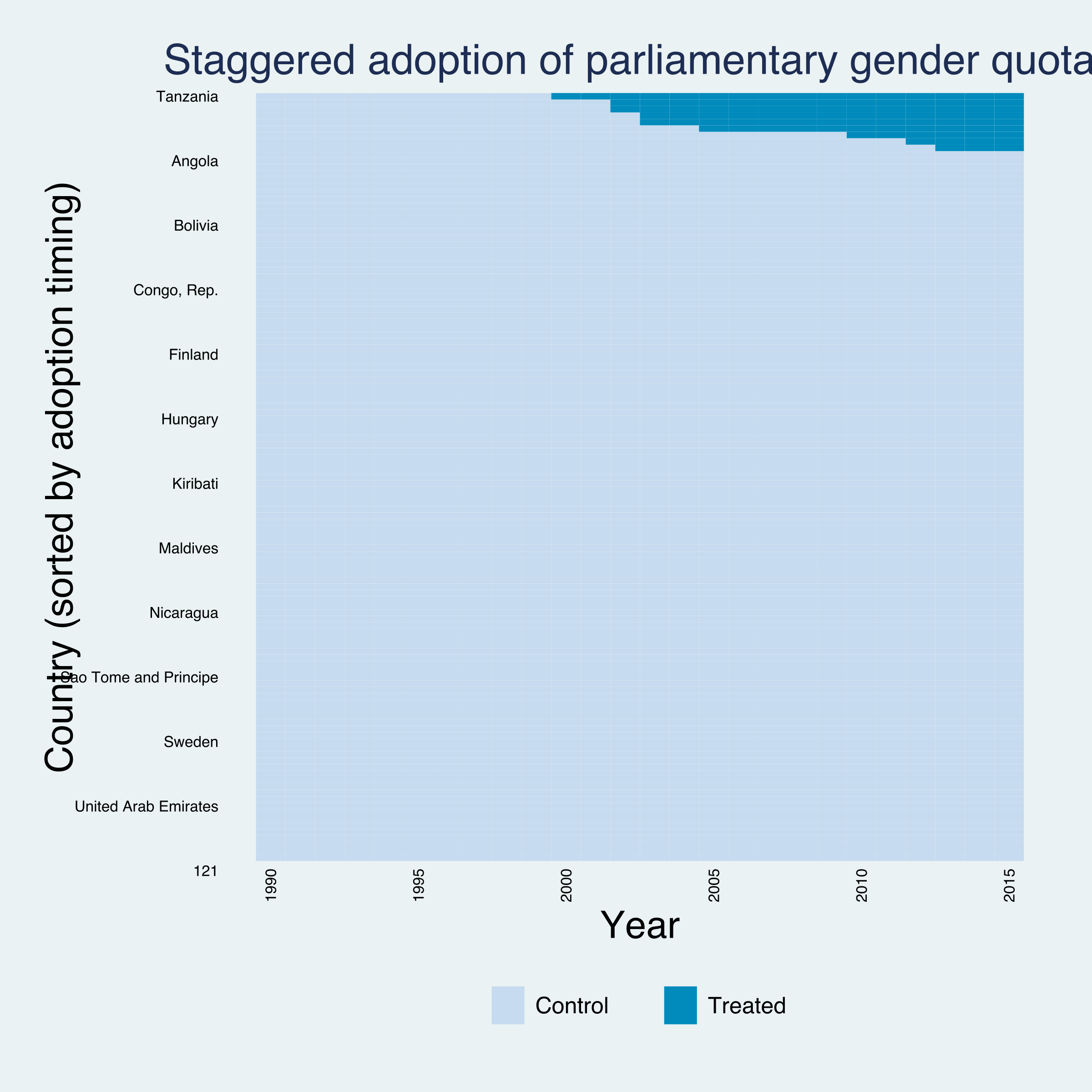
Quotas, minimum wages, carbon taxes — different units adopt in different years. Here: 9 countries adopt a parliamentary gender quota across 7 cohorts, 2000 to 2013.
The workhorse two-way fixed-effects DiD quietly breaks: it uses already-treated units as controls for later adopters. Which comparison is even valid?
Do gender quotas raise women’s share of parliament? +8 points — but it hides a wide range
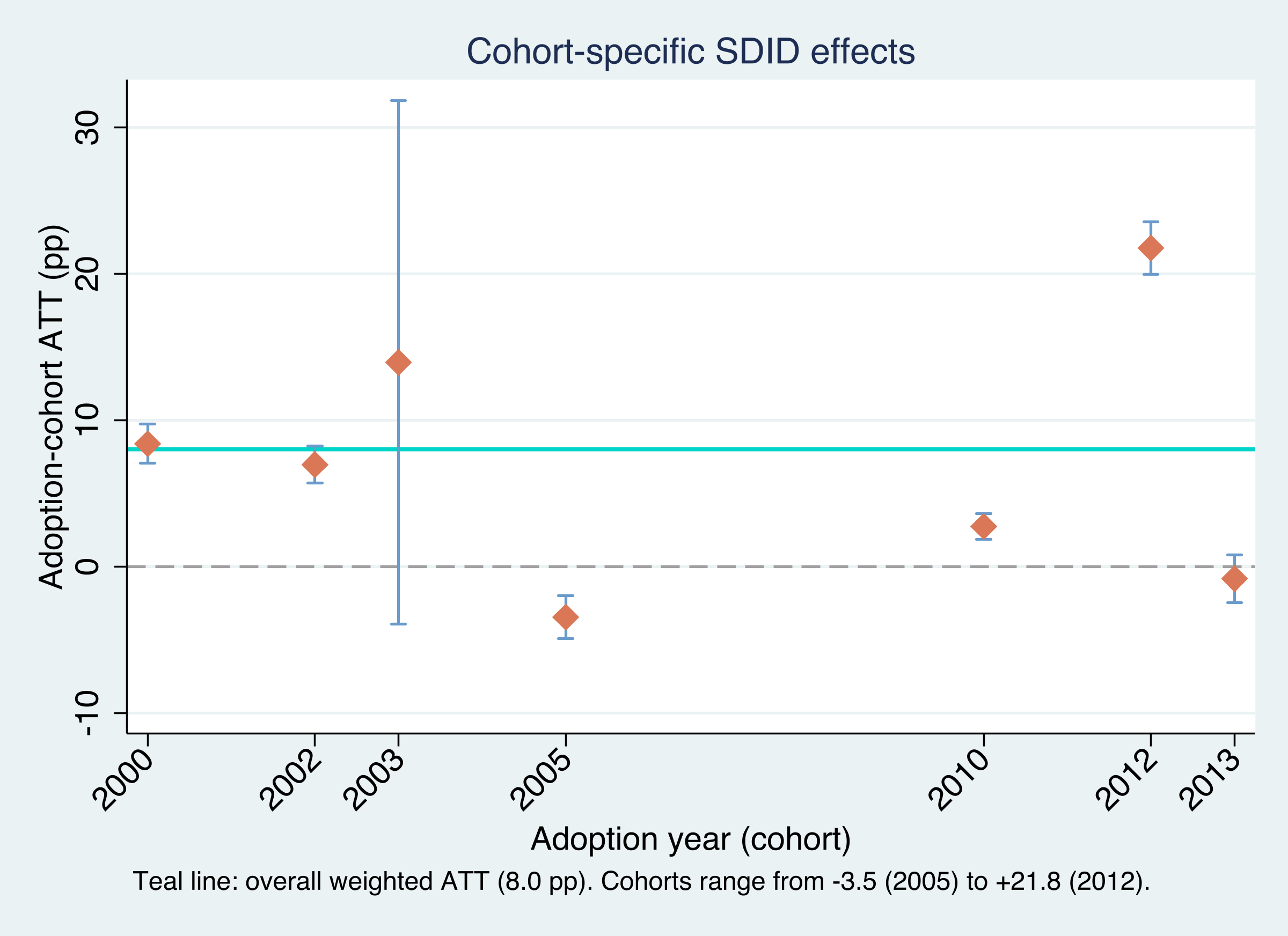
Cohort-specific SDID effects (\(\hat\tau_a \pm 95\%\) CI) with the aggregate ATT (teal). Effects swing from −3.5 to +21.8 points.
Where we’re going
The data: 119 countries, 1990–2015, a staggered staircase of adoptions
SDID from first principles — unit weights \(\omega\) and time weights \(\lambda\)
The staggered extension — one clean SDID per cohort, then aggregate
The event study, and three rulers for uncertainty
The Investigation
Act II
The lab: 119 countries × 26 years, 9 adopters across 7 cohorts
Outcome\(Y_{it}\) — % of seats held by women in parliament (mean ≈ 15%)
Treatment\(W_{it}\) — adopting a quota; absorbing (once on, stays on)
Donor pool — the 110 never-treated countries every synthetic control is built from
Balanced panel: \(119 \times 26 = 3{,}094\) observations. Treated country-years are scarce — only 3% of the panel.
The staircase: cohorts switch on one column at a time
Treatment-timing heatmap (panelview, sorted by adoption): treated cells form a staircase in the top-right, not one shared column.
The naive two-group picture is confounded — treated start below, then overtake
Mean women-in-parliament: ever-adopting (orange) start ≈ 4% in 1990 and finish above never-adopting (blue, ≈ 22%) by 2015.
SDID is a weighted two-way fixed-effects regression
The intercept \(\omega_0\) is the SDID twist: it lets the synthetic match the trend without matching the level — any level gap is absorbed by \(\alpha_i\). The ridge penalty \(\zeta^2\lVert\omega\rVert^2\) spreads weight across many donors.
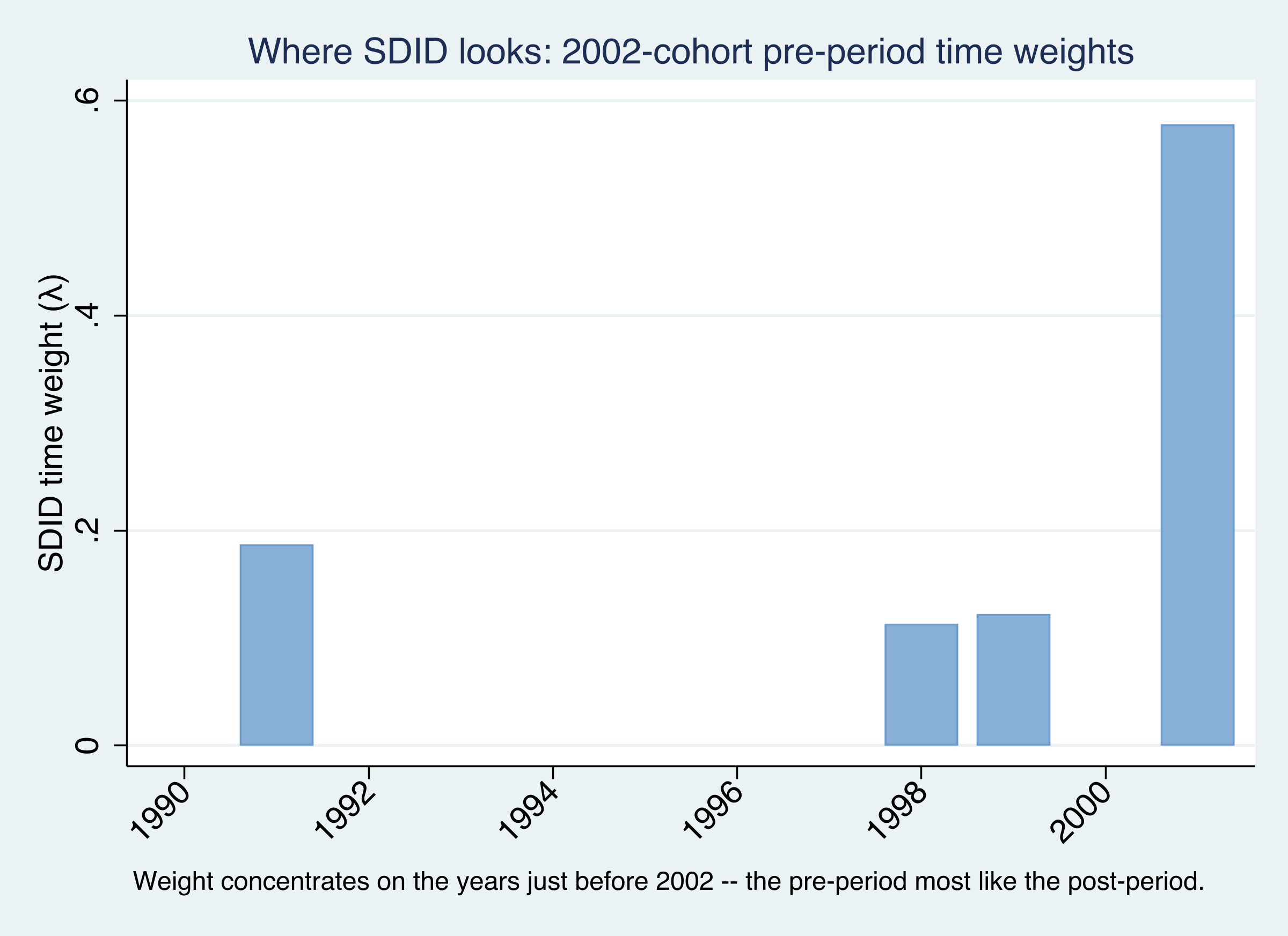
Time weights \(\lambda\) pick the “before” years most like the “after”
SDID time weights \(\hat\lambda_t\) for the 2002 cohort: weight concentrates on the late 1990s and 2001, not a flat average over 1990–2001.
Three cousins, one table: SDID optimizes both weight axes
Method
Unit \(\omega\)
Time \(\lambda\)
Unit FE \(\alpha_i\)
Must match
DiD
uniform
uniform
yes
trend on all controls
Synthetic control
optimized
uniform
no
level and trend
SDID
optimized
optimized
yes
trend (level gap allowed)
Optimizing both axes — and letting the unit FE absorb the level — is what distinguishes SDID.
Staggered SDID: do the single-cohort analysis once per cohort, then average
Per cohort \(a\)
take that cohort’s treated units + never-treated controls only
solve SDID → its own \(\hat\omega_a,\ \hat\lambda_a,\ \hat\tau_a\)
Why it’s safe
an already-treated unit is never a control for a later adopter
exactly the contamination that breaks naive TWFE
Estimand: the ATT under staggered timing — the effect on the units that actually adopted, averaged over their post-adoption years.
The overall ATT is a non-negative, treated-period-weighted average
A cohort counts in proportion to how many treated country-years it contributes.
The 2000 cohort (treated 16 years) carries more weight than the 2013 cohort (treated 3). Unlike TWFE, every weight is positive and interpretable.
One command runs the whole staggered procedure
sdid womparl country year quota, vce(bootstrap) seed(1213)matrixliste(tau) // the seven cohort effects* covariates(lngdp, optimized) | (lngdp, projected) to condition on income
Compared only to never-treated controls, quotas raise women’s share: ATT = +8.03
+8.03
overall ATT (points), SE 3.74, \(t=2.15\), \(p=0.032\) · 95% CI [0.70, 15.37] excludes zero
Behind the average: cohort effects swing from −3.5 to +21.8
Cohort
\(\hat\tau_a\) (pp)
SE
Agg. weight
2000
8.39
0.68
0.170
2002
6.97
0.64
0.298
2003
13.95
9.13
0.277
2005
−3.45
0.76
0.117
2012
+21.76
0.92
0.043
The aggregate 8.03 is the weighted average; the plain mean of the seven would be ≈ 7.0.
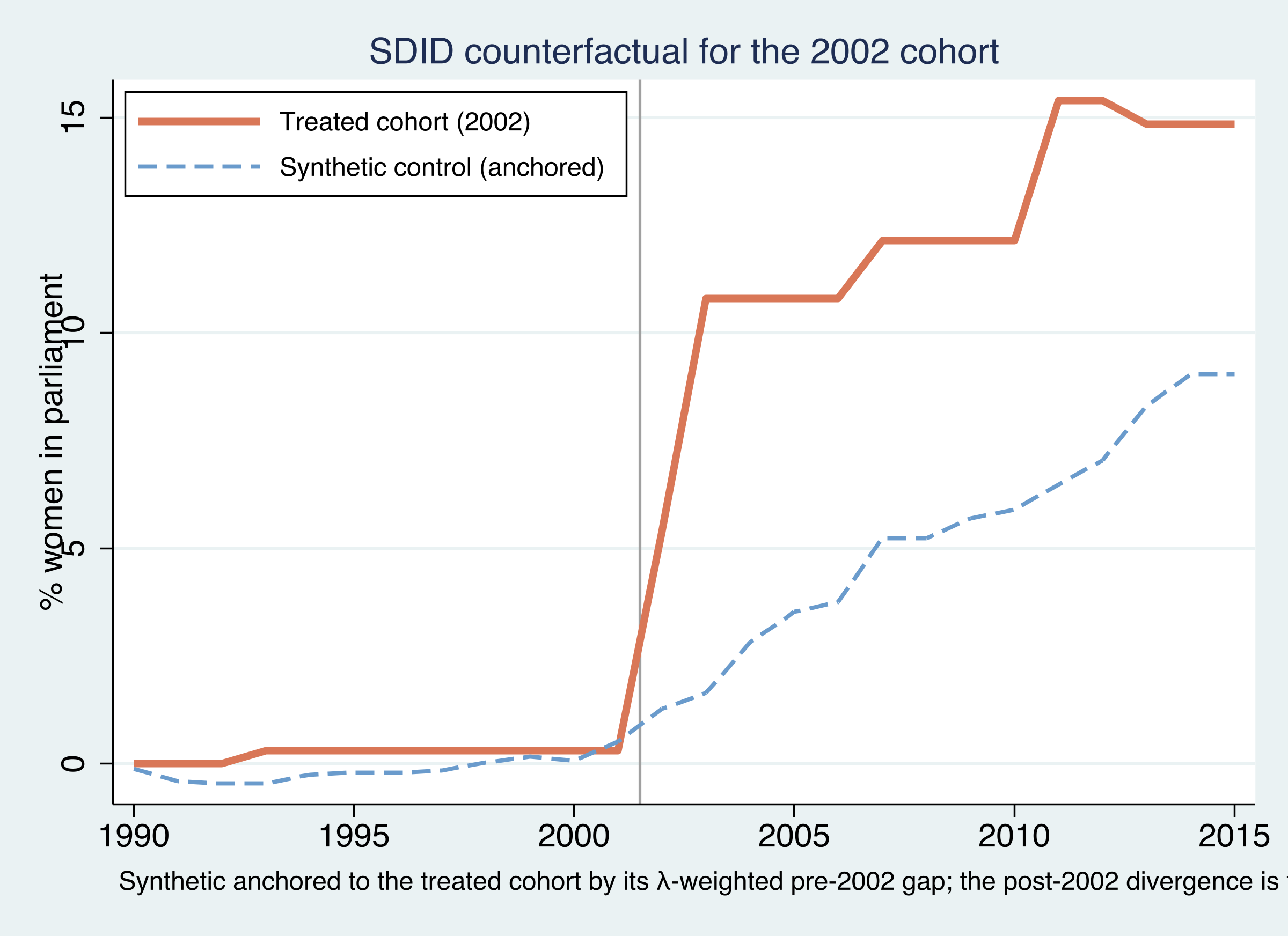
One cohort up close: treated and synthetic overlap before 2002, then diverge
The 2002 treated cohort (orange) vs its anchored synthetic control (blue dashed). They track pre-2002, then split — the gap is \(\hat\tau_{2002}=6.97\).
Controlling for income does not explain away the effect
Optimized (Arkhangelsky)
adjustment folded into the SDID optimization
ATT = 8.05, SE 3.05
Projected (Kranz)
residualize on untreated, then SDID
ATT = 8.06, SE 3.12
Both within 0.03 of the no-covariate 8.03 — the obvious confounder (richer countries) doesn’t account for it.
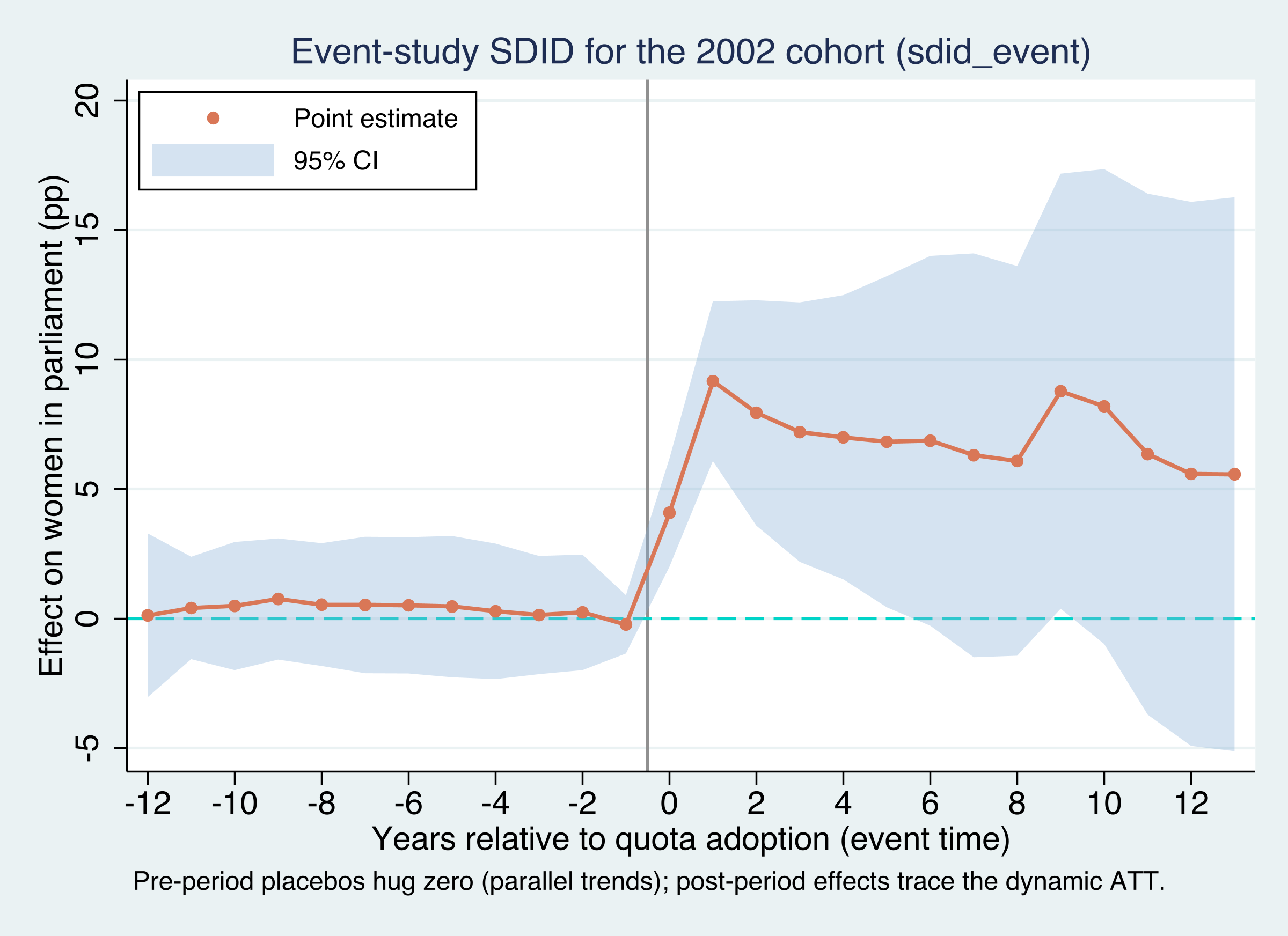
The event study: flat placebos before, an immediate and persistent rise after
sdid_event for the 2002 cohort. Left of zero = placebo (pre-trend) tests; right of zero = dynamic ATT. The baseline is \(\lambda\)-weighted, not “year −1.”
The treated-minus-synthetic gap at event time \(\ell\), net of the same gap at the \(\lambda\)-weighted baseline.
Pre-period \(\delta_\ell\) near zero is the parallel-trends placebo; post-period \(\delta_\ell > 0\) is the dynamic effect.
The Resolution
Act III
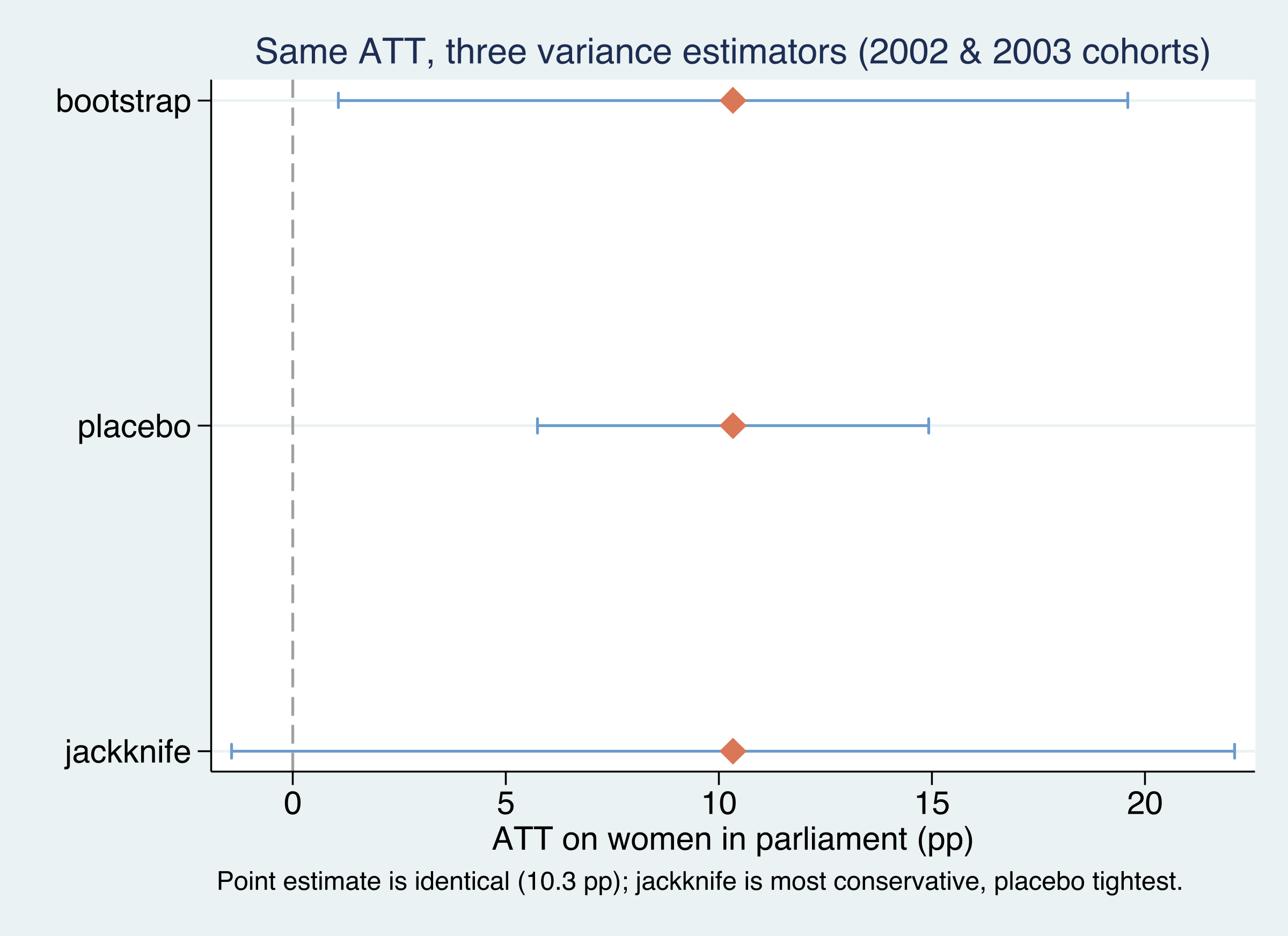
Nine treated units unlock three rulers — same estimate, different error bars
Same point estimate (10.33 on the 2002+2003 subsample), three variance estimators: jackknife widest (SE 6.01, CI crosses zero), placebo tightest (2.34), bootstrap between (4.73).
Report the bootstrap — but cross-check it when treated units are few
4.7 · 6.0 · 2.3
standard errors on one ATT of 10.33 — bootstrap · jackknife · placebo. A result “significant” under placebo but not jackknife deserves caution.
Does machine-built weighting make this causal? No — assumptions still carry the weight
Objection. Choosing controls and weights from the data can’t manufacture identification.
Response. Correct. The ATT is identified only under synthetic parallel trends per cohort, no anticipation, an absorbing treatment, and no cross-country spillovers. SDID disciplines selection and weighting; it can’t rule out timing that responds to the outcome. The flat event-study placebos support parallel trends — they cannot prove it.
A single headline number summarizes real heterogeneity — weight the cohorts transparently
−3.5 → +21.8
seven cohort effects behind one +8.03 ATT · non-negative, treated-period weighting is what makes the average honest under staggered timing
When policies arrive on different clocks, estimate each cohort cleanly — then weight, don’t average blindly.