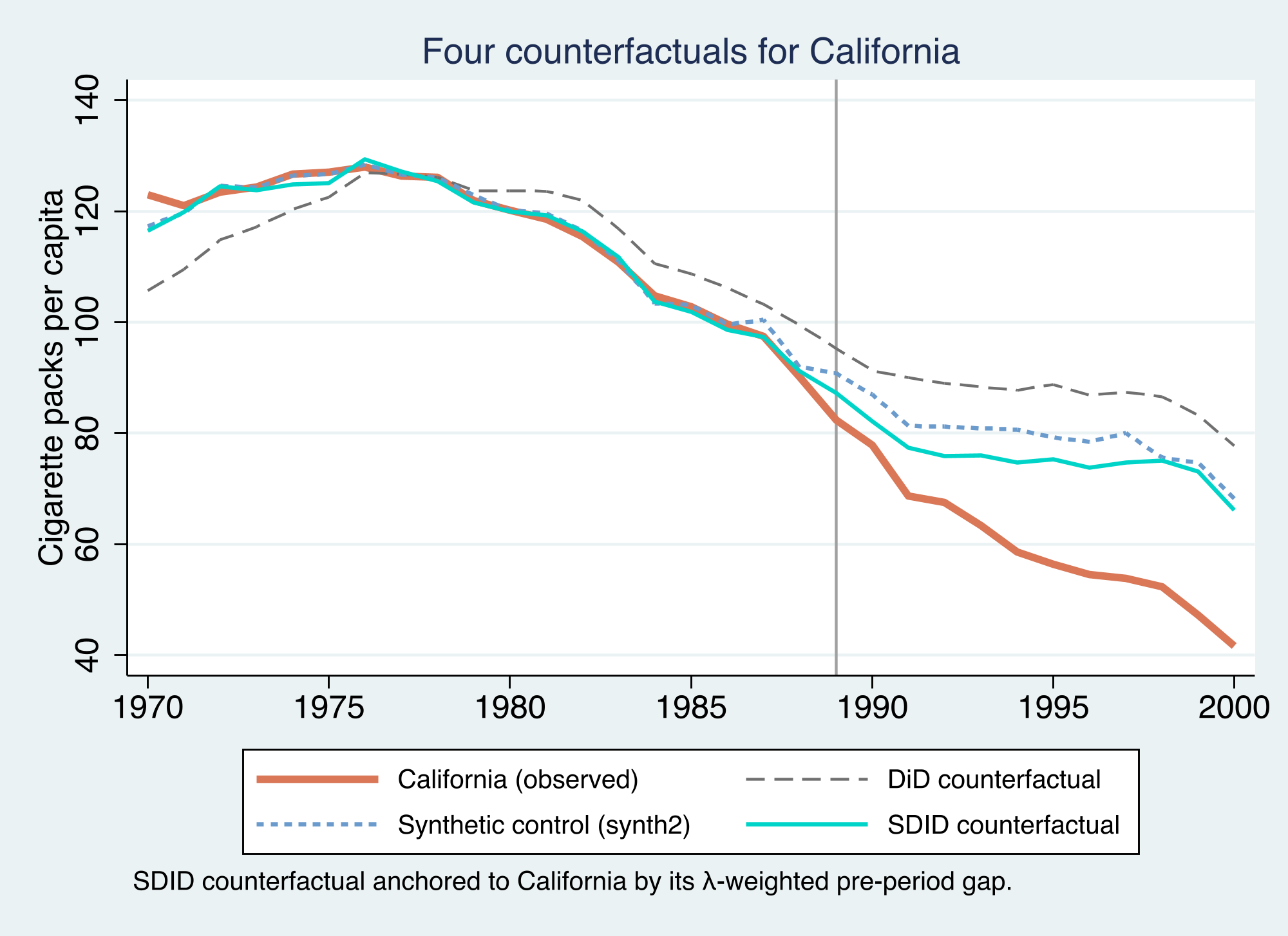
Three estimators, one dataset, three different answers — from −27 to −16
ATT in packs per capita. The naive 2×2 DiD counterfactual sits highest (−27), synthetic control next (−19.5), and SDID closest to California (−15.6). All four lines track California before 1989, then separate.
Where we’re going
The case: Proposition 99 and a 39-state, 31-year panel
Three estimators written as one weighted regression
SDID’s signature: unit weights and time weights
Inference with a single treated unit — placebo, not bootstrap
The Investigation
Act II
The lab: 39 states, 1970–2000, one outcome, one treated unit
Outcome\(Y_{it}\) — annual cigarette sales, packs per capita
Treated\(W_{it}\) — California from 1989 only (\(N_{tr}=1\))
Donor pool — 38 control states, no comparable tobacco program
No covariates — SC and SDID see exactly the same information
1,209 observations, of which only 12 are treated. That extreme imbalance is the defining feature of a comparative case study — and it dictates how we do inference.
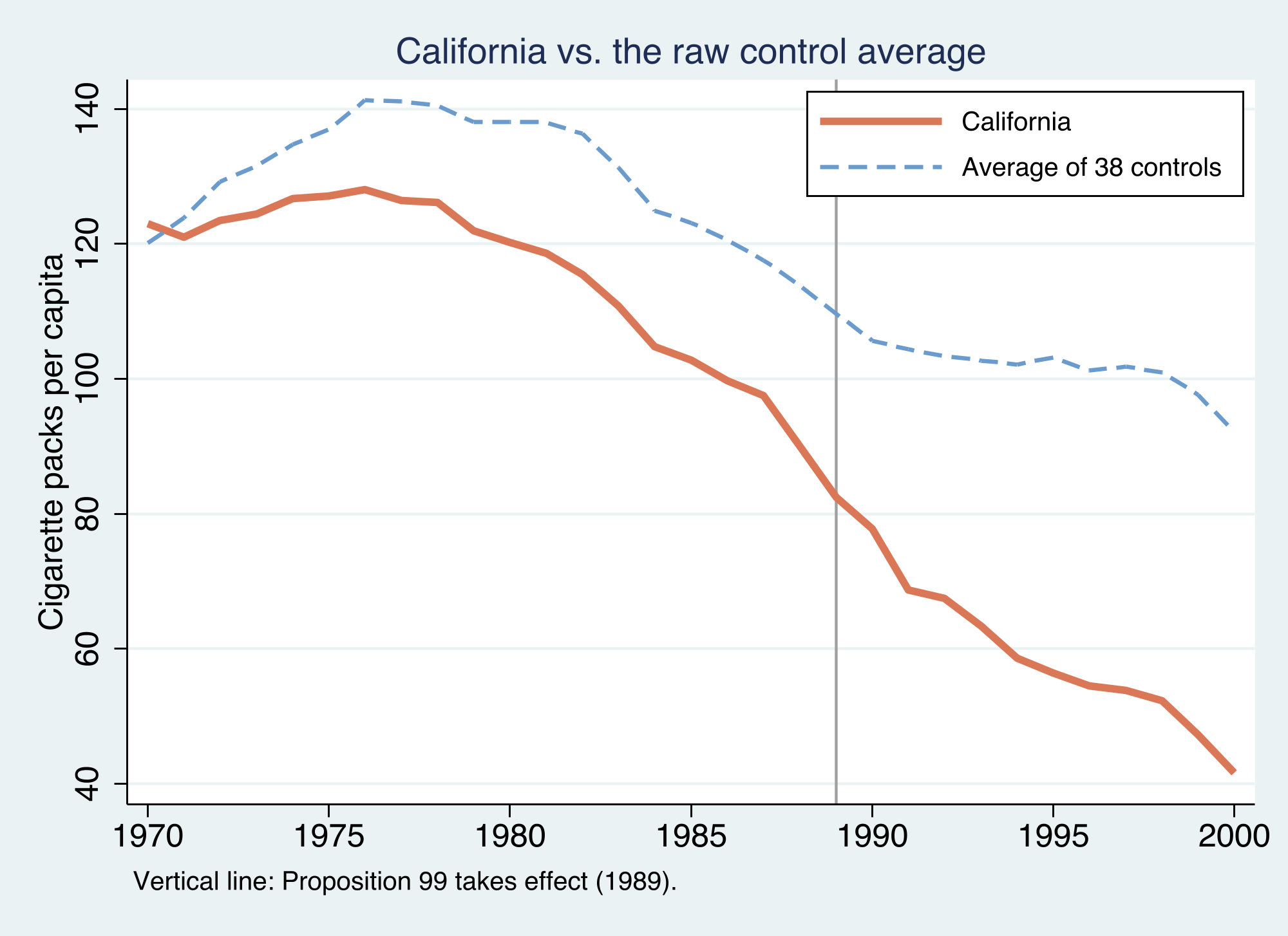
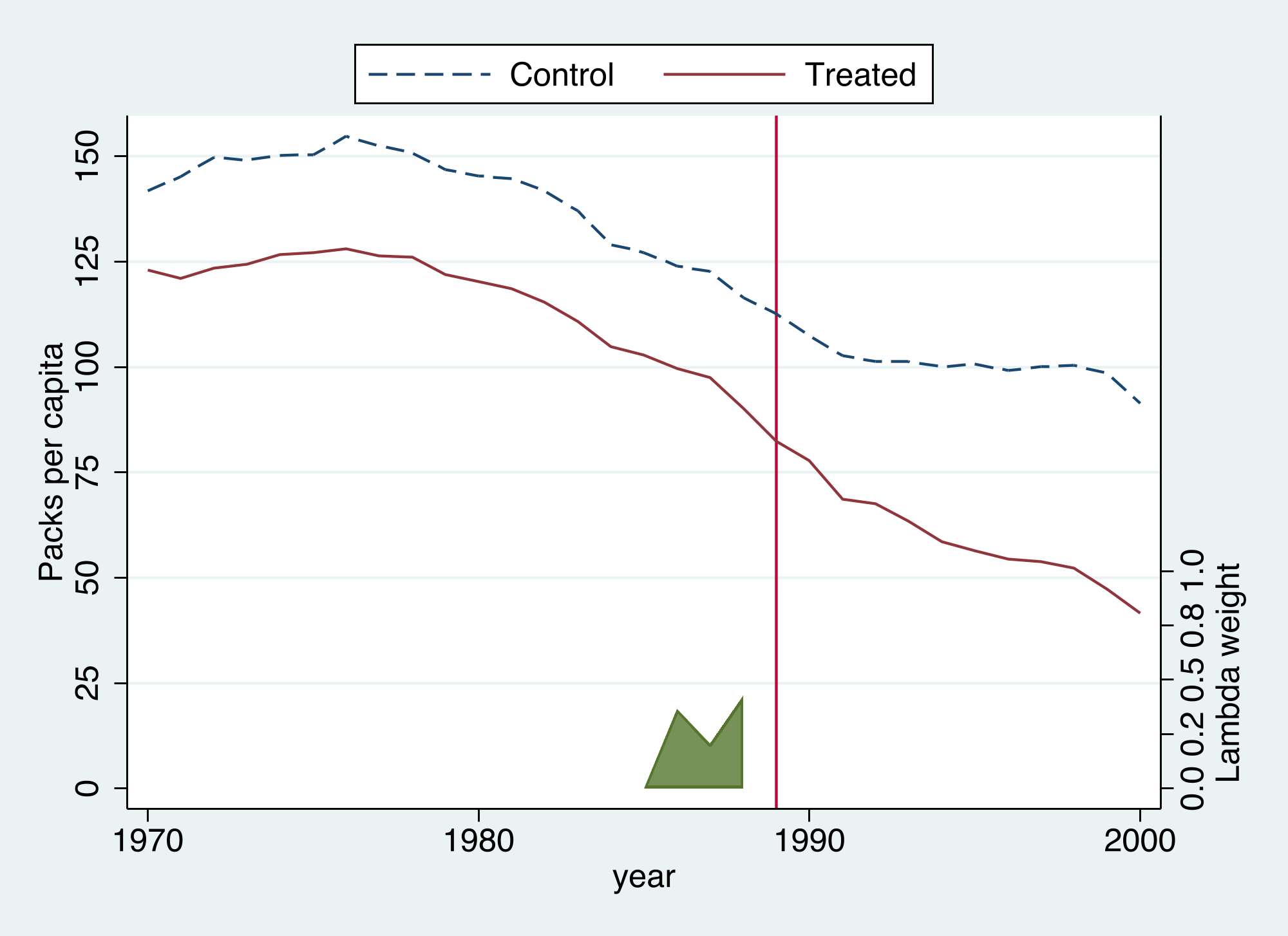
The naive picture already warns us: California was on a different level and trend
California (orange) already smoked less than the 38-state average and was declining through the 1980s; after 1989 the gap widens — but the two series differed in level and slope before the policy, so a raw comparison is not enough.
The estimand is the ATT — the effect of the policy on California
Average, over treated units and post-1988 years, of the outcome with the policy minus the outcome that would have occurred without it. With \(N_{tr}=1\), every method is just a different way to impute the missing \(Y_{it}(0)\).
SDID is one weighted two-way fixed-effects regression
\(\alpha_i\) is a state fixed effect, \(\beta_t\) a year fixed effect, \(\tau\) the ATT. The two extra terms — \(\hat{\omega}_i\) (unit weight) and \(\hat{\lambda}_t\) (time weight) — are everything that separates SDID from ordinary regression.
Set both weights uniform and you get plain DiD; drop the time weights and unit FE and you get SC
DiD — special case
\(\hat{\omega}_i,\ \hat{\lambda}_t\) both uniform
unit FE \(\alpha_i\)kept
credibility rests on parallel trends vs. all controls
SC — special case
\(\hat{\omega}_i\)optimized, no \(\hat{\lambda}_t\)
unit FE \(\alpha_i\)dropped
must match California’s leveland trend
SDID keeps the best of both: optimized \(\hat{\omega}_i\)and\(\hat{\lambda}_t\), with the unit FE retained — match the trend, allow a level gap.
Unit weights make the synthetic track California’s pre-period path
The intercept \(\omega_0\) lets SDID match California’s trend without matching its level. The ridge penalty \(\zeta^{2} T_{pre} \lVert \omega \rVert_2^{2}\) spreads weight across donors instead of betting on one or two.
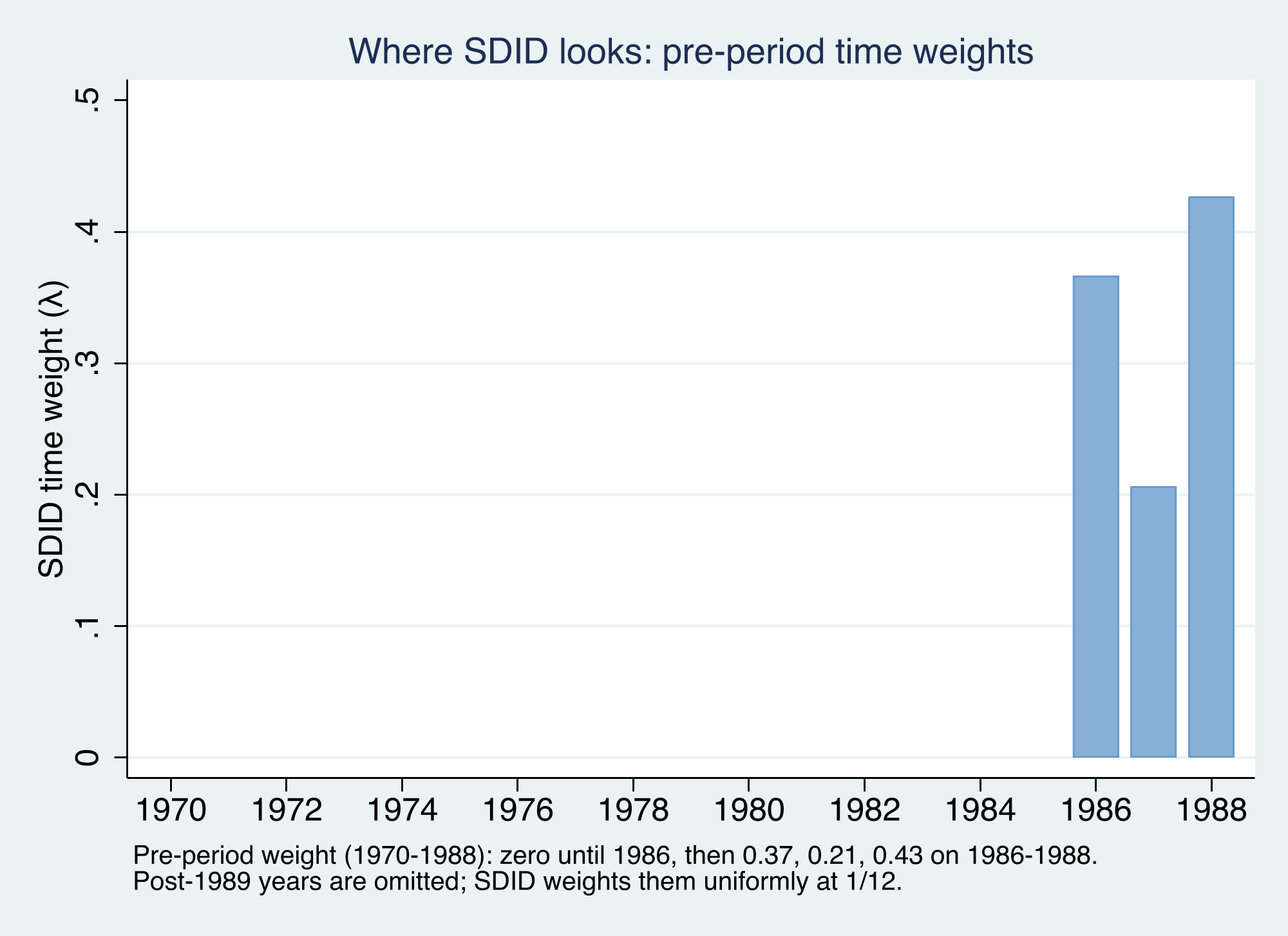
Time weights are SDID’s signature: which pre-years predict the post-period?
Find pre-period year weights so the weighted pre-period outcome matches each control’s post-period average. Years that look most like the post-period get the most weight — we will see all of it land on 1986–1988.
Against the simple 38-state average, the 2×2 DiD says −27.35 packs
Term
Coefficient
SE
Sig. 5%?
cal#post (DiD)
−27.35
10.91
yes
1.post
−28.51
1.75
yes
1.cal
−14.36
6.79
yes
The 2×2 DiD: California’s before/after drop (−55.86) minus the controls’ drop (−28.51) = −27.35 packs.
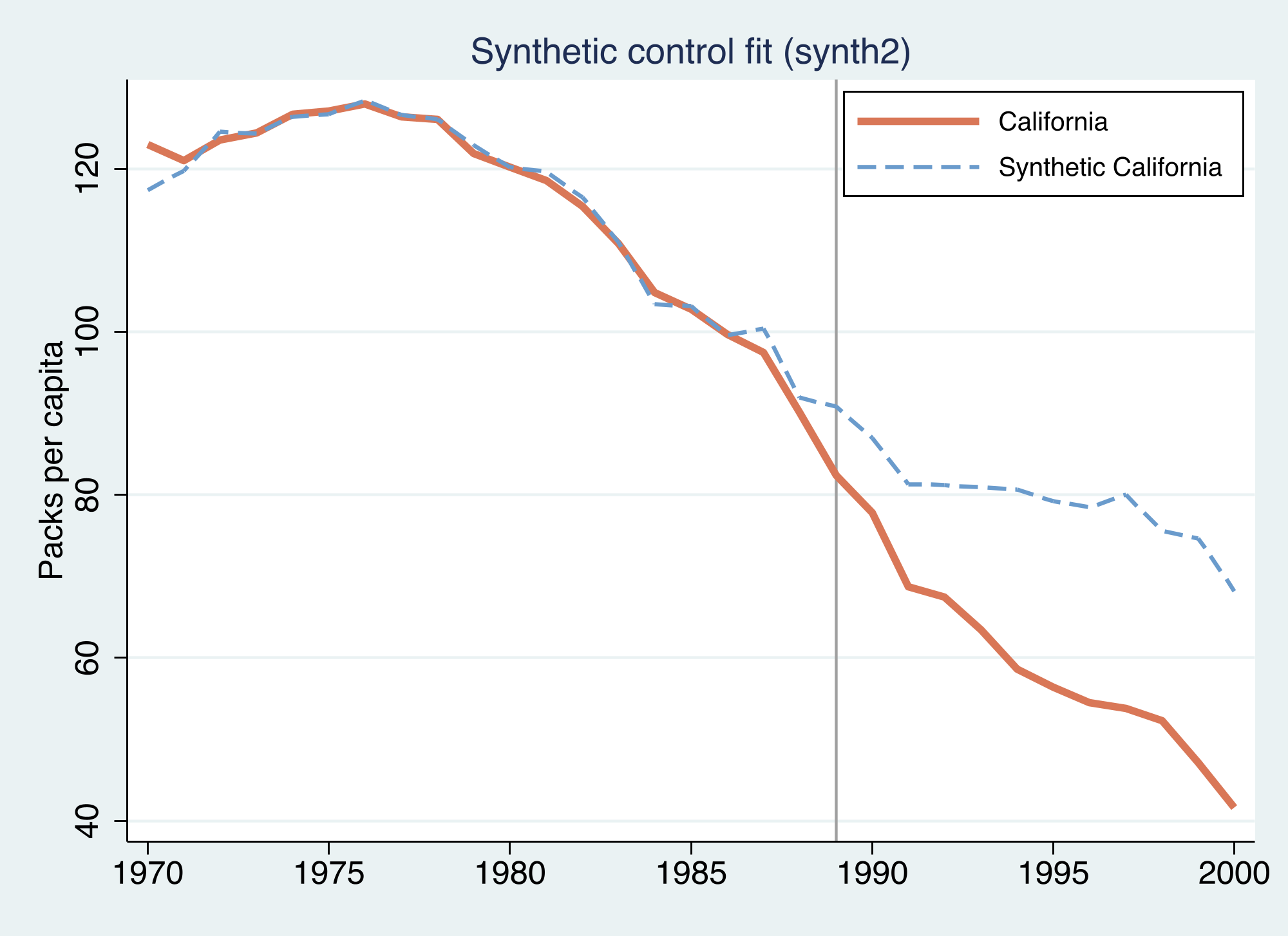
A weighted donor pool fits the pre-period almost perfectly — and shrinks the estimate to −19.48
Synthetic California (blue dashed) tracks real California (orange) almost perfectly before 1989, then the two separate sharply.
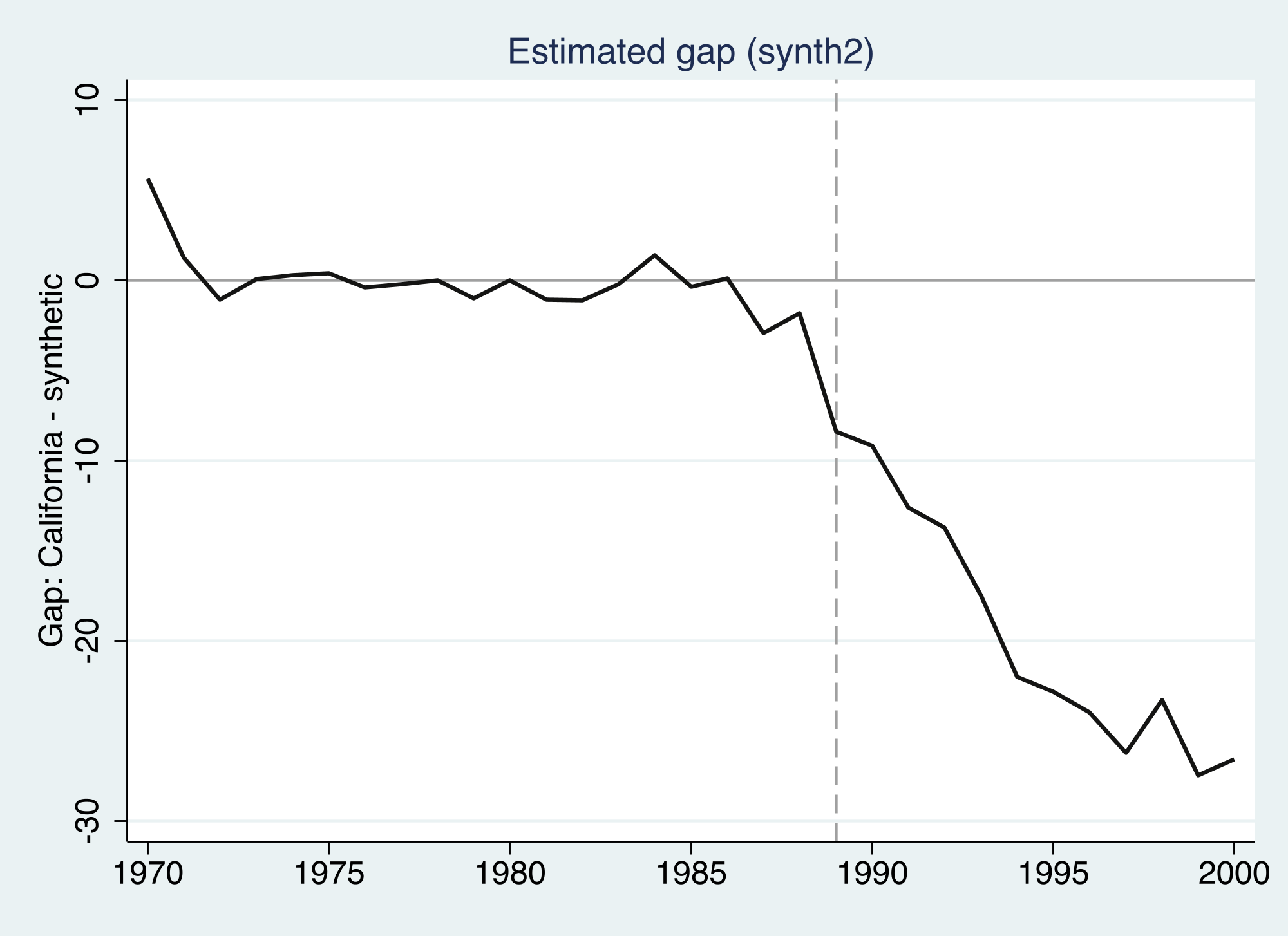
The gap hugs zero before 1989, then opens to about −27 by 2000
The estimated gap (California minus synthetic) is flat and near zero through 1988 — the pre-period fit is good — then falls steadily to roughly −27 packs by 2000.
SDID matches the trend, not the level — and lands at −15.60
The SDID diagnostic: California (red) versus the trend-matched synthetic (blue dashed), which sits above California by a roughly constant gap. The green ribbon shows the time weights, concentrated on 1986–1988.
SDID puts all its pre-period weight on 1986–1988
SDID’s pre-period time weights fall almost entirely on 1986, 1987, and 1988 (0.37, 0.21, 0.43); the earlier sixteen years get zero.
One command, three estimators — change only method()
sdid packspercapita state year treated, method(did) vce(noinference) graphsdid packspercapita state year treated, method(sc) vce(noinference) graphsdid packspercapita state year treated, method(sdid) vce(noinference) graph
method(did) returns −27.349 — identical to the hand-computed 2×2. method(sc) returns −19.620, essentially the standalone synth2’s −19.481. All three are special cases of one weighted regression.
Stacked side by side, the ranking is transparent: DiD −27, SC −19.5, SDID −15.6
Method
Command
ATT
Raw 2×2 DiD
reg y i.cal##i.post
−27.35
DiD (unified)
sdid …, method(did)
−27.35
Synthetic control
synth2 …
−19.48
SC (unified)
sdid …, method(sc)
−19.62
SDID
sdid …, method(sdid)
−15.60
The Resolution
Act III
SDID is the preferred single number: −15.60 packs, ~20% fewer cigarettes
−15.60
\(\hat{\tau}^{sdid}\), the ATT of Proposition 99 on California · matches Arkhangelsky et al. (2021)
With one treated unit, placebo is the only valid inference
Undefined or unreliable
Jackknife — deletes one unit at a time; deleting California leaves no treated unit
Bootstrap — needs the number of treated units to grow
The valid choice
Placebo — assign the treatment to a control state, re-estimate, repeat
the spread of placebo effects becomes the variance
The design forces the method: \(N_{tr}=1\) rules out jackknife and bootstrap, leaving the permutation procedure.
The placebo SE is 9.88 — honest about how hard one case is
9.88
placebo standard error · 95% CI [−35.0, 3.8] includes zero (\(p = 0.114\) by normal approximation)
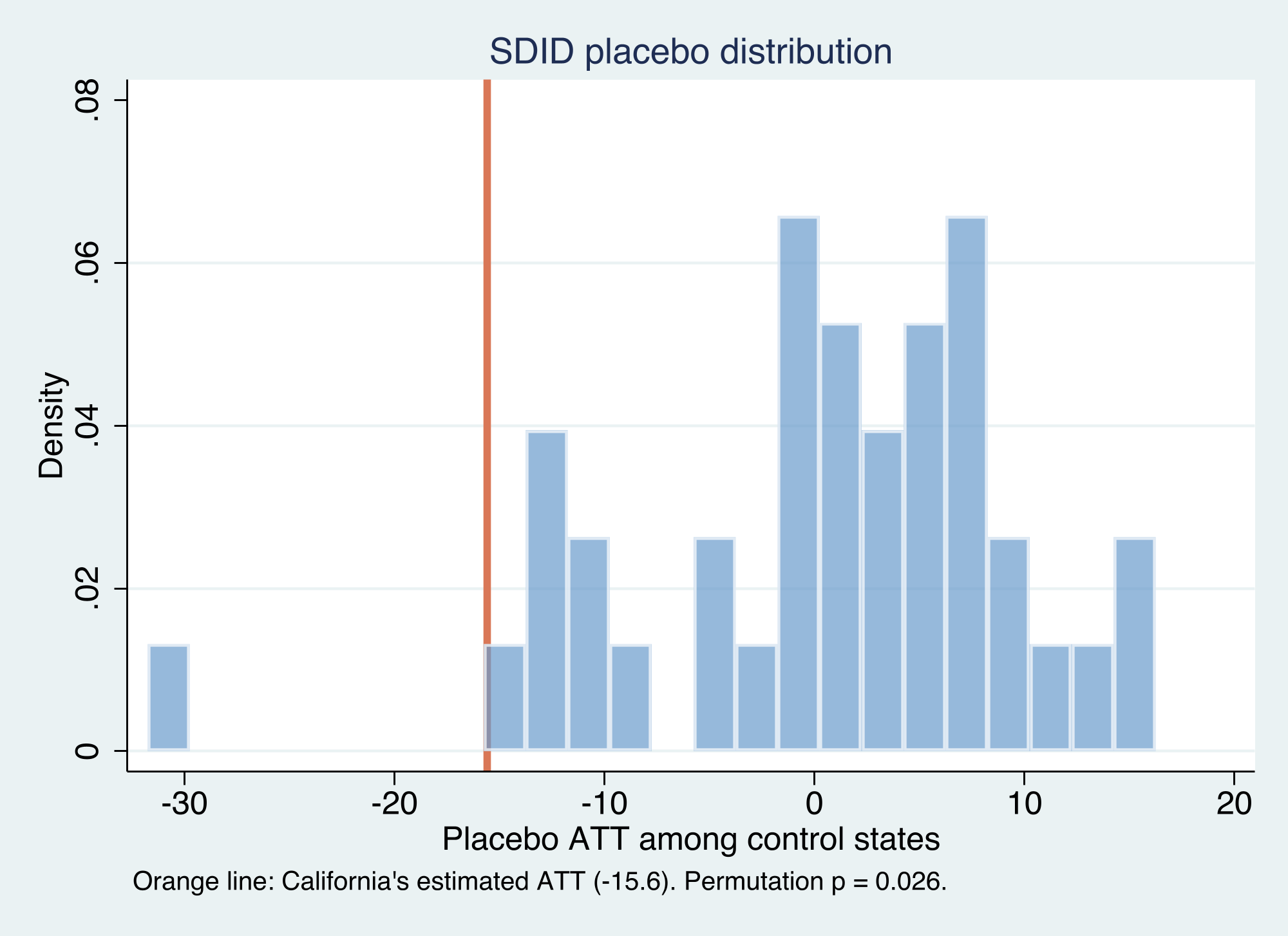
The permutation test ranks California extreme: only 1 of 38 placebos is as large, p = 0.026
California’s estimated effect (orange line, −15.6) sits in the extreme left tail of the placebo distribution; almost every control state shows an effect near zero.
The strongest objection — and the answer
Objection. SDID’s interval includes zero, so we cannot even be sure Proposition 99 did anything.
Response. The magnitude is imprecise, but the sign is robust: the permutation test (\(p = 0.026\)) ranks California’s drop far in the placebo tail, and all three estimators agree the effect is negative. Wide intervals are the honest price of one treated unit — not evidence of no effect.
Let the estimator that leans least on parallel trends choose your number.